 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarshini Reddy
Tokenization Is More Than Compression
Feb 28, 2024
Tokenization is a foundational step in Natural Language Processing (NLP) tasks, bridging raw text and language models. Existing tokenization approaches like Byte-Pair Encoding (BPE) originate from the field of data compression, and it has been suggested that the effectiveness of BPE stems from its ability to condense text into a relatively small number of tokens. We test the hypothesis that fewer tokens lead to better downstream performance by introducing PathPiece, a new tokenizer that segments a document's text into the minimum number of tokens for a given vocabulary. Through extensive experimentation we find this hypothesis not to be the case, casting doubt on the understanding of the reasons for effective tokenization. To examine which other factors play a role, we evaluate design decisions across all three phases of tokenization: pre-tokenization, vocabulary construction, and segmentation, offering new insights into the design of effective tokenizers. Specifically, we illustrate the importance of pre-tokenization and the benefits of using BPE to initialize vocabulary construction. We train 64 language models with varying tokenization, ranging in size from 350M to 2.4B parameters, all of which are made publicly available.
DocFinQA: A Long-Context Financial Reasoning Dataset
Jan 12, 2024Research in quantitative reasoning within the financial domain indeed necessitates the use of realistic tasks and data, primarily because of the significant impact of decisions made in business and finance. Financial professionals often interact with documents hundreds of pages long, but most research datasets drastically reduce this context length. To address this, we introduce a long-document financial QA task. We augment 7,621 questions from the existing FinQA dataset with full-document context, extending the average context length for each question from under 700 words in FinQA to 123k words in DocFinQA. We conduct extensive experiments of retrieval-based QA pipelines and long-context language models on the augmented data. Our results show that DocFinQA provides challenges for even the strongest, state-of-the-art systems.
BizBench: A Quantitative Reasoning Benchmark for Business and Finance
Nov 11, 2023As large language models (LLMs) impact a growing number of complex domains, it is becoming increasingly important to have fair, accurate, and rigorous evaluation benchmarks. Evaluating the reasoning skills required for business and financial NLP stands out as a particularly difficult challenge. We introduce BizBench, a new benchmark for evaluating models' ability to reason about realistic financial problems. BizBench comprises 8 quantitative reasoning tasks. Notably, BizBench targets the complex task of question-answering (QA) for structured and unstructured financial data via program synthesis (i.e., code generation). We introduce three diverse financially-themed code-generation tasks from newly collected and augmented QA data. Additionally, we isolate distinct financial reasoning capabilities required to solve these QA tasks: reading comprehension of financial text and tables, which is required to extract correct intermediate values; and understanding domain knowledge (e.g., financial formulas) needed to calculate complex solutions. Collectively, these tasks evaluate a model's financial background knowledge, ability to extract numeric entities from financial documents, and capacity to solve problems with code. We conduct an in-depth evaluation of open-source and commercial LLMs, illustrating that BizBench is a challenging benchmark for quantitative reasoning in the finance and business domain.
Mask Conditional Synthetic Satellite Imagery
Feb 08, 2023



In this paper we propose a mask-conditional synthetic image generation model for creating synthetic satellite imagery datasets. Given a dataset of real high-resolution images and accompanying land cover masks, we show that it is possible to train an upstream conditional synthetic imagery generator, use that generator to create synthetic imagery with the land cover masks, then train a downstream model on the synthetic imagery and land cover masks that achieves similar test performance to a model that was trained with the real imagery. Further, we find that incorporating a mixture of real and synthetic imagery acts as a data augmentation method, producing better models than using only real imagery (0.5834 vs. 0.5235 mIoU). Finally, we find that encouraging diversity of outputs in the upstream model is a necessary component for improved downstream task performance. We have released code for reproducing our work on GitHub, see https://github.com/ms-synthetic-satellite-image/synthetic-satellite-imagery .
Success of Uncertainty-Aware Deep Models Depends on Data Manifold Geometry
Aug 05, 2022
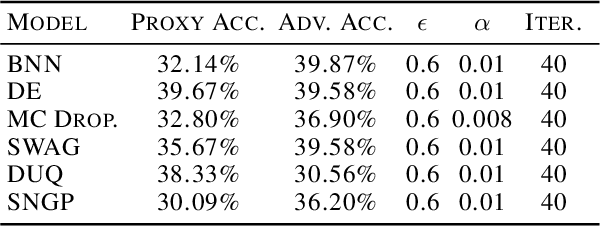
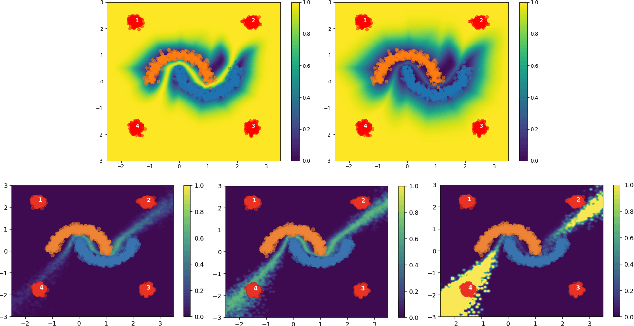
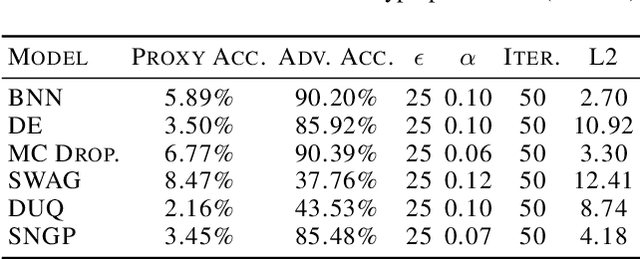
For responsible decision making in safety-critical settings, machine learning models must effectively detect and process edge-case data. Although existing works show that predictive uncertainty is useful for these tasks, it is not evident from literature which uncertainty-aware models are best suited for a given dataset. Thus, we compare six uncertainty-aware deep learning models on a set of edge-case tasks: robustness to adversarial attacks as well as out-of-distribution and adversarial detection. We find that the geometry of the data sub-manifold is an important factor in determining the success of various models. Our finding suggests an interesting direction in the study of uncertainty-aware deep learning models.