 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToshiyuki Kumakura
SQ-VAE: Variational Bayes on Discrete Representation with Self-annealed Stochastic Quantization
May 16, 2022
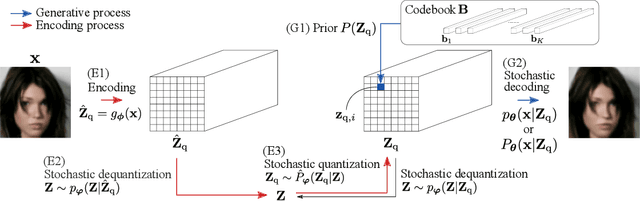

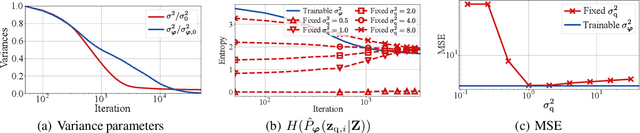
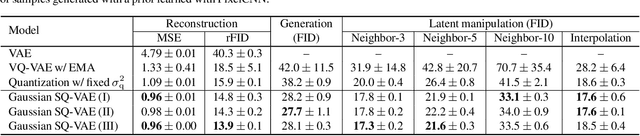
One noted issue of vector-quantized variational autoencoder (VQ-VAE) is that the learned discrete representation uses only a fraction of the full capacity of the codebook, also known as codebook collapse. We hypothesize that the training scheme of VQ-VAE, which involves some carefully designed heuristics, underlies this issue. In this paper, we propose a new training scheme that extends the standard VAE via novel stochastic dequantization and quantization, called stochastically quantized variational autoencoder (SQ-VAE). In SQ-VAE, we observe a trend that the quantization is stochastic at the initial stage of the training but gradually converges toward a deterministic quantization, which we call self-annealing. Our experiments show that SQ-VAE improves codebook utilization without using common heuristics. Furthermore, we empirically show that SQ-VAE is superior to VAE and VQ-VAE in vision- and speech-related tasks.
Polyphone disambiguation and accent prediction using pre-trained language models in Japanese TTS front-end
Jan 24, 2022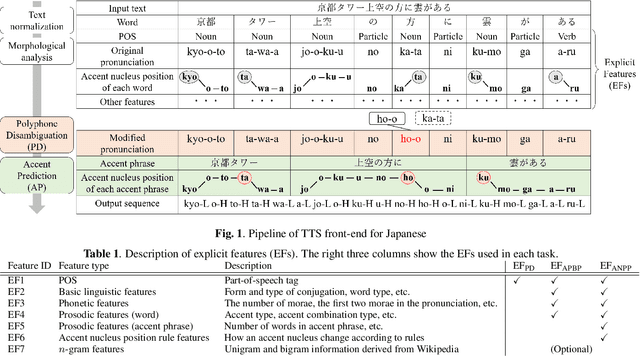



Although end-to-end text-to-speech (TTS) models can generate natural speech, challenges still remain when it comes to estimating sentence-level phonetic and prosodic information from raw text in Japanese TTS systems. In this paper, we propose a method for polyphone disambiguation (PD) and accent prediction (AP). The proposed method incorporates explicit features extracted from morphological analysis and implicit features extracted from pre-trained language models (PLMs). We use BERT and Flair embeddings as implicit features and examine how to combine them with explicit features. Our objective evaluation results showed that the proposed method improved the accuracy by 5.7 points in PD and 6.0 points in AP. Moreover, the perceptual listening test results confirmed that a TTS system employing our proposed model as a front-end achieved a mean opinion score close to that of synthesized speech with ground-truth pronunciation and accent in terms of naturalness.
Towards Online End-to-end Transformer Automatic Speech Recognition
Oct 25, 2019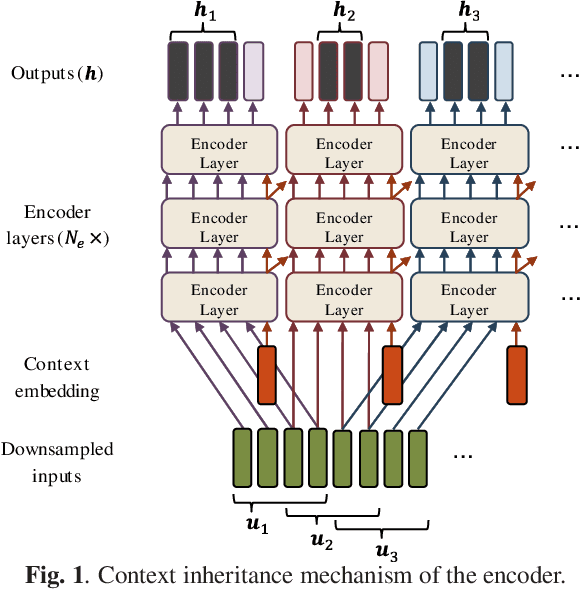
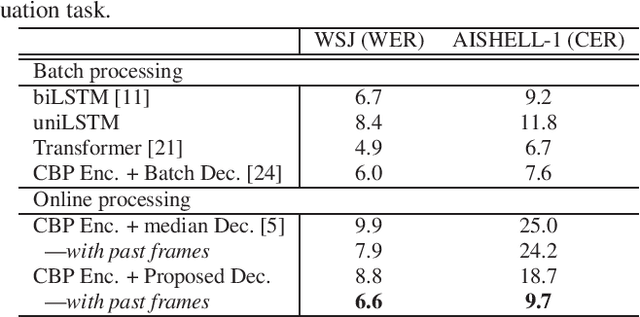
The Transformer self-attention network has recently shown promising performance as an alternative to recurrent neural networks in end-to-end (E2E) automatic speech recognition (ASR) systems. However, Transformer has a drawback in that the entire input sequence is required to compute self-attention. We have proposed a block processing method for the Transformer encoder by introducing a context-aware inheritance mechanism. An additional context embedding vector handed over from the previously processed block helps to encode not only local acoustic information but also global linguistic, channel, and speaker attributes. In this paper, we extend it towards an entire online E2E ASR system by introducing an online decoding process inspired by monotonic chunkwise attention (MoChA) into the Transformer decoder. Our novel MoChA training and inference algorithms exploit the unique properties of Transformer, whose attentions are not always monotonic or peaky, and have multiple heads and residual connections of the decoder layers. Evaluations of the Wall Street Journal (WSJ) and AISHELL-1 show that our proposed online Transformer decoder outperforms conventional chunkwise approaches.
Transformer ASR with Contextual Block Processing
Oct 16, 2019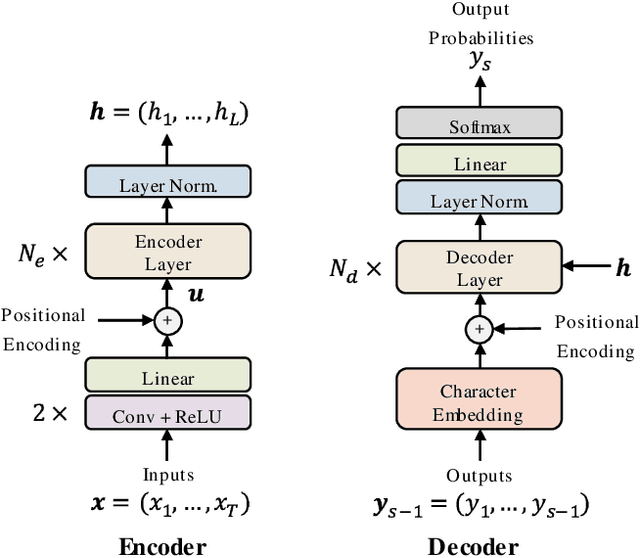
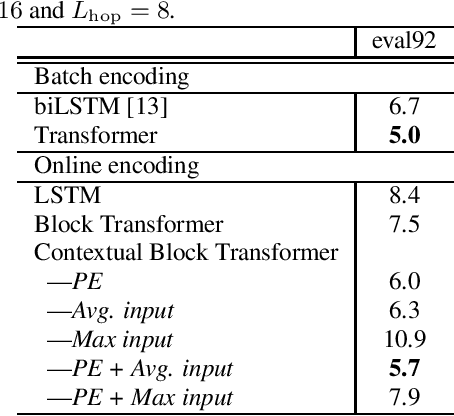
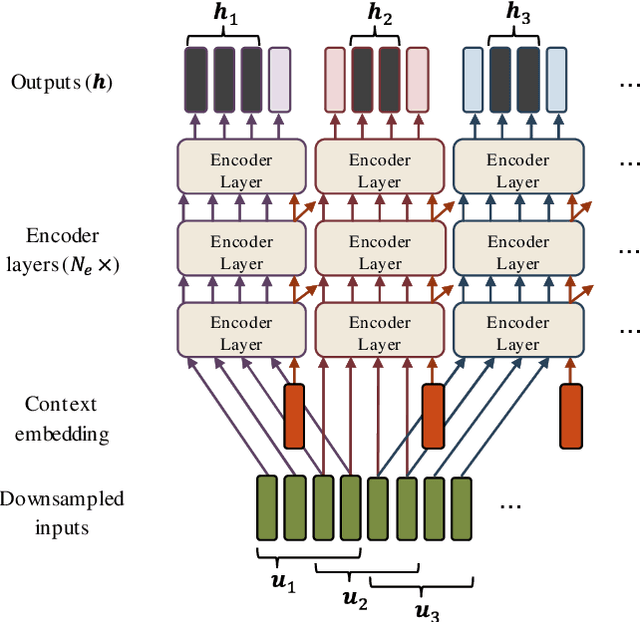
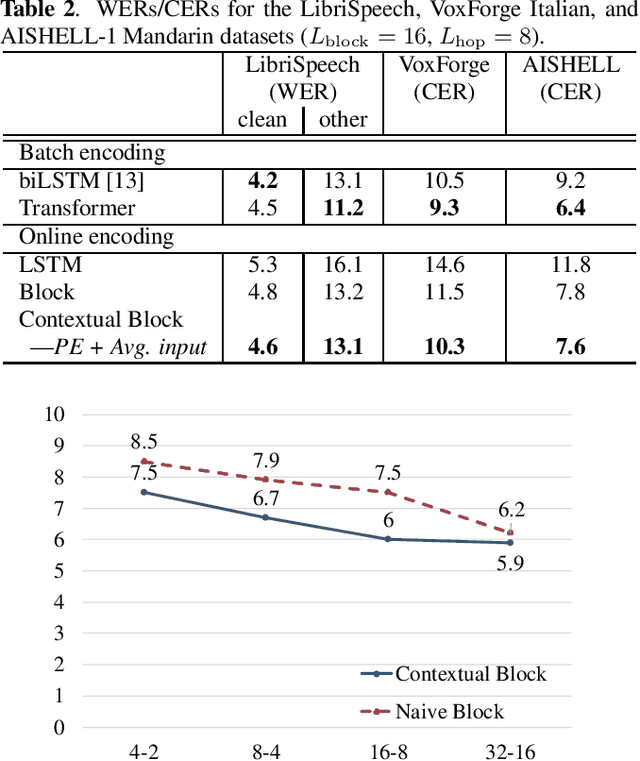
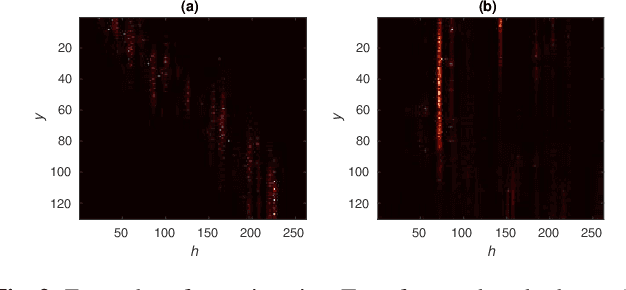
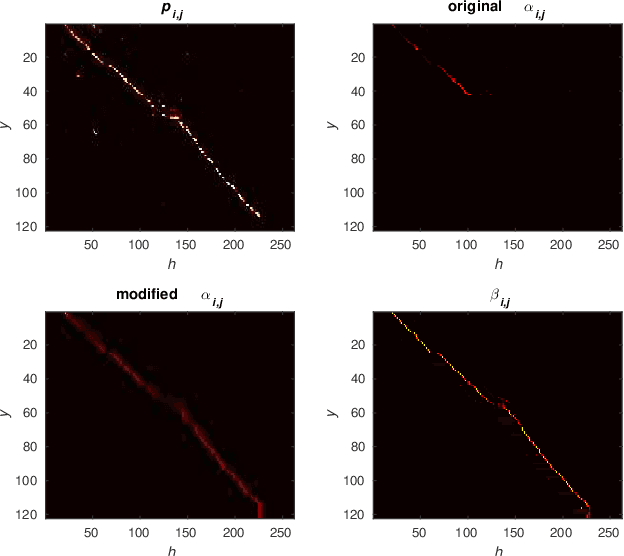
The Transformer self-attention network has recently shown promising performance as an alternative to recurrent neural networks (RNNs) in end-to-end (E2E) automatic speech recognition (ASR) systems. However, the Transformer has a drawback in that the entire input sequence is required to compute self-attention. In this paper, we propose a new block processing method for the Transformer encoder by introducing a context-aware inheritance mechanism. An additional context embedding vector handed over from the previously processed block helps to encode not only local acoustic information but also global linguistic, channel, and speaker attributes. We introduce a novel mask technique to implement the context inheritance to train the model efficiently. Evaluations of the Wall Street Journal (WSJ), Librispeech, VoxForge Italian, and AISHELL-1 Mandarin speech recognition datasets show that our proposed contextual block processing method outperforms naive block processing consistently. Furthermore, the attention weight tendency of each layer is analyzed to clarify how the added contextual inheritance mechanism models the global information.
End-to-end Adaptation with Backpropagation through WFST for On-device Speech Recognition System
May 17, 2019
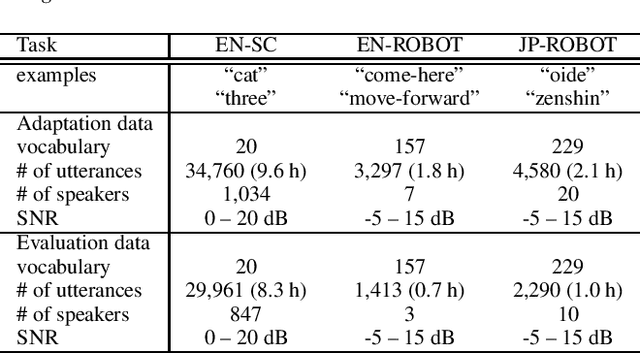
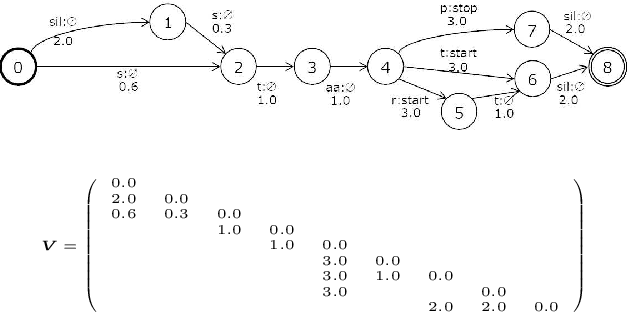
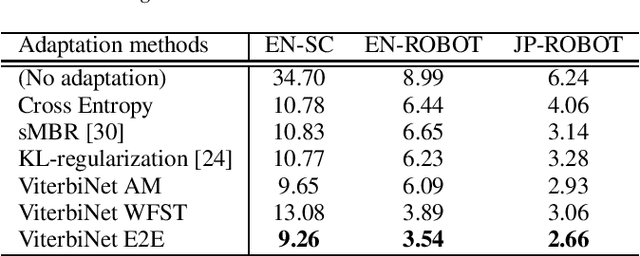
An on-device DNN-HMM speech recognition system efficiently works with a limited vocabulary in the presence of a variety of predictable noise. In such a case, vocabulary and environment adaptation is highly effective. In this paper, we propose a novel method of end-to-end (E2E) adaptation, which adjusts not only an acoustic model (AM) but also a weighted finite-state transducer (WFST). We convert a pretrained WFST to a trainable neural network and adapt the system to target environments/vocabulary by E2E joint training with an AM. We replicate Viterbi decoding with forward--backward neural network computation, which is similar to recurrent neural networks (RNNs). By pooling output score sequences, a vocabulary posterior for each utterance is obtained and used for discriminative loss computation. Experiments using 2--10 hours of English/Japanese adaptation datasets indicate that the fine-tuning of only WFSTs and that of only AMs are both comparable to a state-of-the-art adaptation method, and E2E joint training of the two components achieves the best recognition performance. We also adapt each language system to the other language using the adaptation data, and the results show that the proposed method also works well for language adaptations.