 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsui-Wei Weng
Provably Robust Conformal Prediction with Improved Efficiency
Apr 30, 2024
Conformal prediction is a powerful tool to generate uncertainty sets with guaranteed coverage using any predictive model, under the assumption that the training and test data are i.i.d.. Recently, it has been shown that adversarial examples are able to manipulate conformal methods to construct prediction sets with invalid coverage rates, as the i.i.d. assumption is violated. To address this issue, a recent work, Randomized Smoothed Conformal Prediction (RSCP), was first proposed to certify the robustness of conformal prediction methods to adversarial noise. However, RSCP has two major limitations: (i) its robustness guarantee is flawed when used in practice and (ii) it tends to produce large uncertainty sets. To address these limitations, we first propose a novel framework called RSCP+ to provide provable robustness guarantee in evaluation, which fixes the issues in the original RSCP method. Next, we propose two novel methods, Post-Training Transformation (PTT) and Robust Conformal Training (RCT), to effectively reduce prediction set size with little computation overhead. Experimental results in CIFAR10, CIFAR100, and ImageNet suggest the baseline method only yields trivial predictions including full label set, while our methods could boost the efficiency by up to $4.36\times$, $5.46\times$, and $16.9\times$ respectively and provide practical robustness guarantee. Our codes are available at https://github.com/Trustworthy-ML-Lab/Provably-Robust-Conformal-Prediction.
Describe-and-Dissect: Interpreting Neurons in Vision Networks with Language Models
Mar 20, 2024



In this paper, we propose Describe-and-Dissect (DnD), a novel method to describe the roles of hidden neurons in vision networks. DnD utilizes recent advancements in multimodal deep learning to produce complex natural language descriptions, without the need for labeled training data or a predefined set of concepts to choose from. Additionally, DnD is training-free, meaning we don't train any new models and can easily leverage more capable general purpose models in the future. We have conducted extensive qualitative and quantitative analysis to show that DnD outperforms prior work by providing higher quality neuron descriptions. Specifically, our method on average provides the highest quality labels and is more than 2 times as likely to be selected as the best explanation for a neuron than the best baseline.
One step closer to unbiased aleatoric uncertainty estimation
Dec 20, 2023Neural networks are powerful tools in various applications, and quantifying their uncertainty is crucial for reliable decision-making. In the deep learning field, the uncertainties are usually categorized into aleatoric (data) and epistemic (model) uncertainty. In this paper, we point out that the existing popular variance attenuation method highly overestimates aleatoric uncertainty. To address this issue, we propose a new estimation method by actively de-noising the observed data. By conducting a broad range of experiments, we demonstrate that our proposed approach provides a much closer approximation to the actual data uncertainty than the standard method.
Corrupting Neuron Explanations of Deep Visual Features
Oct 25, 2023



The inability of DNNs to explain their black-box behavior has led to a recent surge of explainability methods. However, there are growing concerns that these explainability methods are not robust and trustworthy. In this work, we perform the first robustness analysis of Neuron Explanation Methods under a unified pipeline and show that these explanations can be significantly corrupted by random noises and well-designed perturbations added to their probing data. We find that even adding small random noise with a standard deviation of 0.02 can already change the assigned concepts of up to 28% neurons in the deeper layers. Furthermore, we devise a novel corruption algorithm and show that our algorithm can manipulate the explanation of more than 80% neurons by poisoning less than 10% of probing data. This raises the concern of trusting Neuron Explanation Methods in real-life safety and fairness critical applications.
Promoting Robustness of Randomized Smoothing: Two Cost-Effective Approaches
Oct 11, 2023Randomized smoothing has recently attracted attentions in the field of adversarial robustness to provide provable robustness guarantees on smoothed neural network classifiers. However, existing works show that vanilla randomized smoothing usually does not provide good robustness performance and often requires (re)training techniques on the base classifier in order to boost the robustness of the resulting smoothed classifier. In this work, we propose two cost-effective approaches to boost the robustness of randomized smoothing while preserving its clean performance. The first approach introduces a new robust training method AdvMacerwhich combines adversarial training and robustness certification maximization for randomized smoothing. We show that AdvMacer can improve the robustness performance of randomized smoothing classifiers compared to SOTA baselines, while being 3x faster to train than MACER baseline. The second approach introduces a post-processing method EsbRS which greatly improves the robustness certificate based on building model ensembles. We explore different aspects of model ensembles that has not been studied by prior works and propose a novel design methodology to further improve robustness of the ensemble based on our theoretical analysis.
The Importance of Prompt Tuning for Automated Neuron Explanations
Oct 11, 2023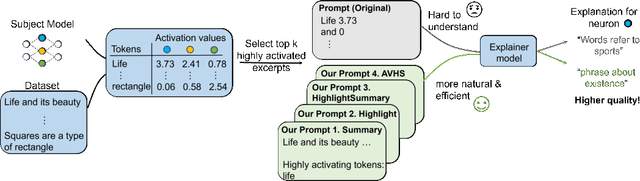
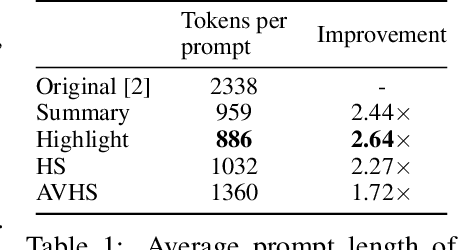
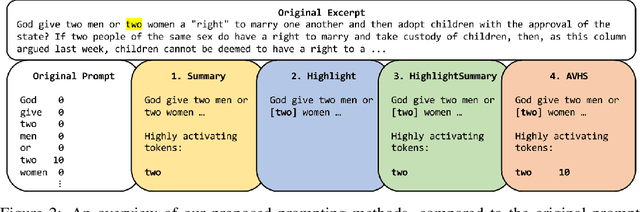
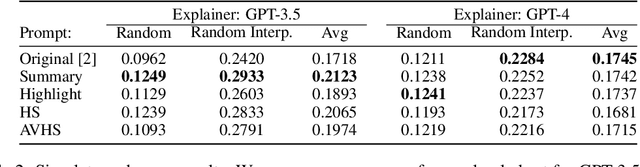
Recent advances have greatly increased the capabilities of large language models (LLMs), but our understanding of the models and their safety has not progressed as fast. In this paper we aim to understand LLMs deeper by studying their individual neurons. We build upon previous work showing large language models such as GPT-4 can be useful in explaining what each neuron in a language model does. Specifically, we analyze the effect of the prompt used to generate explanations and show that reformatting the explanation prompt in a more natural way can significantly improve neuron explanation quality and greatly reduce computational cost. We demonstrate the effects of our new prompts in three different ways, incorporating both automated and human evaluations.
Prediction without Preclusion: Recourse Verification with Reachable Sets
Aug 24, 2023



Machine learning models are often used to decide who will receive a loan, a job interview, or a public benefit. Standard techniques to build these models use features about people but overlook their actionability. In turn, models can assign predictions that are fixed, meaning that consumers who are denied loans, interviews, or benefits may be permanently locked out from access to credit, employment, or assistance. In this work, we introduce a formal testing procedure to flag models that assign fixed predictions that we call recourse verification. We develop machinery to reliably determine if a given model can provide recourse to its decision subjects from a set of user-specified actionability constraints. We demonstrate how our tools can ensure recourse and adversarial robustness in real-world datasets and use them to study the infeasibility of recourse in real-world lending datasets. Our results highlight how models can inadvertently assign fixed predictions that permanently bar access, and we provide tools to design algorithms that account for actionability when developing models.
Concept-Monitor: Understanding DNN training through individual neurons
Apr 26, 2023



In this work, we propose a general framework called Concept-Monitor to help demystify the black-box DNN training processes automatically using a novel unified embedding space and concept diversity metric. Concept-Monitor enables human-interpretable visualization and indicators of the DNN training processes and facilitates transparency as well as deeper understanding on how DNNs develop along the during training. Inspired by these findings, we also propose a new training regularizer that incentivizes hidden neurons to learn diverse concepts, which we show to improve training performance. Finally, we apply Concept-Monitor to conduct several case studies on different training paradigms including adversarial training, fine-tuning and network pruning via the Lottery Ticket Hypothesis
Label-Free Concept Bottleneck Models
Apr 12, 2023
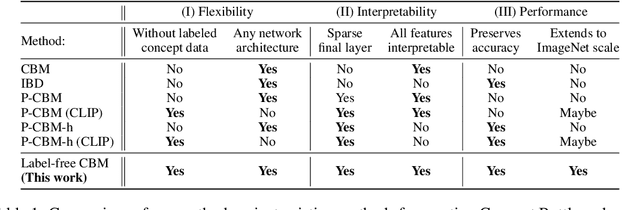
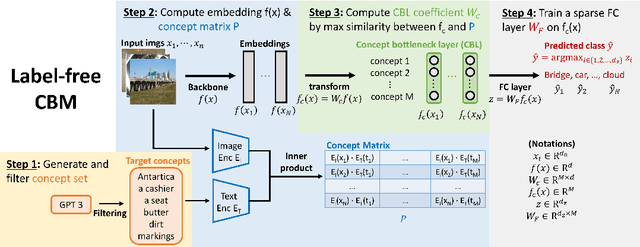

Concept bottleneck models (CBM) are a popular way of creating more interpretable neural networks by having hidden layer neurons correspond to human-understandable concepts. However, existing CBMs and their variants have two crucial limitations: first, they need to collect labeled data for each of the predefined concepts, which is time consuming and labor intensive; second, the accuracy of a CBM is often significantly lower than that of a standard neural network, especially on more complex datasets. This poor performance creates a barrier for adopting CBMs in practical real world applications. Motivated by these challenges, we propose Label-free CBM which is a novel framework to transform any neural network into an interpretable CBM without labeled concept data, while retaining a high accuracy. Our Label-free CBM has many advantages, it is: scalable - we present the first CBM scaled to ImageNet, efficient - creating a CBM takes only a few hours even for very large datasets, and automated - training it for a new dataset requires minimal human effort. Our code is available at https://github.com/Trustworthy-ML-Lab/Label-free-CBM.
Constructive Assimilation: Boosting Contrastive Learning Performance through View Generation Strategies
Apr 08, 2023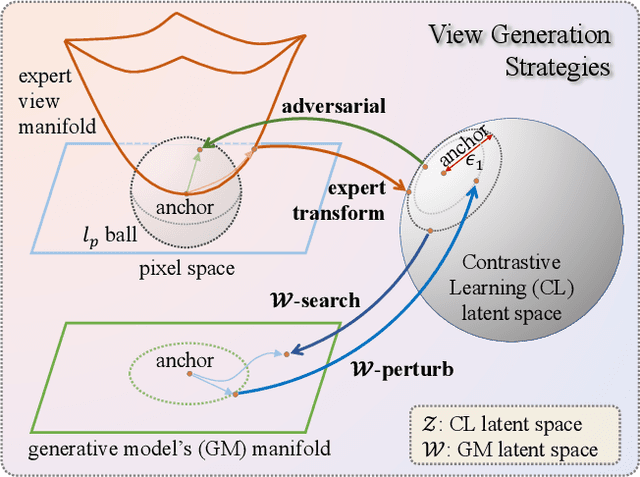
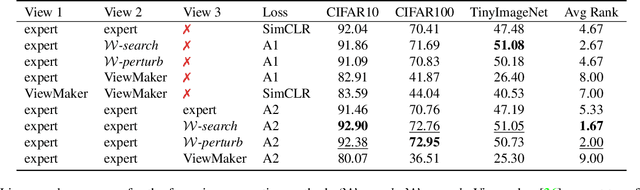
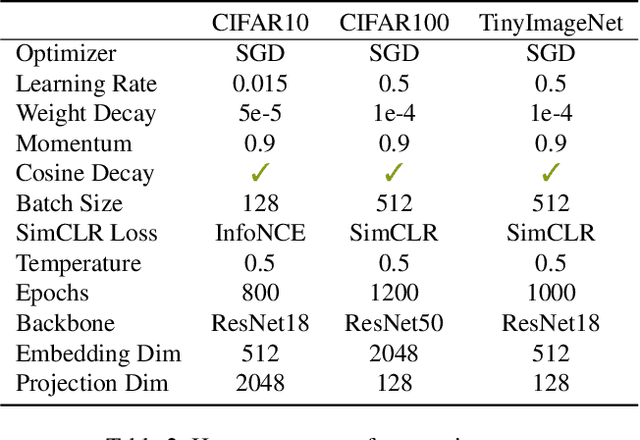
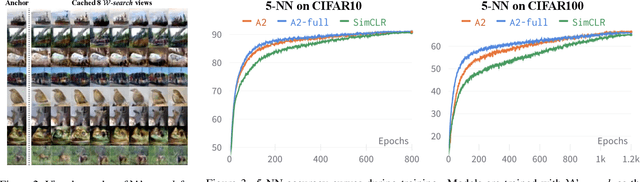
Transformations based on domain expertise (expert transformations), such as random-resized-crop and color-jitter, have proven critical to the success of contrastive learning techniques such as SimCLR. Recently, several attempts have been made to replace such domain-specific, human-designed transformations with generated views that are learned. However for imagery data, so far none of these view-generation methods has been able to outperform expert transformations. In this work, we tackle a different question: instead of replacing expert transformations with generated views, can we constructively assimilate generated views with expert transformations? We answer this question in the affirmative and propose a view generation method and a simple, effective assimilation method that together improve the state-of-the-art by up to ~3.6% on three different datasets. Importantly, we conduct a detailed empirical study that systematically analyzes a range of view generation and assimilation methods and provides a holistic picture of the efficacy of learned views in contrastive representation learning.