 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrsula Schmidt-Erfurth
Spatiotemporal Representation Learning for Short and Long Medical Image Time Series
Mar 12, 2024
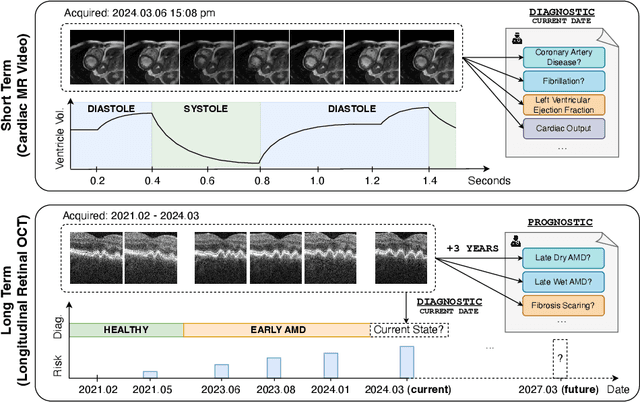
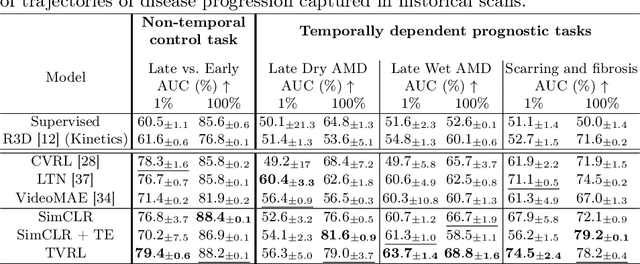
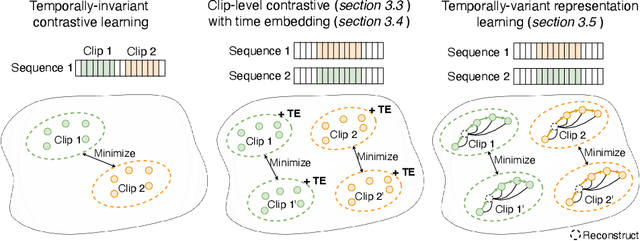
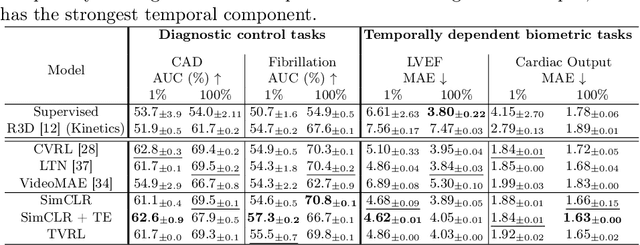
Analyzing temporal developments is crucial for the accurate prognosis of many medical conditions. Temporal changes that occur over short time scales are key to assessing the health of physiological functions, such as the cardiac cycle. Moreover, tracking longer term developments that occur over months or years in evolving processes, such as age-related macular degeneration (AMD), is essential for accurate prognosis. Despite the importance of both short and long term analysis to clinical decision making, they remain understudied in medical deep learning. State of the art methods for spatiotemporal representation learning, developed for short natural videos, prioritize the detection of temporal constants rather than temporal developments. Moreover, they do not account for varying time intervals between acquisitions, which are essential for contextualizing observed changes. To address these issues, we propose two approaches. First, we combine clip-level contrastive learning with a novel temporal embedding to adapt to irregular time series. Second, we propose masking and predicting latent frame representations of the temporal sequence. Our two approaches outperform all prior methods on temporally-dependent tasks including cardiac output estimation and three prognostic AMD tasks. Overall, this enables the automated analysis of temporal patterns which are typically overlooked in applications of deep learning to medicine.
Deep Multimodal Fusion of Data with Heterogeneous Dimensionality via Projective Networks
Feb 02, 2024The use of multimodal imaging has led to significant improvements in the diagnosis and treatment of many diseases. Similar to clinical practice, some works have demonstrated the benefits of multimodal fusion for automatic segmentation and classification using deep learning-based methods. However, current segmentation methods are limited to fusion of modalities with the same dimensionality (e.g., 3D+3D, 2D+2D), which is not always possible, and the fusion strategies implemented by classification methods are incompatible with localization tasks. In this work, we propose a novel deep learning-based framework for the fusion of multimodal data with heterogeneous dimensionality (e.g., 3D+2D) that is compatible with localization tasks. The proposed framework extracts the features of the different modalities and projects them into the common feature subspace. The projected features are then fused and further processed to obtain the final prediction. The framework was validated on the following tasks: segmentation of geographic atrophy (GA), a late-stage manifestation of age-related macular degeneration, and segmentation of retinal blood vessels (RBV) in multimodal retinal imaging. Our results show that the proposed method outperforms the state-of-the-art monomodal methods on GA and RBV segmentation by up to 3.10% and 4.64% Dice, respectively.
3DTINC: Time-Equivariant Non-Contrastive Learning for Predicting Disease Progression from Longitudinal OCTs
Dec 28, 2023Self-supervised learning (SSL) has emerged as a powerful technique for improving the efficiency and effectiveness of deep learning models. Contrastive methods are a prominent family of SSL that extract similar representations of two augmented views of an image while pushing away others in the representation space as negatives. However, the state-of-the-art contrastive methods require large batch sizes and augmentations designed for natural images that are impractical for 3D medical images. To address these limitations, we propose a new longitudinal SSL method, 3DTINC, based on non-contrastive learning. It is designed to learn perturbation-invariant features for 3D optical coherence tomography (OCT) volumes, using augmentations specifically designed for OCT. We introduce a new non-contrastive similarity loss term that learns temporal information implicitly from intra-patient scans acquired at different times. Our experiments show that this temporal information is crucial for predicting progression of retinal diseases, such as age-related macular degeneration (AMD). After pretraining with 3DTINC, we evaluated the learned representations and the prognostic models on two large-scale longitudinal datasets of retinal OCTs where we predict the conversion to wet-AMD within a six months interval. Our results demonstrate that each component of our contributions is crucial for learning meaningful representations useful in predicting disease progression from longitudinal volumetric scans.
Pretrained Deep 2.5D Models for Efficient Predictive Modeling from Retinal OCT
Jul 25, 2023In the field of medical imaging, 3D deep learning models play a crucial role in building powerful predictive models of disease progression. However, the size of these models presents significant challenges, both in terms of computational resources and data requirements. Moreover, achieving high-quality pretraining of 3D models proves to be even more challenging. To address these issues, hybrid 2.5D approaches provide an effective solution for utilizing 3D volumetric data efficiently using 2D models. Combining 2D and 3D techniques offers a promising avenue for optimizing performance while minimizing memory requirements. In this paper, we explore 2.5D architectures based on a combination of convolutional neural networks (CNNs), long short-term memory (LSTM), and Transformers. In addition, leveraging the benefits of recent non-contrastive pretraining approaches in 2D, we enhanced the performance and data efficiency of 2.5D techniques even further. We demonstrate the effectiveness of architectures and associated pretraining on a task of predicting progression to wet age-related macular degeneration (AMD) within a six-month period on two large longitudinal OCT datasets.
Transformer-based end-to-end classification of variable-length volumetric data
Jul 21, 2023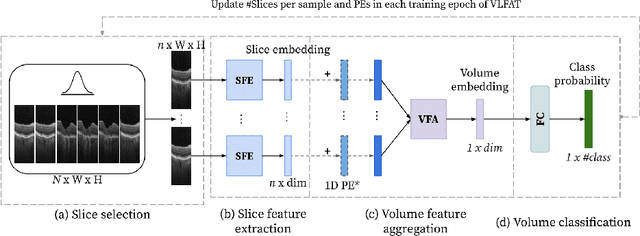
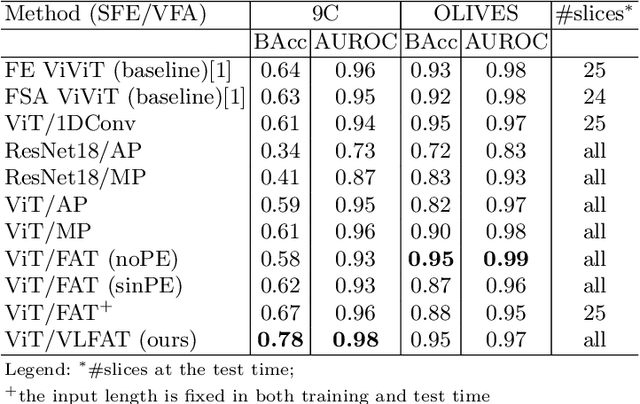
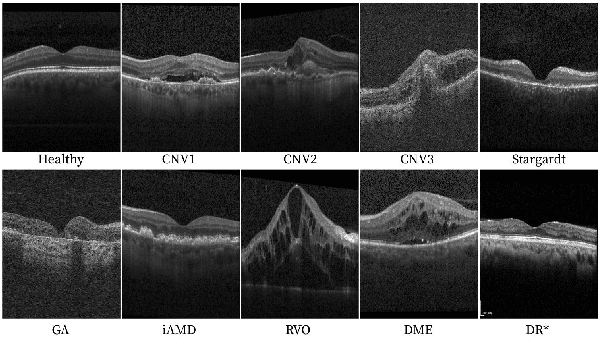
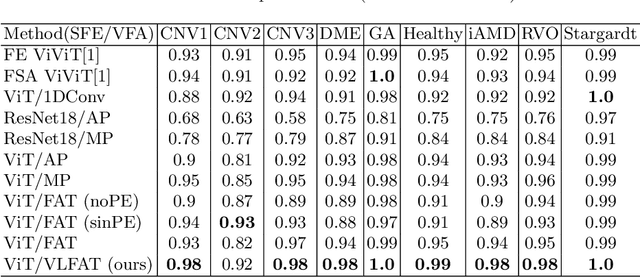
The automatic classification of 3D medical data is memory-intensive. Also, variations in the number of slices between samples is common. Na\"ive solutions such as subsampling can solve these problems, but at the cost of potentially eliminating relevant diagnosis information. Transformers have shown promising performance for sequential data analysis. However, their application for long sequences is data, computationally, and memory demanding. In this paper, we propose an end-to-end Transformer-based framework that allows to classify volumetric data of variable length in an efficient fashion. Particularly, by randomizing the input volume-wise resolution(#slices) during training, we enhance the capacity of the learnable positional embedding assigned to each volume slice. Consequently, the accumulated positional information in each positional embedding can be generalized to the neighbouring slices, even for high-resolution volumes at the test time. By doing so, the model will be more robust to variable volume length and amenable to different computational budgets. We evaluated the proposed approach in retinal OCT volume classification and achieved 21.96% average improvement in balanced accuracy on a 9-class diagnostic task, compared to state-of-the-art video transformers. Our findings show that varying the volume-wise resolution of the input during training results in more informative volume representation as compared to training with fixed number of slices per volume.
Self-supervised learning via inter-modal reconstruction and feature projection networks for label-efficient 3D-to-2D segmentation
Jul 13, 2023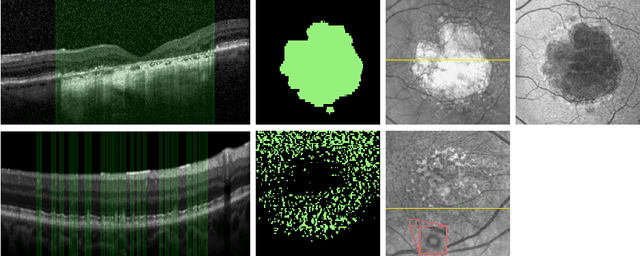

Deep learning has become a valuable tool for the automation of certain medical image segmentation tasks, significantly relieving the workload of medical specialists. Some of these tasks require segmentation to be performed on a subset of the input dimensions, the most common case being 3D-to-2D. However, the performance of existing methods is strongly conditioned by the amount of labeled data available, as there is currently no data efficient method, e.g. transfer learning, that has been validated on these tasks. In this work, we propose a novel convolutional neural network (CNN) and self-supervised learning (SSL) method for label-efficient 3D-to-2D segmentation. The CNN is composed of a 3D encoder and a 2D decoder connected by novel 3D-to-2D blocks. The SSL method consists of reconstructing image pairs of modalities with different dimensionality. The approach has been validated in two tasks with clinical relevance: the en-face segmentation of geographic atrophy and reticular pseudodrusen in optical coherence tomography. Results on different datasets demonstrate that the proposed CNN significantly improves the state of the art in scenarios with limited labeled data by up to 8% in Dice score. Moreover, the proposed SSL method allows further improvement of this performance by up to 23%, and we show that the SSL is beneficial regardless of the network architecture.
Morph-SSL: Self-Supervision with Longitudinal Morphing to Predict AMD Progression from OCT
Apr 17, 2023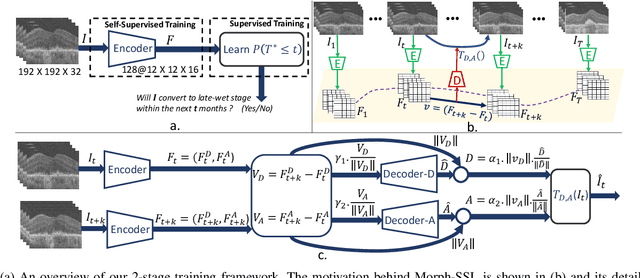



The lack of reliable biomarkers makes predicting the conversion from intermediate to neovascular age-related macular degeneration (iAMD, nAMD) a challenging task. We develop a Deep Learning (DL) model to predict the future risk of conversion of an eye from iAMD to nAMD from its current OCT scan. Although eye clinics generate vast amounts of longitudinal OCT scans to monitor AMD progression, only a small subset can be manually labeled for supervised DL. To address this issue, we propose Morph-SSL, a novel Self-supervised Learning (SSL) method for longitudinal data. It uses pairs of unlabelled OCT scans from different visits and involves morphing the scan from the previous visit to the next. The Decoder predicts the transformation for morphing and ensures a smooth feature manifold that can generate intermediate scans between visits through linear interpolation. Next, the Morph-SSL trained features are input to a Classifier which is trained in a supervised manner to model the cumulative probability distribution of the time to conversion with a sigmoidal function. Morph-SSL was trained on unlabelled scans of 399 eyes (3570 visits). The Classifier was evaluated with a five-fold cross-validation on 2418 scans from 343 eyes with clinical labels of the conversion date. The Morph-SSL features achieved an AUC of 0.766 in predicting the conversion to nAMD within the next 6 months, outperforming the same network when trained end-to-end from scratch or pre-trained with popular SSL methods. Automated prediction of the future risk of nAMD onset can enable timely treatment and individualized AMD management.
Clustering disease trajectories in contrastive feature space for biomarker discovery in age-related macular degeneration
Jan 11, 2023



Age-related macular degeneration (AMD) is the leading cause of blindness in the elderly. Despite this, the exact dynamics of disease progression are poorly understood. There is a clear need for imaging biomarkers in retinal optical coherence tomography (OCT) that aid the diagnosis, prognosis and management of AMD. However, current grading systems, which coarsely group disease stage into broad categories describing early and intermediate AMD, have very limited prognostic value for the conversion to late AMD. In this paper, we are the first to analyse disease progression as clustered trajectories in a self-supervised feature space. Our method first pretrains an encoder with contrastive learning to project images from longitudinal time series to points in feature space. This enables the creation of disease trajectories, which are then denoised, partitioned and grouped into clusters. These clusters, found in two datasets containing time series of 7,912 patients imaged over eight years, were correlated with known OCT biomarkers. This reinforced efforts by four expert ophthalmologists to investigate clusters, during a clinical comparison and interpretation task, as candidates for time-dependent biomarkers that describe progression of AMD.
Learning Spatio-Temporal Model of Disease Progression with NeuralODEs from Longitudinal Volumetric Data
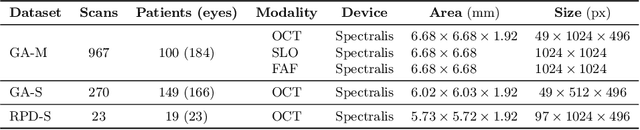
Nov 08, 2022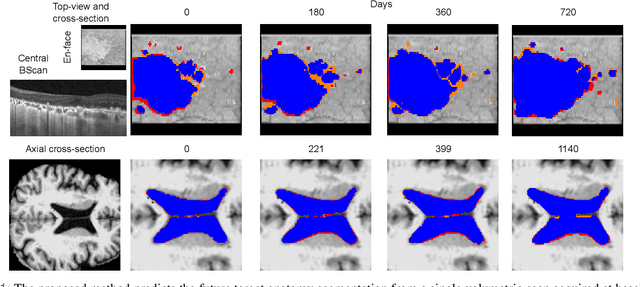
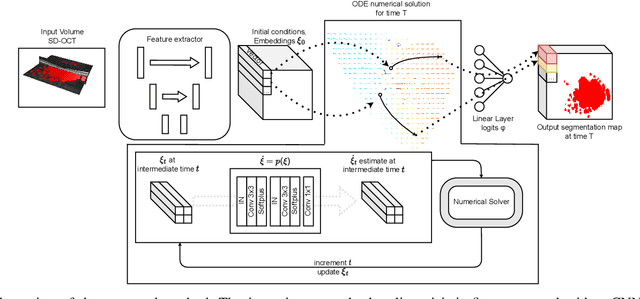
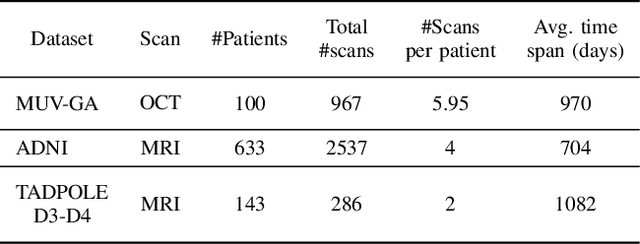

Robust forecasting of the future anatomical changes inflicted by an ongoing disease is an extremely challenging task that is out of grasp even for experienced healthcare professionals. Such a capability, however, is of great importance since it can improve patient management by providing information on the speed of disease progression already at the admission stage, or it can enrich the clinical trials with fast progressors and avoid the need for control arms by the means of digital twins. In this work, we develop a deep learning method that models the evolution of age-related disease by processing a single medical scan and providing a segmentation of the target anatomy at a requested future point in time. Our method represents a time-invariant physical process and solves a large-scale problem of modeling temporal pixel-level changes utilizing NeuralODEs. In addition, we demonstrate the approaches to incorporate the prior domain-specific constraints into our method and define temporal Dice loss for learning temporal objectives. To evaluate the applicability of our approach across different age-related diseases and imaging modalities, we developed and tested the proposed method on the datasets with 967 retinal OCT volumes of 100 patients with Geographic Atrophy, and 2823 brain MRI volumes of 633 patients with Alzheimer's Disease. For Geographic Atrophy, the proposed method outperformed the related baseline models in the atrophy growth prediction. For Alzheimer's Disease, the proposed method demonstrated remarkable performance in predicting the brain ventricle changes induced by the disease, achieving the state-of-the-art result on TADPOLE challenge.
Segmentation of Bruch's Membrane in retinal OCT with AMD using anatomical priors and uncertainty quantification
Oct 30, 2022
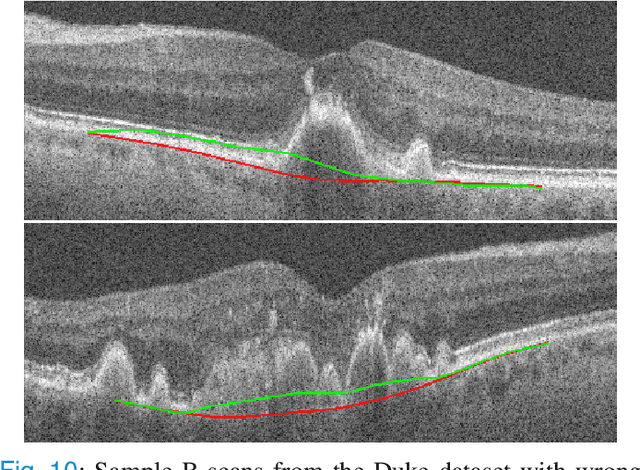
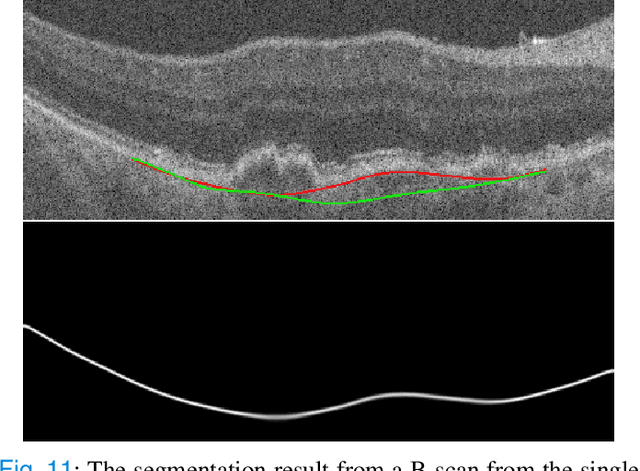

Bruch's membrane (BM) segmentation on optical coherence tomography (OCT) is a pivotal step for the diagnosis and follow-up of age-related macular degeneration (AMD), one of the leading causes of blindness in the developed world. Automated BM segmentation methods exist, but they usually do not account for the anatomical coherence of the results, neither provide feedback on the confidence of the prediction. These factors limit the applicability of these systems in real-world scenarios. With this in mind, we propose an end-to-end deep learning method for automated BM segmentation in AMD patients. An Attention U-Net is trained to output a probability density function of the BM position, while taking into account the natural curvature of the surface. Besides the surface position, the method also estimates an A-scan wise uncertainty measure of the segmentation output. Subsequently, the A-scans with high uncertainty are interpolated using thin plate splines (TPS). We tested our method with ablation studies on an internal dataset with 138 patients covering all three AMD stages, and achieved a mean absolute localization error of 4.10 um. In addition, the proposed segmentation method was compared against the state-of-the-art methods and showed a superior performance on an external publicly available dataset from a different patient cohort and OCT device, demonstrating strong generalization ability.