 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVáclav Šmídl
Is AUC the best measure for practical comparison of anomaly detectors?
May 08, 2023




The area under receiver operating characteristics (AUC) is the standard measure for comparison of anomaly detectors. Its advantage is in providing a scalar number that allows a natural ordering and is independent on a threshold, which allows to postpone the choice. In this work, we question whether AUC is a good metric for anomaly detection, or if it gives a false sense of comfort, due to relying on assumptions which are unlikely to hold in practice. Our investigation shows that variations of AUC emphasizing accuracy at low false positive rate seem to be better correlated with the needs of practitioners, but also that we can compare anomaly detectors only in the case when we have representative examples of anomalous samples. This last result is disturbing, as it suggests that in many cases, we should do active or few-show learning instead of pure anomaly detection.
Fitting large mixture models using stochastic component selection
Oct 10, 2021



Traditional methods for unsupervised learning of finite mixture models require to evaluate the likelihood of all components of the mixture. This becomes computationally prohibitive when the number of components is large, as it is, for example, in the sum-product (transform) networks. Therefore, we propose to apply a combination of the expectation maximization and the Metropolis-Hastings algorithm to evaluate only a small number of, stochastically sampled, components, thus substantially reducing the computational cost. The Markov chain of component assignments is sequentially generated across the algorithm's iterations, having a non-stationary target distribution whose parameters vary via a gradient-descent scheme. We put emphasis on generality of our method, equipping it with the ability to train both shallow and deep mixture models which involve complex, and possibly nonlinear, transformations. The performance of our method is illustrated in a variety of synthetic and real-data contexts, considering deep models, such as mixtures of normalizing flows and sum-product (transform) networks.
Comparison of Anomaly Detectors: Context Matters
Dec 18, 2020



Deep generative models are challenging the classical methods in the field of anomaly detection nowadays. Every new method provides evidence of outperforming its predecessors, often with contradictory results. The objective of this comparison is twofold: comparison of anomaly detection methods of various paradigms, and identification of sources of variability that can yield different results. The methods were compared on popular tabular and image datasets. While the one class support-vector machine (OC-SVM) had no rival on the tabular datasets, the best results on the image data were obtained either by a feature-matching GAN or a combination of variational autoencoder (VAE) and OC-SVM, depending on the experimental conditions. The main sources of variability that can influence the performance of the methods were identified to be: the range of searched hyper-parameters, the methodology of model selection, and the choice of the anomalous samples. All our code and results are available for download.
DeepTopPush: Simple and Scalable Method for Accuracy at the Top
Jun 22, 2020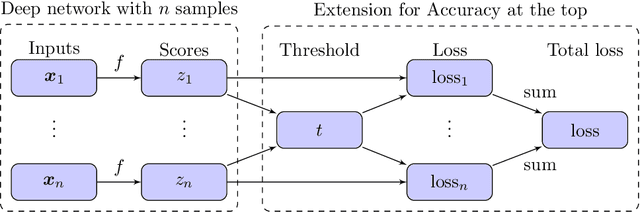
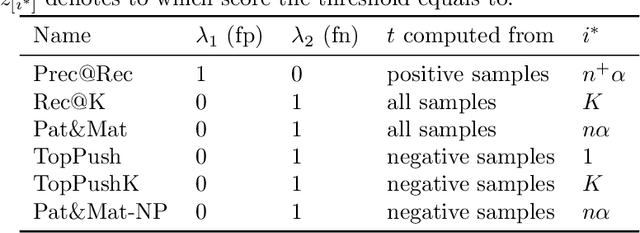
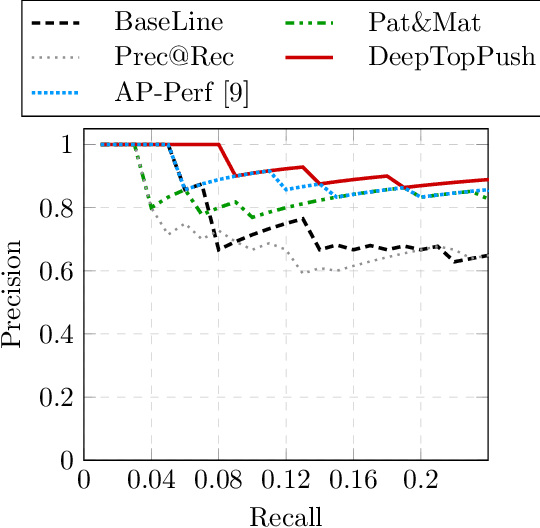
Accuracy at the top is a special class of binary classification problems where the performance is evaluated only on a small number of relevant (top) samples. Applications include information retrieval systems or processes with manual (expensive) postprocessing. This leads to the minimization of irrelevant samples above a threshold. We consider classifiers in the form of an arbitrary (deep) network and propose a new method DeepTopPush for minimizing the top loss function. Since the threshold depends on all samples, the problem is non-decomposable. We modify the stochastic gradient descent to handle the non-decomposability in an end-to-end training manner and propose a way to estimate the threshold only from values on the current minibatch. We demonstrate the good performance of DeepTopPush on visual recognition datasets and on a real-world application of selecting a small number of molecules for further drug testing.
Neural Power Units
Jun 05, 2020



Conventional Neural Networks can approximate simple arithmetic operations, but fail to generalize beyond the range of numbers that were seen during training. Neural Arithmetic Units aim to overcome this difficulty, but current arithmetic units are either limited to operate on positive numbers or can only represent a subset of arithmetic operations. We introduce the Neural Power Unit (NPU) that operates on the full domain of real numbers and is capable of learning arbitrary power functions in a single layer. The NPU thus fixes the shortcomings of existing arithmetic units and extends their expressivity. We achieve this by using complex arithmetic without requiring a conversion of the network to complex numbers. A simplification of the unit to the RealNPU yields a highly interpretable model. We show that the NPUs outperform their competitors in terms of accuracy and sparsity on artificial arithmetic datasets, and that the RealNPU can discover the governing equations of a dynamical systems only from data.
Nonlinear classifiers for ranking problems based on kernelized SVM
Feb 26, 2020
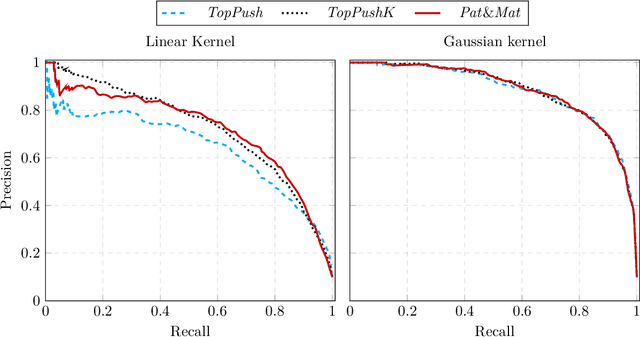
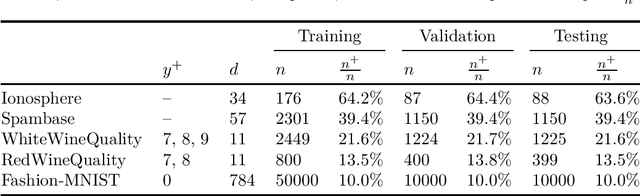
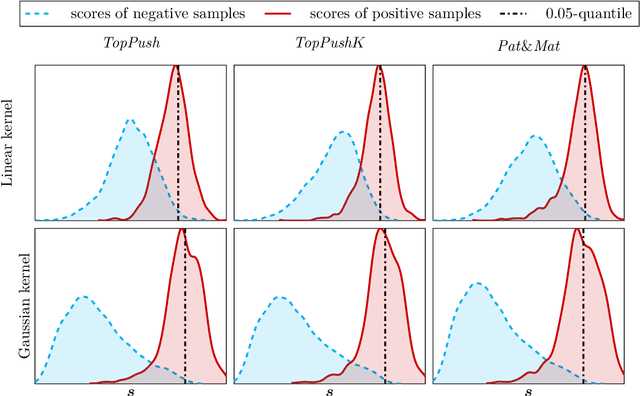
Many classification problems focus on maximizing the performance only on the samples with the highest relevance instead of all samples. As an example, we can mention ranking problems, accuracy at the top or search engines where only the top few queries matter. In our previous work, we derived a general framework including several classes of these linear classification problems. In this paper, we extend the framework to nonlinear classifiers. Utilizing a similarity to SVM, we dualize the problems, add kernels and propose a componentwise dual ascent method. This allows us to perform one iteration in less than 20 milliseconds on relatively large datasets such as FashionMNIST.
General Framework for Binary Classification on Top Samples
Feb 25, 2020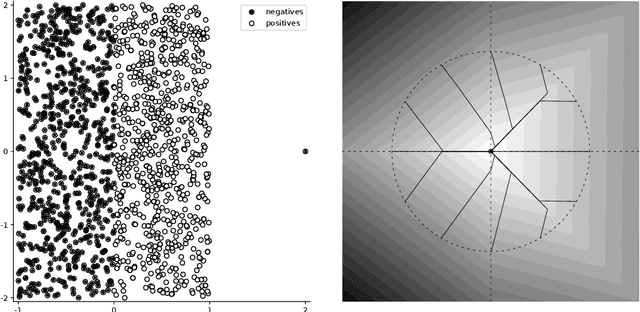

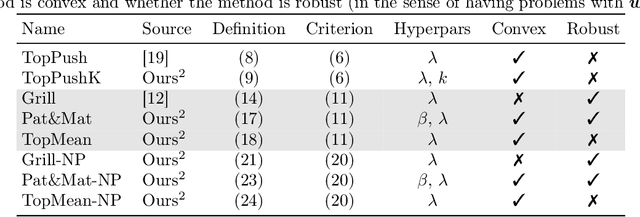
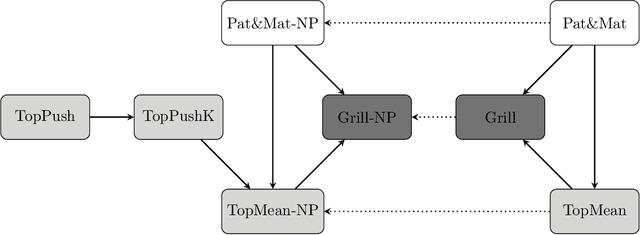
Many binary classification problems minimize misclassification above (or below) a threshold. We show that instances of ranking problems, accuracy at the top or hypothesis testing may be written in this form. We propose a general framework to handle these classes of problems and show which known methods (both known and newly proposed) fall into this framework. We provide a theoretical analysis of this framework and mention selected possible pitfalls the methods may encounter. We suggest several numerical improvements including the implicit derivative and stochastic gradient descent. We provide an extensive numerical study. Based both on the theoretical properties and numerical experiments, we conclude the paper by suggesting which method should be used in which situation.
Rodent: Relevance determination in ODE
Dec 02, 2019



From a set of observed trajectories of a partially observed system, we aim to learn its underlying (physical) process without having to make too many assumptions about the generating model. We start with a very general, over-parameterized ordinary differential equation (ODE) of order N and learn the minimal complexity of the model, by which we mean both the order of the ODE as well as the minimum number of non-zero parameters that are needed to solve the problem. The minimal complexity is found by combining the Variational Auto-Encoder (VAE) with Automatic Relevance Determination (ARD) to the problem of learning the parameters of an ODE which we call Rodent. We show that it is possible to learn not only one specific model for a single process, but a manifold of models representing harmonic signals in general.
Anomaly scores for generative models
May 28, 2019


Reconstruction error is a prevalent score used to identify anomalous samples when data are modeled by generative models, such as (variational) auto-encoders or generative adversarial networks. This score relies on the assumption that normal samples are located on a manifold and all anomalous samples are located outside. Since the manifold can be learned only where the training data lie, there are no guarantees how the reconstruction error behaves elsewhere and the score, therefore, seems to be ill-defined. This work defines an anomaly score that is theoretically compatible with generative models, and very natural for (variational) auto-encoders as they seem to be prevalent. The new score can be also used to select hyper-parameters and models. Finally, we explain why reconstruction error delivers good experimental results despite weak theoretical justification.
Are generative deep models for novelty detection truly better?
Jul 13, 2018



Many deep models have been recently proposed for anomaly detection. This paper presents comparison of selected generative deep models and classical anomaly detection methods on an extensive number of non--image benchmark datasets. We provide statistical comparison of the selected models, in many configurations, architectures and hyperparamaters. We arrive to conclusion that performance of the generative models is determined by the process of selection of their hyperparameters. Specifically, performance of the deep generative models deteriorates with decreasing amount of anomalous samples used in hyperparameter selection. In practical scenarios of anomaly detection, none of the deep generative models systematically outperforms the kNN.