 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaikkunth Mugunthan
Navigating Data Heterogeneity in Federated Learning A Semi-Supervised Approach for Object Detection
Oct 27, 2023
Federated Learning (FL) has emerged as a potent framework for training models across distributed data sources while maintaining data privacy. Nevertheless, it faces challenges with limited high-quality labels and non-IID client data, particularly in applications like autonomous driving. To address these hurdles, we navigate the uncharted waters of Semi-Supervised Federated Object Detection (SSFOD). We present a pioneering SSFOD framework, designed for scenarios where labeled data reside only at the server while clients possess unlabeled data. Notably, our method represents the inaugural implementation of SSFOD for clients with 0% labeled non-IID data, a stark contrast to previous studies that maintain some subset of labels at each client. We propose FedSTO, a two-stage strategy encompassing Selective Training followed by Orthogonally enhanced full-parameter training, to effectively address data shift (e.g. weather conditions) between server and clients. Our contributions include selectively refining the backbone of the detector to avert overfitting, orthogonality regularization to boost representation divergence, and local EMA-driven pseudo label assignment to yield high-quality pseudo labels. Extensive validation on prominent autonomous driving datasets (BDD100K, Cityscapes, and SODA10M) attests to the efficacy of our approach, demonstrating state-of-the-art results. Remarkably, FedSTO, using just 20-30% of labels, performs nearly as well as fully-supervised centralized training methods.
Does fine-tuning GPT-3 with the OpenAI API leak personally-identifiable information?
Jul 31, 2023
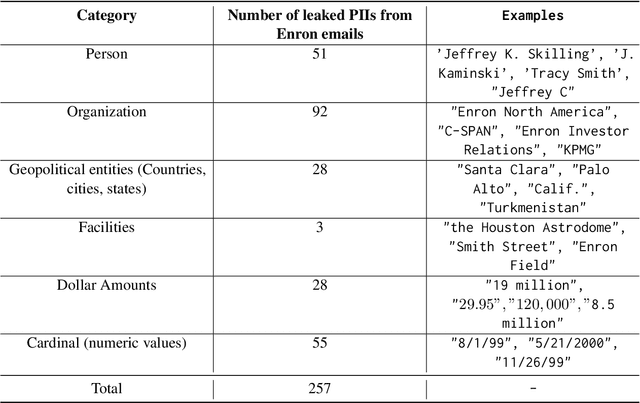

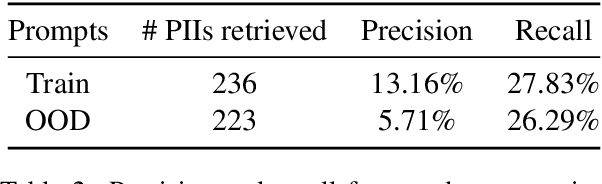
Machine learning practitioners often fine-tune generative pre-trained models like GPT-3 to improve model performance at specific tasks. Previous works, however, suggest that fine-tuned machine learning models memorize and emit sensitive information from the original fine-tuning dataset. Companies such as OpenAI offer fine-tuning services for their models, but no prior work has conducted a memorization attack on any closed-source models. In this work, we simulate a privacy attack on GPT-3 using OpenAI's fine-tuning API. Our objective is to determine if personally identifiable information (PII) can be extracted from this model. We (1) explore the use of naive prompting methods on a GPT-3 fine-tuned classification model, and (2) we design a practical word generation task called Autocomplete to investigate the extent of PII memorization in fine-tuned GPT-3 within a real-world context. Our findings reveal that fine-tuning GPT3 for both tasks led to the model memorizing and disclosing critical personally identifiable information (PII) obtained from the underlying fine-tuning dataset. To encourage further research, we have made our codes and datasets publicly available on GitHub at: https://github.com/albertsun1/gpt3-pii-attacks
Collusion Resistant Federated Learning with Oblivious Distributed Differential Privacy
Feb 20, 2022
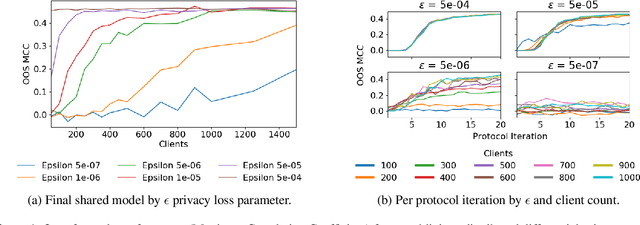
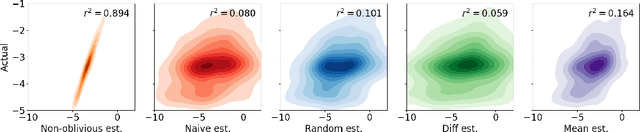
Privacy-preserving federated learning enables a population of distributed clients to jointly learn a shared model while keeping client training data private, even from an untrusted server. Prior works do not provide efficient solutions that protect against collusion attacks in which parties collaborate to expose an honest client's model parameters. We present an efficient mechanism based on oblivious distributed differential privacy that is the first to protect against such client collusion, including the "Sybil" attack in which a server preferentially selects compromised devices or simulates fake devices. We leverage the novel privacy mechanism to construct a secure federated learning protocol and prove the security of that protocol. We conclude with empirical analysis of the protocol's execution speed, learning accuracy, and privacy performance on two data sets within a realistic simulation of 5,000 distributed network clients.
Gradient Masked Averaging for Federated Learning
Jan 28, 2022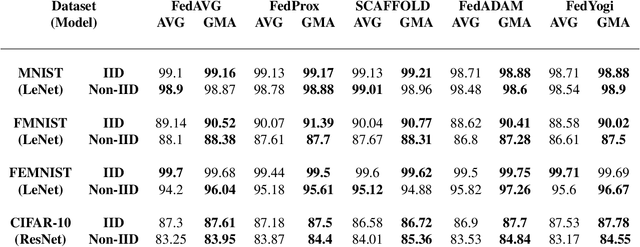
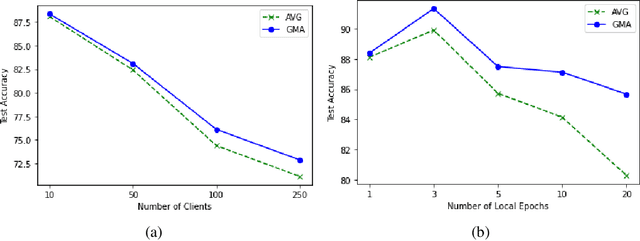
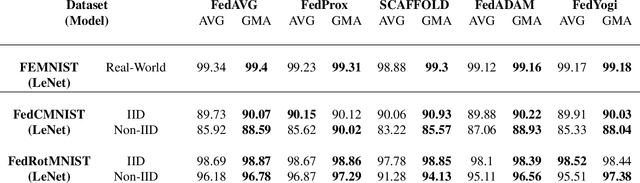
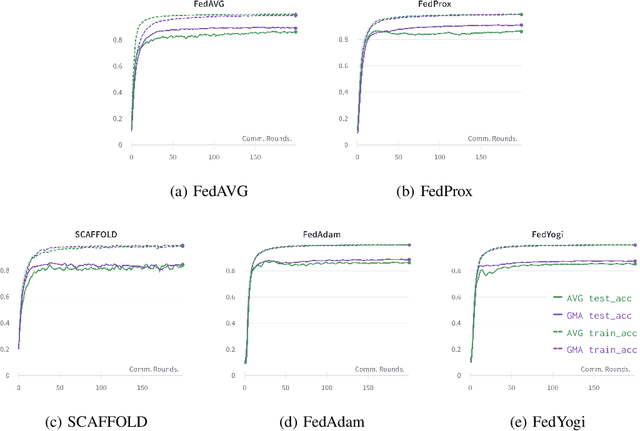
Federated learning is an emerging paradigm that permits a large number of clients with heterogeneous data to coordinate learning of a unified global model without the need to share data amongst each other. Standard federated learning algorithms involve averaging of model parameters or gradient updates to approximate the global model at the server. However, in heterogeneous settings averaging can result in information loss and lead to poor generalization due to the bias induced by dominant clients. We hypothesize that to generalize better across non-i.i.d datasets as in FL settings, the algorithms should focus on learning the invariant mechanism that is constant while ignoring spurious mechanisms that differ across clients. Inspired from recent work in the Out-of-Distribution literature, we propose a gradient masked averaging approach for federated learning as an alternative to the standard averaging of client updates. This client update aggregation technique can be adapted as a drop-in replacement in most existing federated algorithms. We perform extensive experiments with gradient masked approach on multiple FL algorithms with in-distribution, real-world, and out-of-distribution (as the worst case scenario) test dataset and show that it provides consistent improvements, particularly in the case of heterogeneous clients.
Multi-VFL: A Vertical Federated Learning System for Multiple Data and Label Owners
Jun 17, 2021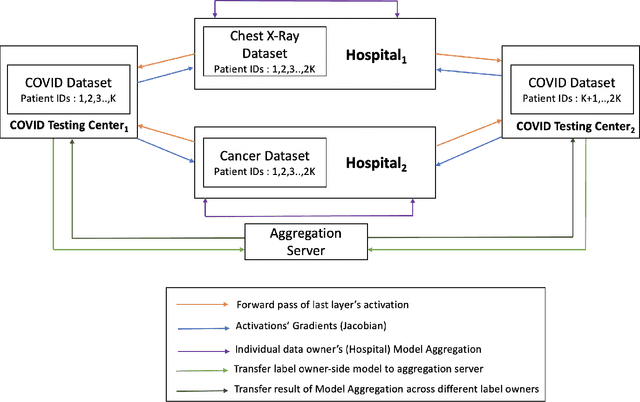


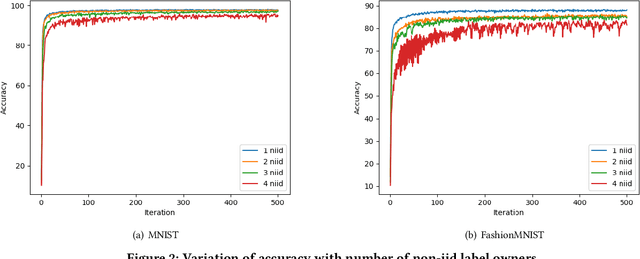
Vertical Federated Learning (VFL) refers to the collaborative training of a model on a dataset where the features of the dataset are split among multiple data owners, while label information is owned by a single data owner. In this paper, we propose a novel method, Multi Vertical Federated Learning (Multi-VFL), to train VFL models when there are multiple data and label owners. Our approach is the first to consider the setting where $D$-data owners (across which features are distributed) and $K$-label owners (across which labels are distributed) exist. This proposed configuration allows different entities to train and learn optimal models without having to share their data. Our framework makes use of split learning and adaptive federated optimizers to solve this problem. For empirical evaluation, we run experiments on the MNIST and FashionMNIST datasets. Our results show that using adaptive optimizers for model aggregation fastens convergence and improves accuracy.
Prior-Independent Auctions for the Demand Side of Federated Learning
Apr 13, 2021
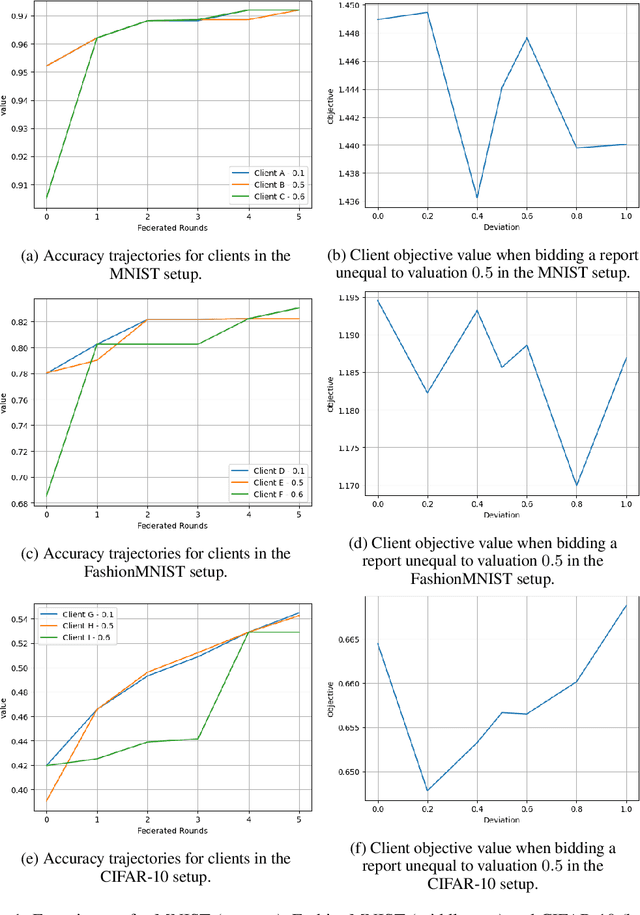
Federated learning (FL) is a paradigm that allows distributed clients to learn a shared machine learning model without sharing their sensitive training data. While largely decentralized, FL requires resources to fund a central orchestrator or to reimburse contributors of datasets to incentivize participation. Inspired by insights from prior-independent auction design, we propose a mechanism, FIPIA (Federated Incentive Payments via Prior-Independent Auctions), to collect monetary contributions from self-interested clients. The mechanism operates in the semi-honest trust model and works even if clients have a heterogeneous interest in receiving high-quality models, and the server does not know the clients' level of interest. We run experiments on the MNIST, FashionMNIST, and CIFAR-10 datasets to test clients' model quality under FIPIA and FIPIA's incentive properties.
Bias-Free FedGAN
Mar 17, 2021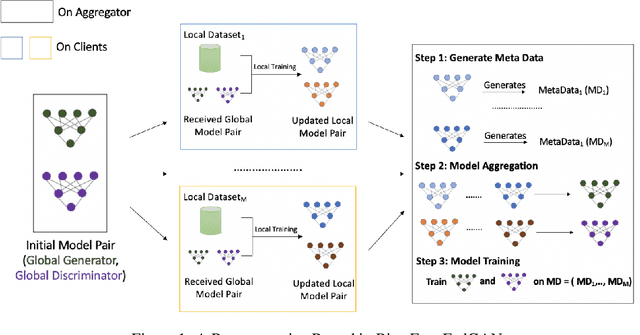

Federated Generative Adversarial Network (FedGAN) is a communication-efficient approach to train a GAN across distributed clients without clients having to share their sensitive training data. In this paper, we experimentally show that FedGAN generates biased data points under non-independent-and-identically-distributed (non-iid) settings. Also, we propose Bias-Free FedGAN, an approach to generate bias-free synthetic datasets using FedGAN. Bias-Free FedGAN has the same communication cost as that of FedGAN. Experimental results on image datasets (MNIST and FashionMNIST) validate our claims.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020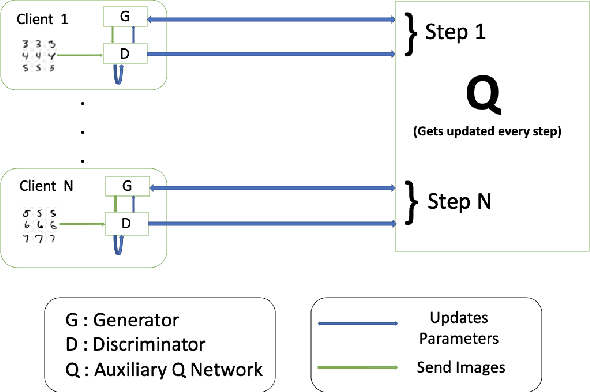
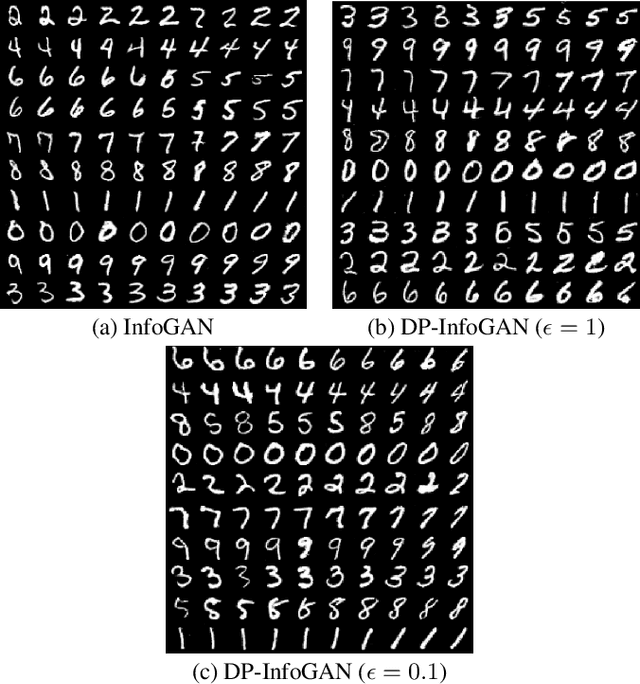


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
BlockFLow: An Accountable and Privacy-Preserving Solution for Federated Learning
Jul 08, 2020



Federated learning enables the development of a machine learning model among collaborating agents without requiring them to share their underlying data. However, malicious agents who train on random data, or worse, on datasets with the result classes inverted, can weaken the combined model. BlockFLow is an accountable federated learning system that is fully decentralized and privacy-preserving. Its primary goal is to reward agents proportional to the quality of their contribution while protecting the privacy of the underlying datasets and being resilient to malicious adversaries. Specifically, BlockFLow incorporates differential privacy, introduces a novel auditing mechanism for model contribution, and uses Ethereum smart contracts to incentivize good behavior. Unlike existing auditing and accountability methods for federated learning systems, our system does not require a centralized test dataset, sharing of datasets between the agents, or one or more trusted auditors; it is fully decentralized and resilient up to a 50% collusion attack in a malicious trust model. When run on the public Ethereum blockchain, BlockFLow uses the results from the audit to reward parties with cryptocurrency based on the quality of their contribution. We evaluated BlockFLow on two datasets that offer classification tasks solvable via logistic regression models. Our results show that the resultant auditing scores reflect the quality of the honest agents' datasets. Moreover, the scores from dishonest agents are statistically lower than those from the honest agents. These results, along with the reasonable blockchain costs, demonstrate the effectiveness of BlockFLow as an accountable federated learning system.
PrivacyFL: A simulator for privacy-preserving and secure federated learning
Feb 19, 2020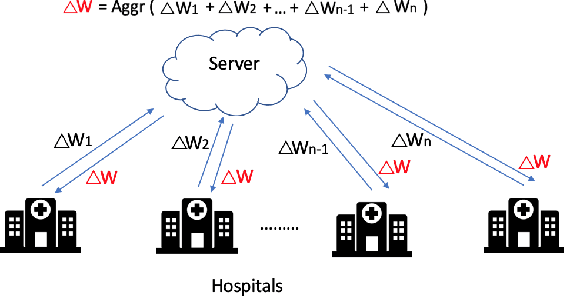


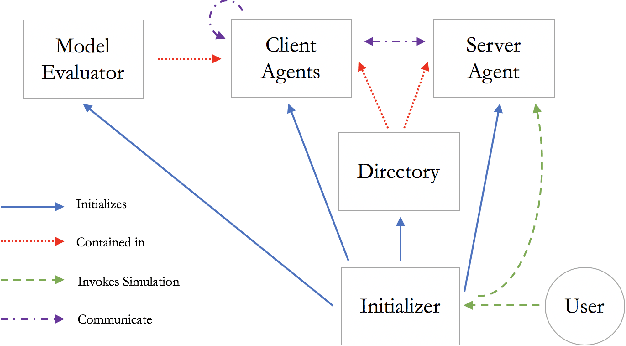
Federated learning is a technique that enables distributed clients to collaboratively learn a shared machine learning model while keeping their training data localized. This reduces data privacy risks, however, privacy concerns still exist since it is possible to leak information about the training dataset from the trained model's weights or parameters. Setting up a federated learning environment, especially with security and privacy guarantees, is a time-consuming process with numerous configurations and parameters that can be manipulated. In order to help clients ensure that collaboration is feasible and to check that it improves their model accuracy, a real-world simulator for privacy-preserving and secure federated learning is required. In this paper, we introduce PrivacyFL, which is an extensible, easily configurable and scalable simulator for federated learning environments. Its key features include latency simulation, robustness to client departure, support for both centralized and decentralized learning, and configurable privacy and security mechanisms based on differential privacy and secure multiparty computation. In this paper, we motivate our research, describe the architecture of the simulator and associated protocols, and discuss its evaluation in numerous scenarios that highlight its wide range of functionality and its advantages. Our paper addresses a significant real-world problem: checking the feasibility of participating in a federated learning environment under a variety of circumstances. It also has a strong practical impact because organizations such as hospitals, banks, and research institutes, which have large amounts of sensitive data and would like to collaborate, would greatly benefit from having a system that enables them to do so in a privacy-preserving and secure manner.