 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTycho F. A. van der Ouderaa
The LLM Surgeon
Dec 28, 2023
State-of-the-art language models are becoming increasingly large in an effort to achieve the highest performance on large corpora of available textual data. However, the sheer size of the Transformer architectures makes it difficult to deploy models within computational, environmental or device-specific constraints. We explore data-driven compression of existing pretrained models as an alternative to training smaller models from scratch. To do so, we scale Kronecker-factored curvature approximations of the target loss landscape to large language models. In doing so, we can compute both the dynamic allocation of structures that can be removed as well as updates of remaining weights that account for the removal. We provide a general framework for unstructured, semi-structured and structured pruning and improve upon weight updates to capture more correlations between weights, while remaining computationally efficient. Experimentally, our method can prune rows and columns from a range of OPT models and Llamav2-7B by 20%-30%, with a negligible loss in performance, and achieve state-of-the-art results in unstructured and semi-structured pruning of large language models.
Learning Layer-wise Equivariances Automatically using Gradients
Oct 09, 2023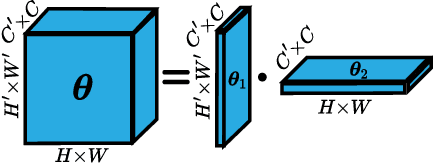

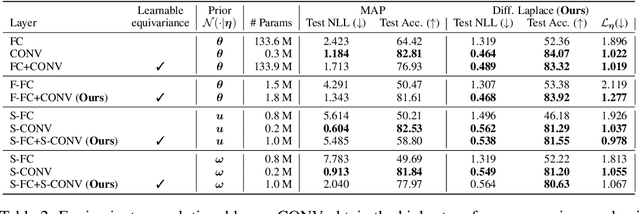

Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
Stochastic Marginal Likelihood Gradients using Neural Tangent Kernels
Jun 06, 2023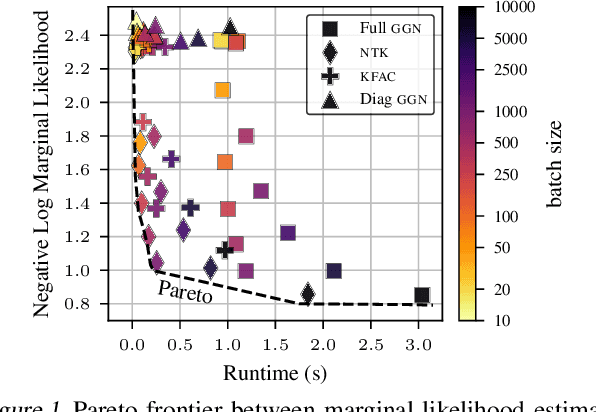
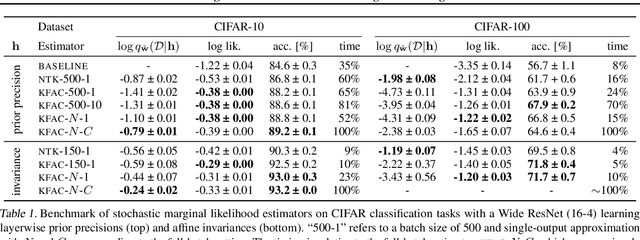
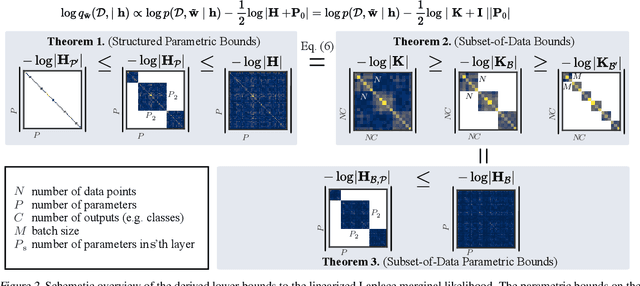
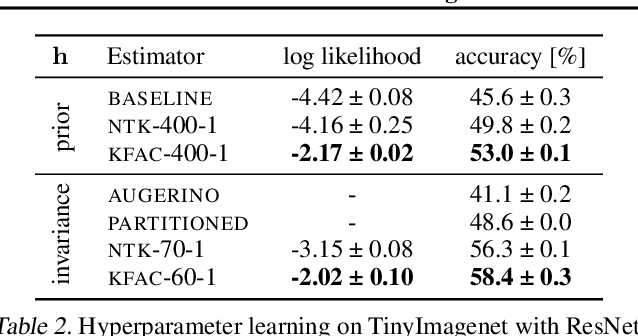
Selecting hyperparameters in deep learning greatly impacts its effectiveness but requires manual effort and expertise. Recent works show that Bayesian model selection with Laplace approximations can allow to optimize such hyperparameters just like standard neural network parameters using gradients and on the training data. However, estimating a single hyperparameter gradient requires a pass through the entire dataset, limiting the scalability of such algorithms. In this work, we overcome this issue by introducing lower bounds to the linearized Laplace approximation of the marginal likelihood. In contrast to previous estimators, these bounds are amenable to stochastic-gradient-based optimization and allow to trade off estimation accuracy against computational complexity. We derive them using the function-space form of the linearized Laplace, which can be estimated using the neural tangent kernel. Experimentally, we show that the estimators can significantly accelerate gradient-based hyperparameter optimization.
Relaxing Equivariance Constraints with Non-stationary Continuous Filters
Apr 14, 2022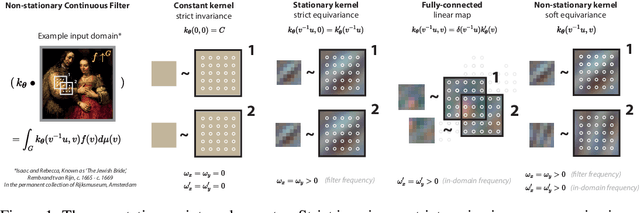
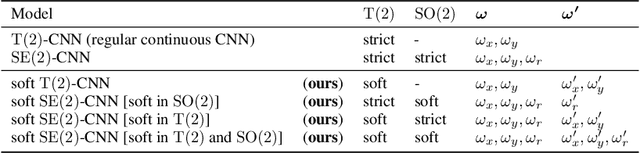
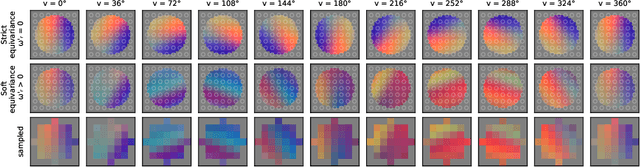
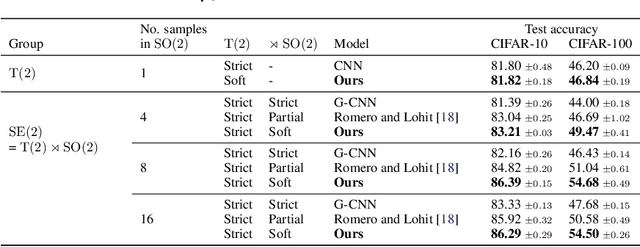
Equivariances provide useful inductive biases in neural network modeling, with the translation equivariance of convolutional neural networks being a canonical example. Equivariances can be embedded in architectures through weight-sharing and place symmetry constraints on the functions a neural network can represent. The type of symmetry is typically fixed and has to be chosen in advance. Although some tasks are inherently equivariant, many tasks do not strictly follow such symmetries. In such cases, equivariance constraints can be overly restrictive. In this work, we propose a parameter-efficient relaxation of equivariance that can effectively interpolate between a (i) non-equivariant linear product, (ii) a strict-equivariant convolution, and (iii) a strictly-invariant mapping. The proposed parameterization can be thought of as a building block to allow adjustable symmetry structure in neural networks. Compared to non-equivariant or strict-equivariant baselines, we experimentally verify that soft equivariance leads to improved performance in terms of test accuracy on CIFAR-10 and CIFAR-100 image classification tasks.
Learning Invariant Weights in Neural Networks
Feb 25, 2022
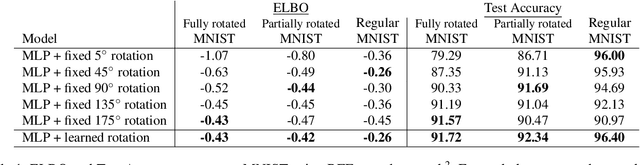
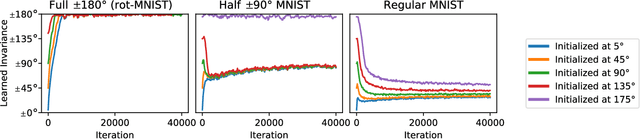
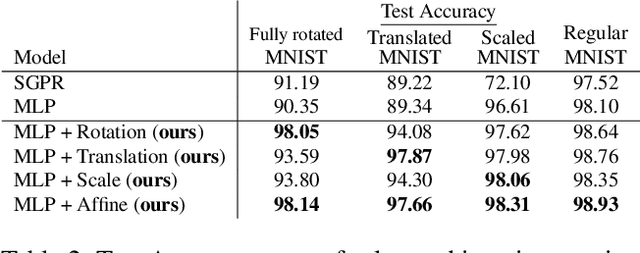
Assumptions about invariances or symmetries in data can significantly increase the predictive power of statistical models. Many commonly used models in machine learning are constraint to respect certain symmetries in the data, such as translation equivariance in convolutional neural networks, and incorporation of new symmetry types is actively being studied. Yet, efforts to learn such invariances from the data itself remains an open research problem. It has been shown that marginal likelihood offers a principled way to learn invariances in Gaussian Processes. We propose a weight-space equivalent to this approach, by minimizing a lower bound on the marginal likelihood to learn invariances in neural networks resulting in naturally higher performing models.
Invariance Learning in Deep Neural Networks with Differentiable Laplace Approximations
Feb 22, 2022
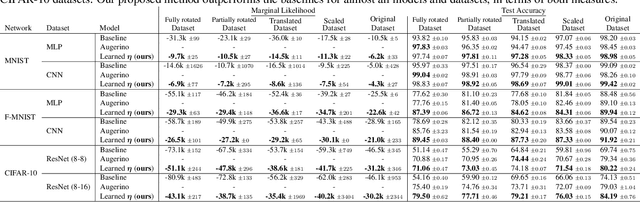


Data augmentation is commonly applied to improve performance of deep learning by enforcing the knowledge that certain transformations on the input preserve the output. Currently, the correct data augmentation is chosen by human effort and costly cross-validation, which makes it cumbersome to apply to new datasets. We develop a convenient gradient-based method for selecting the data augmentation. Our approach relies on phrasing data augmentation as an invariance in the prior distribution and learning it using Bayesian model selection, which has been shown to work in Gaussian processes, but not yet for deep neural networks. We use a differentiable Kronecker-factored Laplace approximation to the marginal likelihood as our objective, which can be optimised without human supervision or validation data. We show that our method can successfully recover invariances present in the data, and that this improves generalisation on image datasets.
Deep Group-wise Variational Diffeomorphic Image Registration
Oct 01, 2020

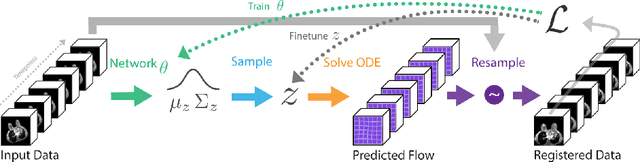
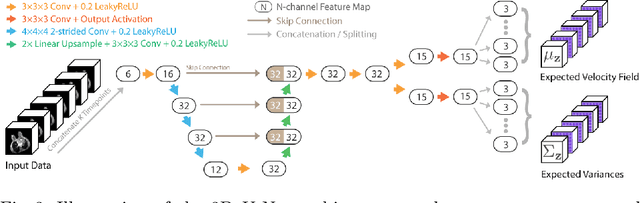
Deep neural networks are increasingly used for pair-wise image registration. We propose to extend current learning-based image registration to allow simultaneous registration of multiple images. To achieve this, we build upon the pair-wise variational and diffeomorphic VoxelMorph approach and present a general mathematical framework that enables both registration of multiple images to their geodesic average and registration in which any of the available images can be used as a fixed image. In addition, we provide a likelihood based on normalized mutual information, a well-known image similarity metric in registration, between multiple images, and a prior that allows for explicit control over the viscous fluid energy to effectively regularize deformations. We trained and evaluated our approach using intra-patient registration of breast MRI and Thoracic 4DCT exams acquired over multiple time points. Comparison with Elastix and VoxelMorph demonstrates competitive quantitative performance of the proposed method in terms of image similarity and reference landmark distances at significantly faster registration.
Reversible GANs for Memory-efficient Image-to-Image Translation
Feb 07, 2019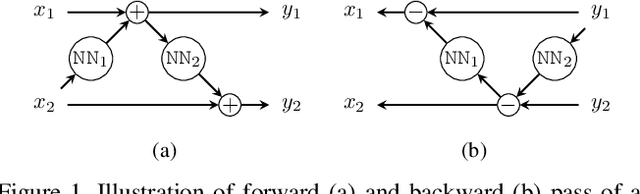

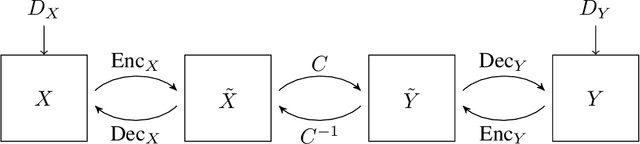

The Pix2pix and CycleGAN losses have vastly improved the qualitative and quantitative visual quality of results in image-to-image translation tasks. We extend this framework by exploring approximately invertible architectures which are well suited to these losses. These architectures are approximately invertible by design and thus partially satisfy cycle-consistency before training even begins. Furthermore, since invertible architectures have constant memory complexity in depth, these models can be built arbitrarily deep. We are able to demonstrate superior quantitative output on the Cityscapes and Maps datasets at near constant memory budget.