 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibhav Vineet
Navigating Hallucinations for Reasoning of Unintentional Activities
Mar 03, 2024
In this work we present a novel task of understanding unintentional human activities in videos. We formalize this problem as a reasoning task under zero-shot scenario, where given a video of an unintentional activity we want to know why it transitioned from intentional to unintentional. We first evaluate the effectiveness of current state-of-the-art Large Multimodal Models on this reasoning task and observe that they suffer from hallucination. We further propose a novel prompting technique,termed as Dream of Thoughts (DoT), which allows the model to navigate through hallucinated thoughts to achieve better reasoning. To evaluate the performance on this task, we also introduce three different specialized metrics designed to quantify the models reasoning capability. We perform our experiments on two different datasets, OOPs and UCF-Crimes, and our findings show that DOT prompting technique is able to outperform standard prompting, while minimizing hallucinations.
DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models
Dec 21, 2023The popularization of Text-to-Image (T2I) diffusion models enables the generation of high-quality images from text descriptions. However, generating diverse customized images with reference visual attributes remains challenging. This work focuses on personalizing T2I diffusion models at a more abstract concept or category level, adapting commonalities from a set of reference images while creating new instances with sufficient variations. We introduce a solution that allows a pretrained T2I diffusion model to learn a set of soft prompts, enabling the generation of novel images by sampling prompts from the learned distribution. These prompts offer text-guided editing capabilities and additional flexibility in controlling variation and mixing between multiple distributions. We also show the adaptability of the learned prompt distribution to other tasks, such as text-to-3D. Finally we demonstrate effectiveness of our approach through quantitative analysis including automatic evaluation and human assessment. Project website: https://briannlongzhao.github.io/DreamDistribution
PEEKABOO: Interactive Video Generation via Masked-Diffusion
Dec 12, 2023Recently there has been a lot of progress in text-to-video generation, with state-of-the-art models being capable of generating high quality, realistic videos. However, these models lack the capability for users to interactively control and generate videos, which can potentially unlock new areas of application. As a first step towards this goal, we tackle the problem of endowing diffusion-based video generation models with interactive spatio-temporal control over their output. To this end, we take inspiration from the recent advances in segmentation literature to propose a novel spatio-temporal masked attention module - Peekaboo. This module is a training-free, no-inference-overhead addition to off-the-shelf video generation models which enables spatio-temporal control. We also propose an evaluation benchmark for the interactive video generation task. Through extensive qualitative and quantitative evaluation, we establish that Peekaboo enables control video generation and even obtains a gain of upto 3.8x in mIoU over baseline models.
DAMEX: Dataset-aware Mixture-of-Experts for visual understanding of mixture-of-datasets
Nov 08, 2023Construction of a universal detector poses a crucial question: How can we most effectively train a model on a large mixture of datasets? The answer lies in learning dataset-specific features and ensembling their knowledge but do all this in a single model. Previous methods achieve this by having separate detection heads on a common backbone but that results in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose Dataset-Aware Mixture-of-Experts, DAMEX where we train the experts to become an `expert' of a dataset by learning to route each dataset tokens to its mapped expert. Experiments on Universal Object-Detection Benchmark show that we outperform the existing state-of-the-art by average +10.2 AP score and improve over our non-MoE baseline by average +2.0 AP score. We also observe consistent gains while mixing datasets with (1) limited availability, (2) disparate domains and (3) divergent label sets. Further, we qualitatively show that DAMEX is robust against expert representation collapse.
Efficiently Robustify Pre-trained Models
Sep 14, 2023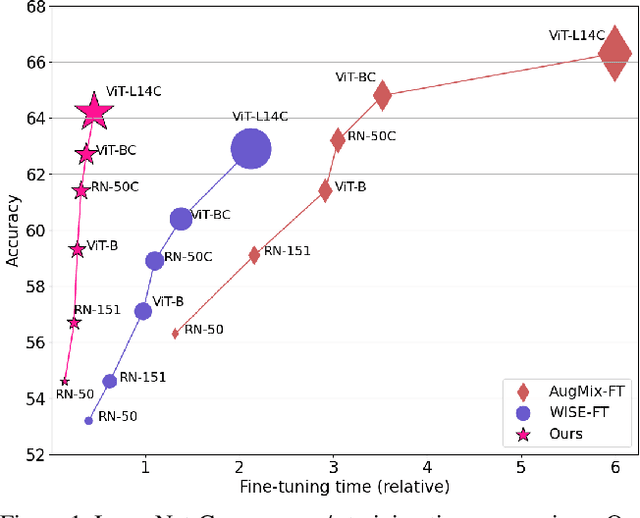

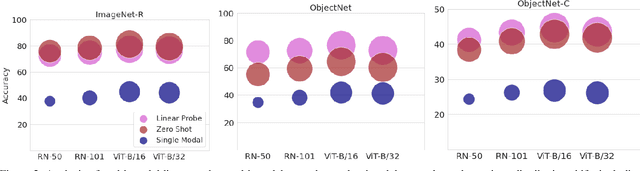

A recent trend in deep learning algorithms has been towards training large scale models, having high parameter count and trained on big dataset. However, robustness of such large scale models towards real-world settings is still a less-explored topic. In this work, we first benchmark the performance of these models under different perturbations and datasets thereby representing real-world shifts, and highlight their degrading performance under these shifts. We then discuss on how complete model fine-tuning based existing robustification schemes might not be a scalable option given very large scale networks and can also lead them to forget some of the desired characterstics. Finally, we propose a simple and cost-effective method to solve this problem, inspired by knowledge transfer literature. It involves robustifying smaller models, at a lower computation cost, and then use them as teachers to tune a fraction of these large scale networks, reducing the overall computational overhead. We evaluate our proposed method under various vision perturbations including ImageNet-C,R,S,A datasets and also for transfer learning, zero-shot evaluation setups on different datasets. Benchmark results show that our method is able to induce robustness to these large scale models efficiently, requiring significantly lower time and also preserves the transfer learning, zero-shot properties of the original model which none of the existing methods are able to achieve.
Beyond Generation: Harnessing Text to Image Models for Object Detection and Segmentation
Sep 12, 2023

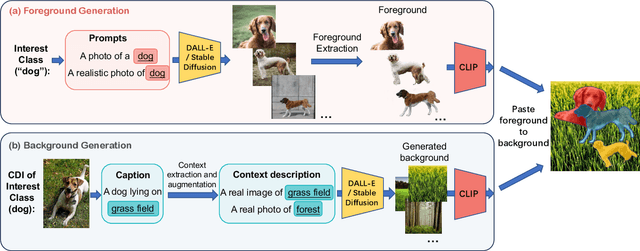

We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-to-image synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach1 decouples training data generation into foreground object generation, and contextually coherent background generation. To generate foreground objects, we employ a straightforward textual template, incorporating the object class name as input prompts. This is fed into a text-to-image synthesis framework, producing various foreground images set against isolated backgrounds. A foreground-background segmentation algorithm is then used to generate foreground object masks. To generate context images, we begin by creating language descriptions of the context. This is achieved by applying an image captioning method to a small set of images representing the desired context. These textual descriptions are then transformed into a diverse array of context images via a text-to-image synthesis framework. Subsequently, we composite these with the foreground object masks produced in the initial step, utilizing a cut-and-paste method, to formulate the training data. We demonstrate the advantages of our approach on five object detection and segmentation datasets, including Pascal VOC and COCO. We found that detectors trained solely on synthetic data produced by our method achieve performance comparable to those trained on real data (Fig. 1). Moreover, a combination of real and synthetic data yields even much better results. Further analysis indicates that the synthetic data distribution complements the real data distribution effectively. Additionally, we emphasize the compositional nature of our data generation approach in out-of-distribution and zero-shot data generation scenarios. We open-source our code at https://github.com/gyhandy/Text2Image-for-Detection
Robustness Analysis on Foundational Segmentation Models
Jun 15, 2023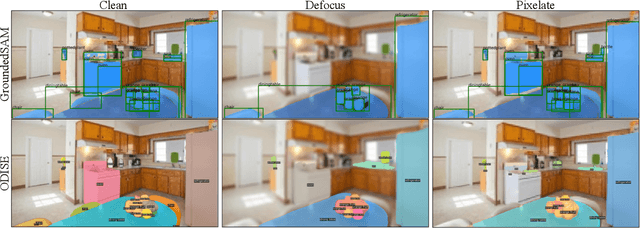


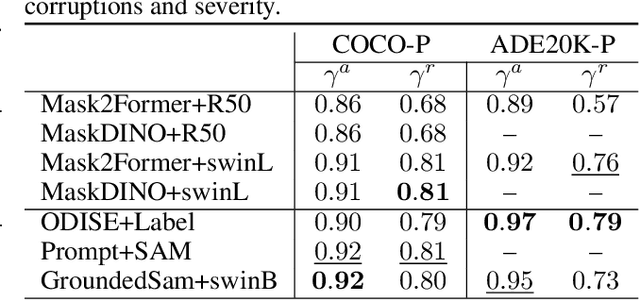
Due to the increase in computational resources and accessibility of data, an increase in large, deep learning models trained on copious amounts of data using self-supervised or semi-supervised learning have emerged. These "foundation" models are often adapted to a variety of downstream tasks like classification, object detection, and segmentation with little-to-no training on the target dataset. In this work, we perform a robustness analysis of Visual Foundation Models (VFMs) for segmentation tasks and compare them to supervised models of smaller scale. We focus on robustness against real-world distribution shift perturbations.We benchmark four state-of-the-art segmentation architectures using 2 different datasets, COCO and ADE20K, with 17 different perturbations with 5 severity levels each. We find interesting insights that include (1) VFMs are not robust to compression-based corruptions, (2) while the selected VFMs do not significantly outperform or exhibit more robustness compared to non-VFM models, they remain competitively robust in zero-shot evaluations, particularly when non-VFM are under supervision and (3) selected VFMs demonstrate greater resilience to specific categories of objects, likely due to their open-vocabulary training paradigm, a feature that non-VFM models typically lack. We posit that the suggested robustness evaluation introduces new requirements for foundational models, thus sparking further research to enhance their performance.
Benchmarking self-supervised video representation learning
Jun 09, 2023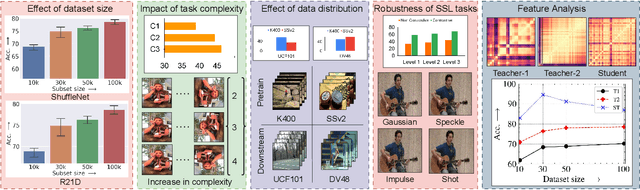
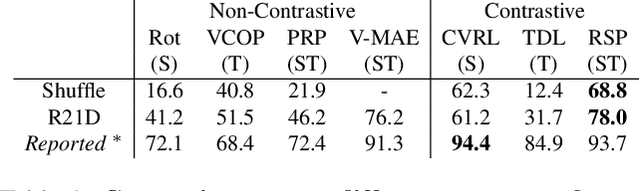

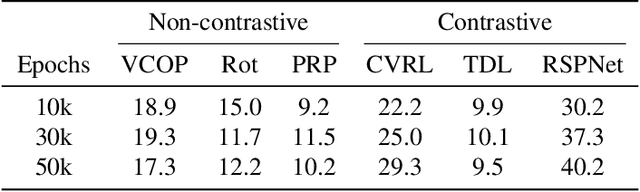
Self-supervised learning is an effective way for label-free model pre-training, especially in the video domain where labeling is expensive. Existing self-supervised works in the video domain use varying experimental setups to demonstrate their effectiveness and comparison across approaches becomes challenging with no standard benchmark. In this work, we first provide a benchmark that enables a comparison of existing approaches on the same ground. Next, we study five different aspects of self-supervised learning important for videos; 1) dataset size, 2) complexity, 3) data distribution, 4) data noise, and, 5)feature analysis. To facilitate this study, we focus on seven different methods along with seven different network architectures and perform an extensive set of experiments on 5 different datasets with an evaluation of two different downstream tasks. We present several interesting insights from this study which span across different properties of pretraining and target datasets, pretext-tasks, and model architectures among others. We further put some of these insights to the real test and propose an approach that requires a limited amount of training data and outperforms existing state-of-the-art approaches which use 10x pretraining data. We believe this work will pave the way for researchers to a better understanding of self-supervised pretext tasks in video representation learning.
Controllable Text-to-Image Generation with GPT-4
May 29, 2023

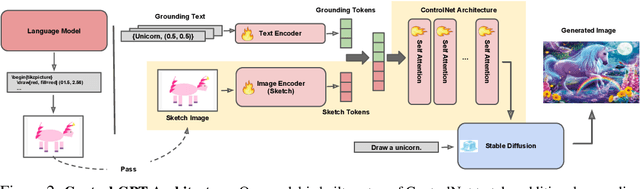

Current text-to-image generation models often struggle to follow textual instructions, especially the ones requiring spatial reasoning. On the other hand, Large Language Models (LLMs), such as GPT-4, have shown remarkable precision in generating code snippets for sketching out text inputs graphically, e.g., via TikZ. In this work, we introduce Control-GPT to guide the diffusion-based text-to-image pipelines with programmatic sketches generated by GPT-4, enhancing their abilities for instruction following. Control-GPT works by querying GPT-4 to write TikZ code, and the generated sketches are used as references alongside the text instructions for diffusion models (e.g., ControlNet) to generate photo-realistic images. One major challenge to training our pipeline is the lack of a dataset containing aligned text, images, and sketches. We address the issue by converting instance masks in existing datasets into polygons to mimic the sketches used at test time. As a result, Control-GPT greatly boosts the controllability of image generation. It establishes a new state-of-art on the spatial arrangement and object positioning generation and enhances users' control of object positions, sizes, etc., nearly doubling the accuracy of prior models. Our work, as a first attempt, shows the potential for employing LLMs to enhance the performance in computer vision tasks.
PLEX: Making the Most of the Available Data for Robotic Manipulation Pretraining
Mar 15, 2023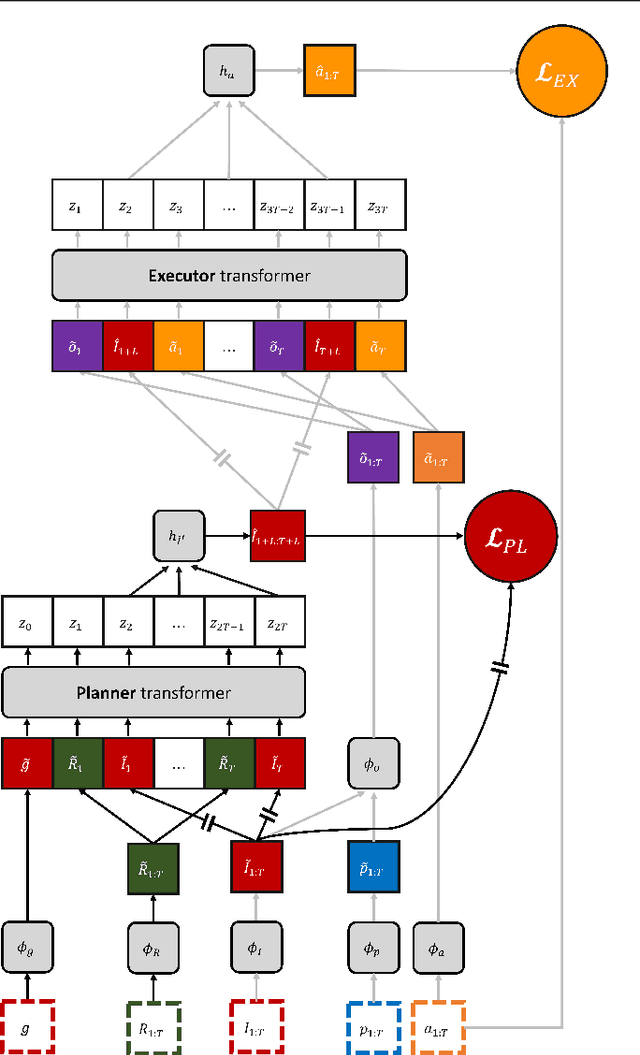

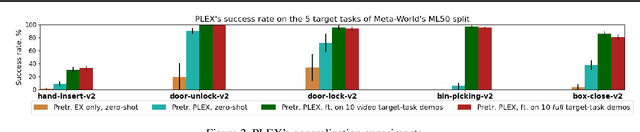

A rich representation is key to general robotic manipulation, but existing model architectures require a lot of data to learn it. Unfortunately, ideal robotic manipulation training data, which comes in the form of expert visuomotor demonstrations for a variety of annotated tasks, is scarce. In this work we propose PLEX, a transformer-based architecture that learns from task-agnostic visuomotor trajectories accompanied by a much larger amount of task-conditioned object manipulation videos -- a type of robotics-relevant data available in quantity. The key insight behind PLEX is that the trajectories with observations and actions help induce a latent feature space and train a robot to execute task-agnostic manipulation routines, while a diverse set of video-only demonstrations can efficiently teach the robot how to plan in this feature space for a wide variety of tasks. In contrast to most works on robotic manipulation pretraining, PLEX learns a generalizable sensorimotor multi-task policy, not just an observational representation. We also show that using relative positional encoding in PLEX's transformers further increases its data efficiency when learning from human-collected demonstrations. Experiments showcase \appr's generalization on Meta-World-v2 benchmark and establish state-of-the-art performance in challenging Robosuite environments.