 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVasileios Belagiannis
Multi-conditioned Graph Diffusion for Neural Architecture Search
Mar 09, 2024
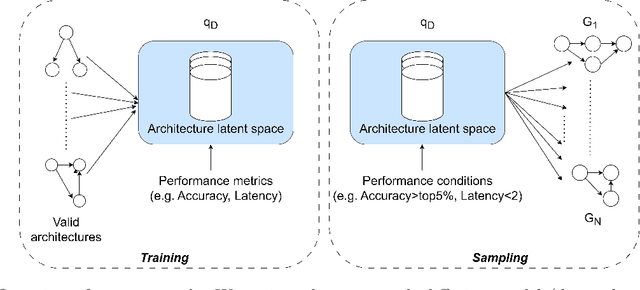
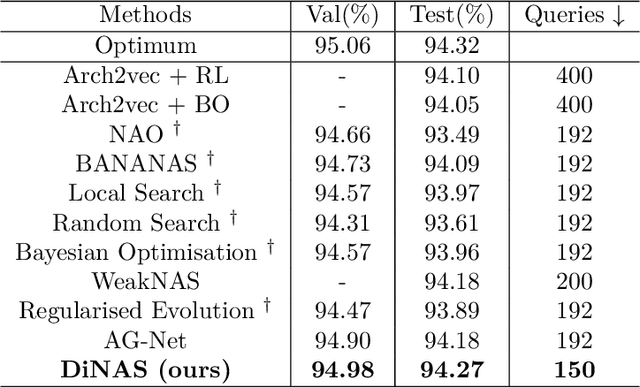
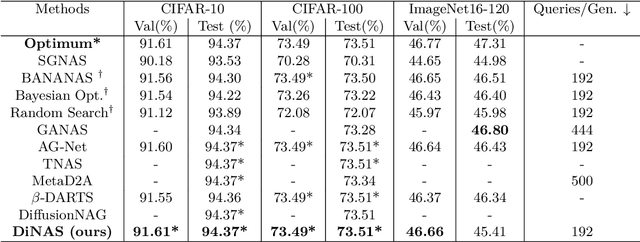
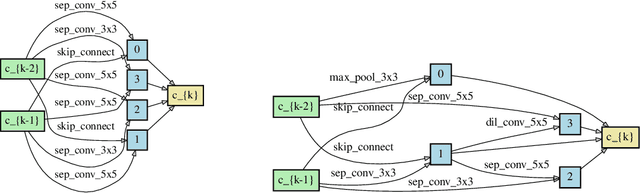
Neural architecture search automates the design of neural network architectures usually by exploring a large and thus complex architecture search space. To advance the architecture search, we present a graph diffusion-based NAS approach that uses discrete conditional graph diffusion processes to generate high-performing neural network architectures. We then propose a multi-conditioned classifier-free guidance approach applied to graph diffusion networks to jointly impose constraints such as high accuracy and low hardware latency. Unlike the related work, our method is completely differentiable and requires only a single model training. In our evaluations, we show promising results on six standard benchmarks, yielding novel and unique architectures at a fast speed, i.e. less than 0.2 seconds per architecture. Furthermore, we demonstrate the generalisability and efficiency of our method through experiments on ImageNet dataset.
Pedestrian Environment Model for Automated Driving
Aug 17, 2023Besides interacting correctly with other vehicles, automated vehicles should also be able to react in a safe manner to vulnerable road users like pedestrians or cyclists. For a safe interaction between pedestrians and automated vehicles, the vehicle must be able to interpret the pedestrian's behavior. Common environment models do not contain information like body poses used to understand the pedestrian's intent. In this work, we propose an environment model that includes the position of the pedestrians as well as their pose information. We only use images from a monocular camera and the vehicle's localization data as input to our pedestrian environment model. We extract the skeletal information with a neural network human pose estimator from the image. Furthermore, we track the skeletons with a simple tracking algorithm based on the Hungarian algorithm and an ego-motion compensation. To obtain the 3D information of the position, we aggregate the data from consecutive frames in conjunction with the vehicle position. We demonstrate our pedestrian environment model on data generated with the CARLA simulator and the nuScenes dataset. Overall, we reach a relative position error of around 16% on both datasets.
Out-of-Distribution Detection for Monocular Depth Estimation
Aug 11, 2023In monocular depth estimation, uncertainty estimation approaches mainly target the data uncertainty introduced by image noise. In contrast to prior work, we address the uncertainty due to lack of knowledge, which is relevant for the detection of data not represented by the training distribution, the so-called out-of-distribution (OOD) data. Motivated by anomaly detection, we propose to detect OOD images from an encoder-decoder depth estimation model based on the reconstruction error. Given the features extracted with the fixed depth encoder, we train an image decoder for image reconstruction using only in-distribution data. Consequently, OOD images result in a high reconstruction error, which we use to distinguish between in- and out-of-distribution samples. We built our experiments on the standard NYU Depth V2 and KITTI benchmarks as in-distribution data. Our post hoc method performs astonishingly well on different models and outperforms existing uncertainty estimation approaches without modifying the trained encoder-decoder depth estimation model.
SelectNAdapt: Support Set Selection for Few-Shot Domain Adaptation
Aug 09, 2023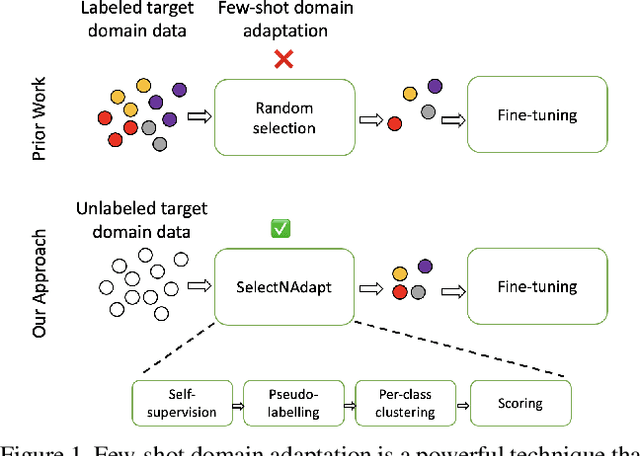

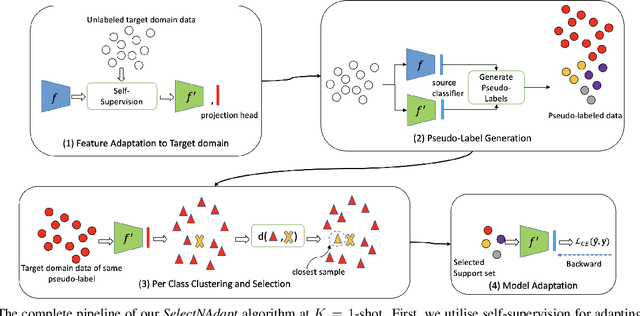
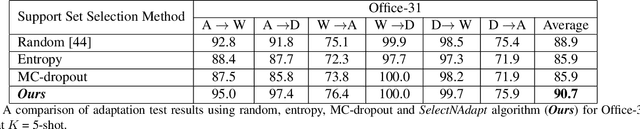
Generalisation of deep neural networks becomes vulnerable when distribution shifts are encountered between train (source) and test (target) domain data. Few-shot domain adaptation mitigates this issue by adapting deep neural networks pre-trained on the source domain to the target domain using a randomly selected and annotated support set from the target domain. This paper argues that randomly selecting the support set can be further improved for effectively adapting the pre-trained source models to the target domain. Alternatively, we propose SelectNAdapt, an algorithm to curate the selection of the target domain samples, which are then annotated and included in the support set. In particular, for the K-shot adaptation problem, we first leverage self-supervision to learn features of the target domain data. Then, we propose a per-class clustering scheme of the learned target domain features and select K representative target samples using a distance-based scoring function. Finally, we bring our selection setup towards a practical ground by relying on pseudo-labels for clustering semantically similar target domain samples. Our experiments show promising results on three few-shot domain adaptation benchmarks for image recognition compared to related approaches and the standard random selection.
Joint Out-of-Distribution Detection and Uncertainty Estimation for Trajectory Prediction
Aug 04, 2023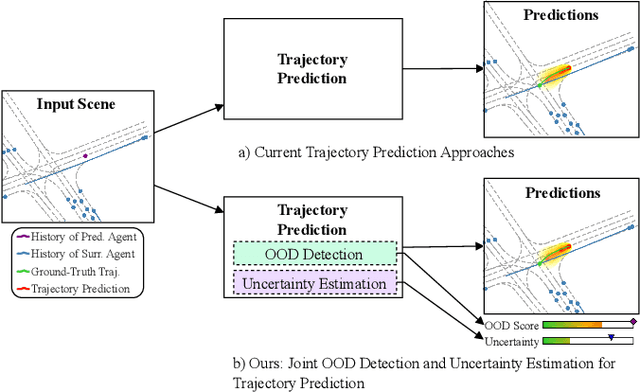
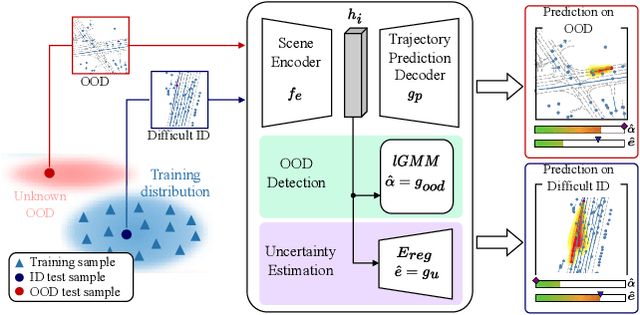
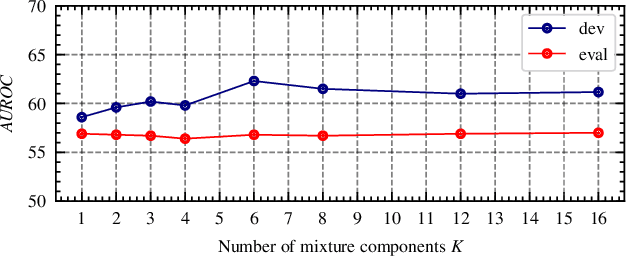
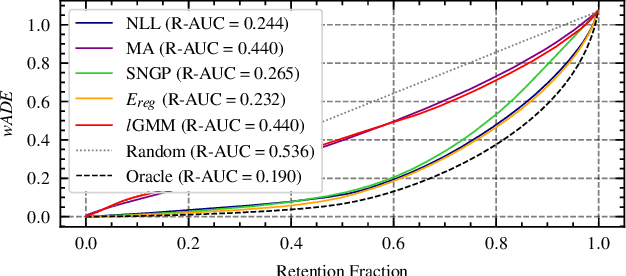
Despite the significant research efforts on trajectory prediction for automated driving, limited work exists on assessing the prediction reliability. To address this limitation we propose an approach that covers two sources of error, namely novel situations with out-of-distribution (OOD) detection and the complexity in in-distribution (ID) situations with uncertainty estimation. We introduce two modules next to an encoder-decoder network for trajectory prediction. Firstly, a Gaussian mixture model learns the probability density function of the ID encoder features during training, and then it is used to detect the OOD samples in regions of the feature space with low likelihood. Secondly, an error regression network is applied to the encoder, which learns to estimate the trajectory prediction error in supervised training. During inference, the estimated prediction error is used as the uncertainty. In our experiments, the combination of both modules outperforms the prior work in OOD detection and uncertainty estimation, on the Shifts robust trajectory prediction dataset by $2.8 \%$ and $10.1 \%$, respectively. The code is publicly available.
Automated Automotive Radar Calibration With Intelligent Vehicles
Jun 23, 2023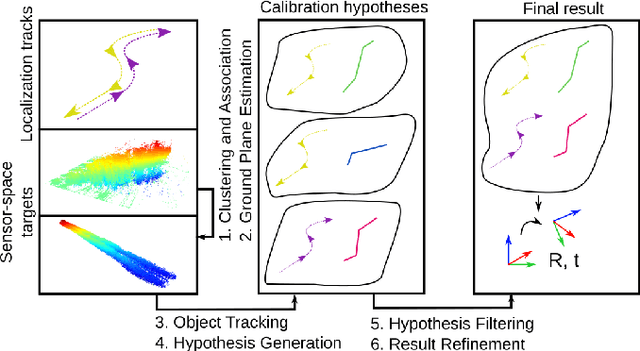
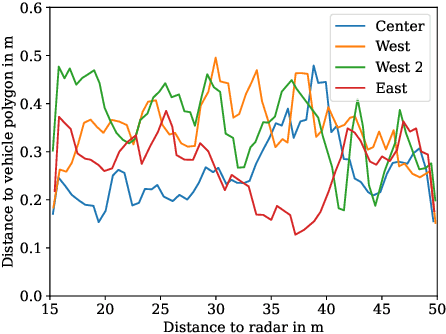
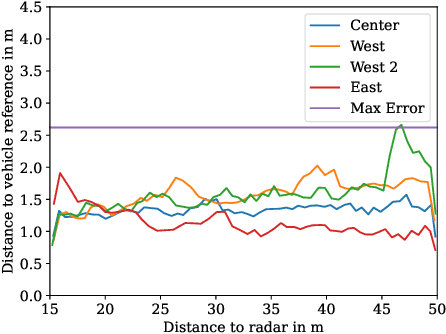

While automotive radar sensors are widely adopted and have been used for automatic cruise control and collision avoidance tasks, their application outside of vehicles is still limited. As they have the ability to resolve multiple targets in 3D space, radars can also be used for improving environment perception. This application, however, requires a precise calibration, which is usually a time-consuming and labor-intensive task. We, therefore, present an approach for automated and geo-referenced extrinsic calibration of automotive radar sensors that is based on a novel hypothesis filtering scheme. Our method does not require external modifications of a vehicle and instead uses the location data obtained from automated vehicles. This location data is then combined with filtered sensor data to create calibration hypotheses. Subsequent filtering and optimization recovers the correct calibration. Our evaluation on data from a real testing site shows that our method can correctly calibrate infrastructure sensors in an automated manner, thus enabling cooperative driving scenarios.
Data-Free Backbone Fine-Tuning for Pruned Neural Networks
Jun 22, 2023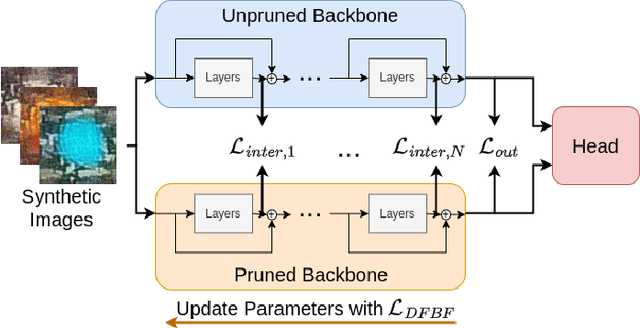



Model compression techniques reduce the computational load and memory consumption of deep neural networks. After the compression operation, e.g. parameter pruning, the model is normally fine-tuned on the original training dataset to recover from the performance drop caused by compression. However, the training data is not always available due to privacy issues or other factors. In this work, we present a data-free fine-tuning approach for pruning the backbone of deep neural networks. In particular, the pruned network backbone is trained with synthetically generated images, and our proposed intermediate supervision to mimic the unpruned backbone's output feature map. Afterwards, the pruned backbone can be combined with the original network head to make predictions. We generate synthetic images by back-propagating gradients to noise images while relying on L1-pruning for the backbone pruning. In our experiments, we show that our approach is task-independent due to pruning only the backbone. By evaluating our approach on 2D human pose estimation, object detection, and image classification, we demonstrate promising performance compared to the unpruned model. Our code is available at https://github.com/holzbock/dfbf.
Automated Static Camera Calibration with Intelligent Vehicles
Apr 21, 2023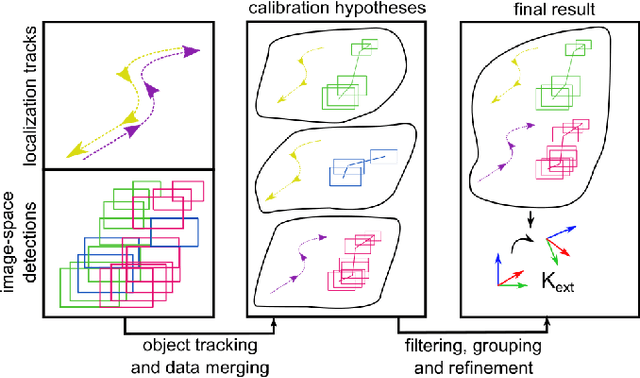
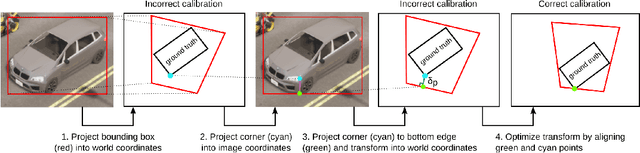
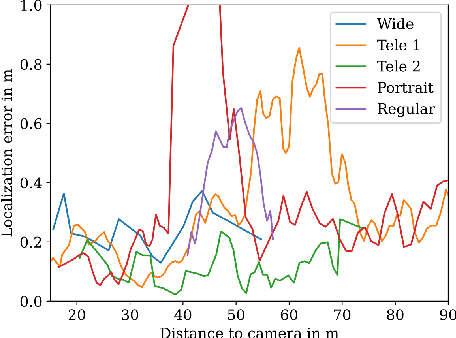
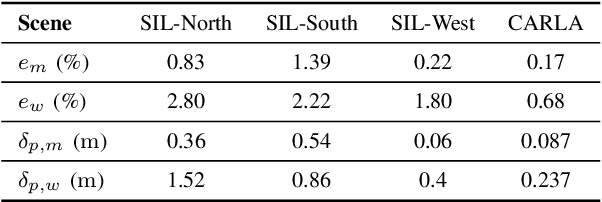
Connected and cooperative driving requires precise calibration of the roadside infrastructure for having a reliable perception system. To solve this requirement in an automated manner, we present a robust extrinsic calibration method for automated geo-referenced camera calibration. Our method requires a calibration vehicle equipped with a combined GNSS/RTK receiver and an inertial measurement unit (IMU) for self-localization. In order to remove any requirements for the target's appearance and the local traffic conditions, we propose a novel approach using hypothesis filtering. Our method does not require any human interaction with the information recorded by both the infrastructure and the vehicle. Furthermore, we do not limit road access for other road users during calibration. We demonstrate the feasibility and accuracy of our approach by evaluating our approach on synthetic datasets as well as a real-world connected intersection, and deploying the calibration on real infrastructure. Our source code is publicly available.
RESET: Revisiting Trajectory Sets for Conditional Behavior Prediction
Apr 12, 2023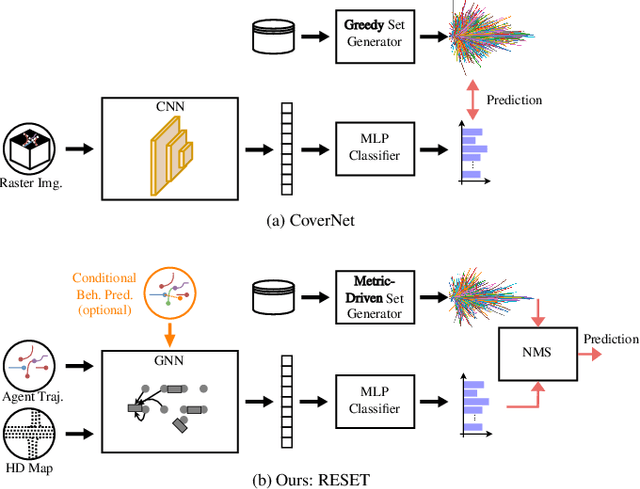
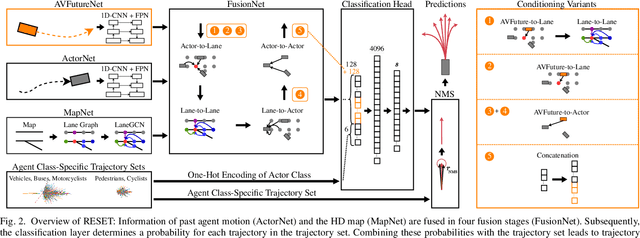
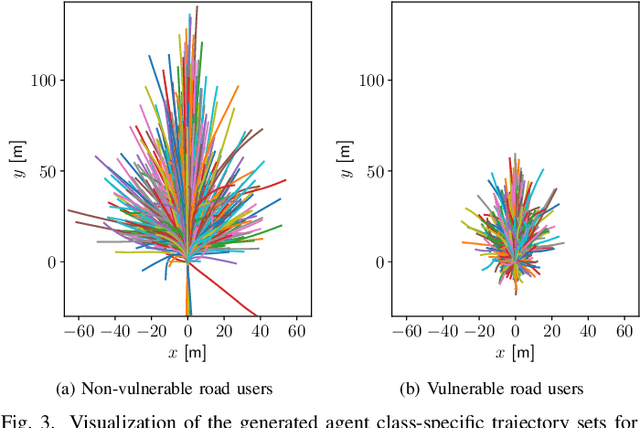
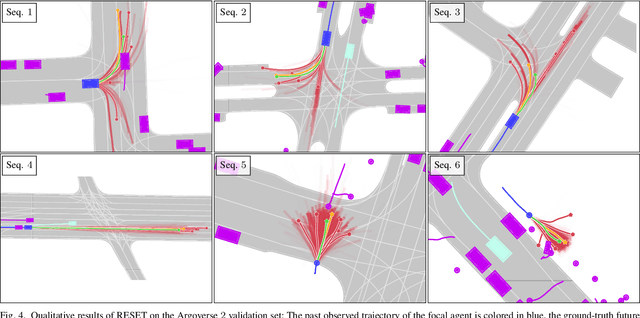
It is desirable to predict the behavior of traffic participants conditioned on different planned trajectories of the autonomous vehicle. This allows the downstream planner to estimate the impact of its decisions. Recent approaches for conditional behavior prediction rely on a regression decoder, meaning that coordinates or polynomial coefficients are regressed. In this work we revisit set-based trajectory prediction, where the probability of each trajectory in a predefined trajectory set is determined by a classification model, and first-time employ it to the task of conditional behavior prediction. We propose RESET, which combines a new metric-driven algorithm for trajectory set generation with a graph-based encoder. For unconditional prediction, RESET achieves comparable performance to a regression-based approach. Due to the nature of set-based approaches, it has the advantageous property of being able to predict a flexible number of trajectories without influencing runtime or complexity. For conditional prediction, RESET achieves reasonable results with late fusion of the planned trajectory, which was not observed for regression-based approaches before. This means that RESET is computationally lightweight to combine with a planner that proposes multiple future plans of the autonomous vehicle, as large parts of the forward pass can be reused.
Localizing Spatial Information in Neural Spatiospectral Filters
Mar 14, 2023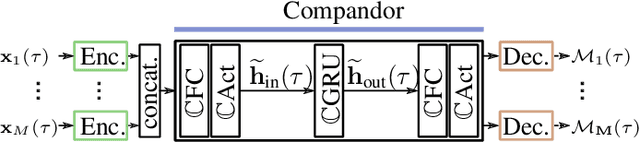
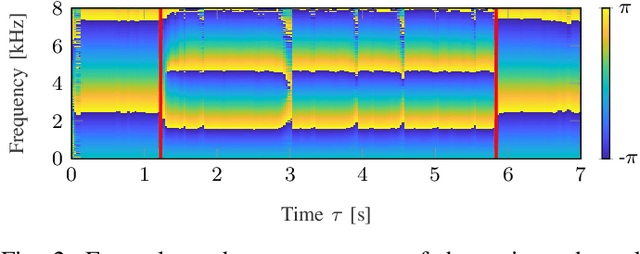
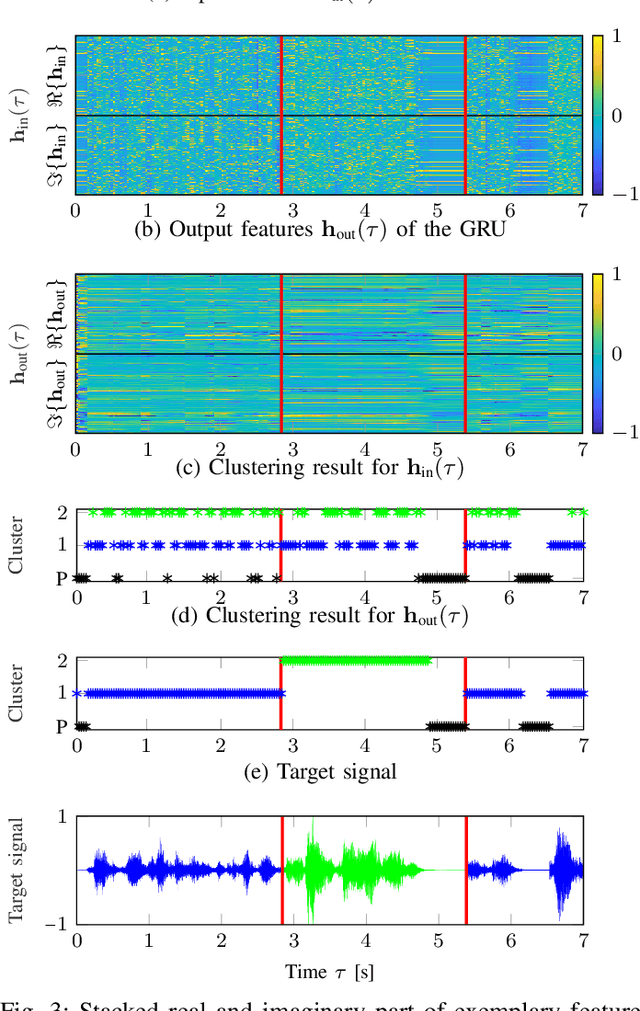
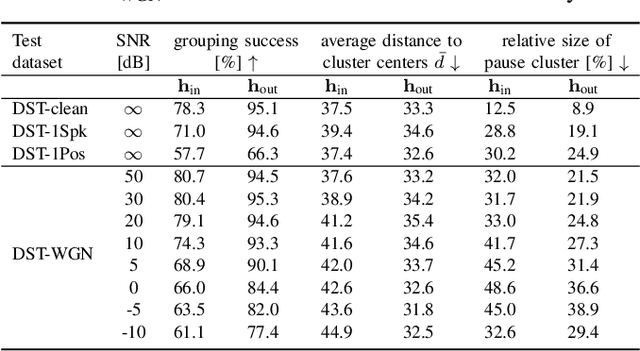
Beamforming for multichannel speech enhancement relies on the estimation of spatial characteristics of the acoustic scene. In its simplest form, the delay-and-sum beamformer (DSB) introduces a time delay to all channels to align the desired signal components for constructive superposition. Recent investigations of neural spatiospectral filtering revealed that these filters can be characterized by a beampattern similar to one of traditional beamformers, which shows that artificial neural networks can learn and explicitly represent spatial structure. Using the Complex-valued Spatial Autoencoder (COSPA) as an exemplary neural spatiospectral filter for multichannel speech enhancement, we investigate where and how such networks represent spatial information. We show via clustering that for COSPA the spatial information is represented by the features generated by a gated recurrent unit (GRU) layer that has access to all channels simultaneously and that these features are not source -- but only direction of arrival-dependent.