 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVignesh Prasad
Transition State Clustering for Interaction Segmentation and Learning
Feb 22, 2024
Hidden Markov Models with an underlying Mixture of Gaussian structure have proven effective in learning Human-Robot Interactions from demonstrations for various interactive tasks via Gaussian Mixture Regression. However, a mismatch occurs when segmenting the interaction using only the observed state of the human compared to the joint state of the human and the robot. To enhance this underlying segmentation and subsequently the predictive abilities of such Gaussian Mixture-based approaches, we take a hierarchical approach by learning an additional mixture distribution on the states at the transition boundary. This helps prevent misclassifications that usually occur in such states. We find that our framework improves the performance of the underlying Gaussian Mixture-based approach, which we evaluate on various interactive tasks such as handshaking and fistbumps.
Kinematically Constrained Human-like Bimanual Robot-to-Human Handovers
Feb 22, 2024Bimanual handovers are crucial for transferring large, deformable or delicate objects. This paper proposes a framework for generating kinematically constrained human-like bimanual robot motions to ensure seamless and natural robot-to-human object handovers. We use a Hidden Semi-Markov Model (HSMM) to reactively generate suitable response trajectories for a robot based on the observed human partner's motion. The trajectories are adapted with task space constraints to ensure accurate handovers. Results from a pilot study show that our approach is perceived as more human--like compared to a baseline Inverse Kinematics approach.
Learning Multimodal Latent Dynamics for Human-Robot Interaction
Nov 27, 2023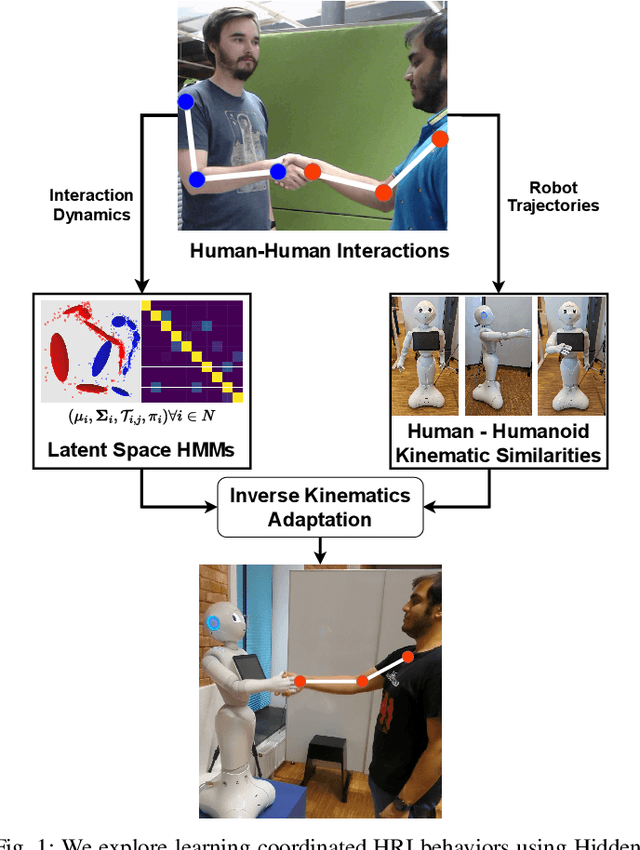

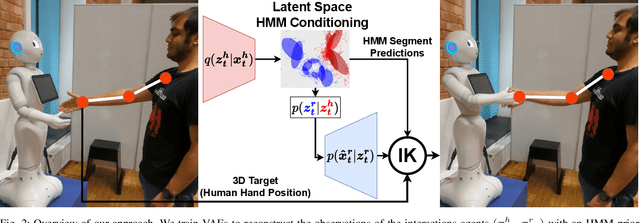
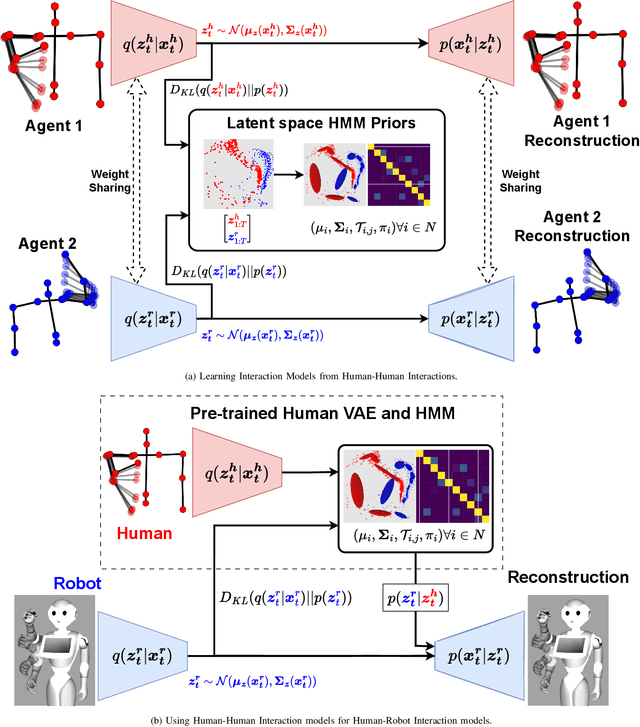
This article presents a method for learning well-coordinated Human-Robot Interaction (HRI) from Human-Human Interactions (HHI). We devise a hybrid approach using Hidden Markov Models (HMMs) as the latent space priors for a Variational Autoencoder to model a joint distribution over the interacting agents. We leverage the interaction dynamics learned from HHI to learn HRI and incorporate the conditional generation of robot motions from human observations into the training, thereby predicting more accurate robot trajectories. The generated robot motions are further adapted with Inverse Kinematics to ensure the desired physical proximity with a human, combining the ease of joint space learning and accurate task space reachability. For contact-rich interactions, we modulate the robot's stiffness using HMM segmentation for a compliant interaction. We verify the effectiveness of our approach deployed on a Humanoid robot via a user study. Our method generalizes well to various humans despite being trained on data from just two humans. We find that Users perceive our method as more human-like, timely, and accurate and rank our method with a higher degree of preference over other baselines.
Learning Human-like Hand Reaching for Human-Robot Handshaking
Feb 28, 2021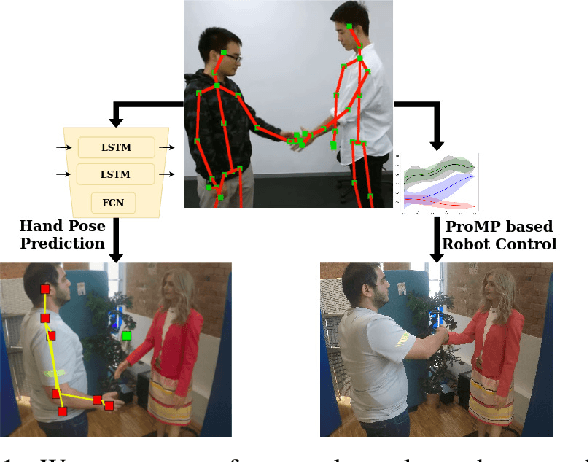
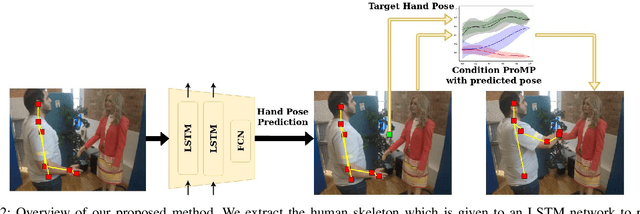


One of the first and foremost non-verbal interactions that humans perform is a handshake. It has an impact on first impressions as touch can convey complex emotions. This makes handshaking an important skill for the repertoire of a social robot. In this paper, we present a novel framework for learning human-robot handshaking behaviours for humanoid robots solely using third-person human-human interaction data. This is especially useful for non-backdrivable robots that cannot be taught by demonstrations via kinesthetic teaching. Our approach can be easily executed on different humanoid robots. This removes the need for re-training, which is especially tedious when training with human-interaction partners. We show this by applying the learnt behaviours on two different humanoid robots with similar degrees of freedom but different shapes and control limits.
Human-Robot Handshaking: A Review
Feb 14, 2021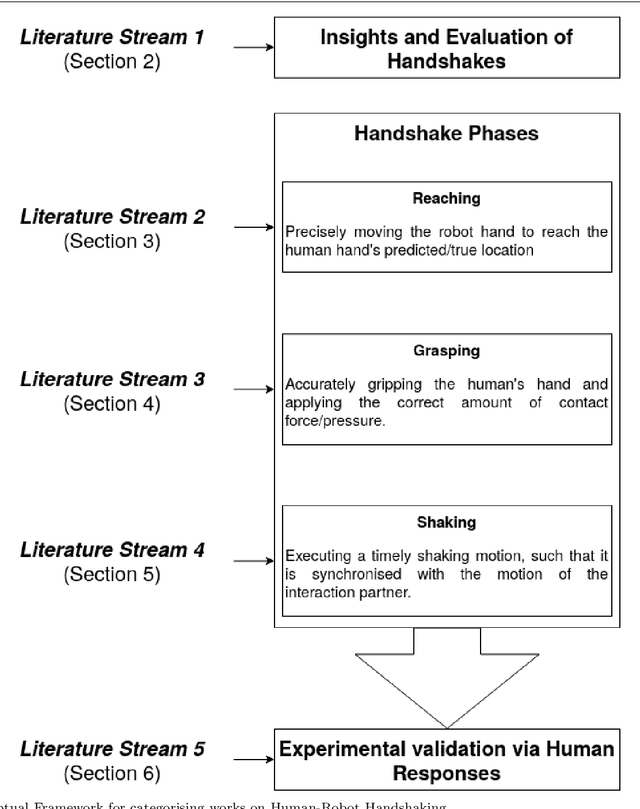

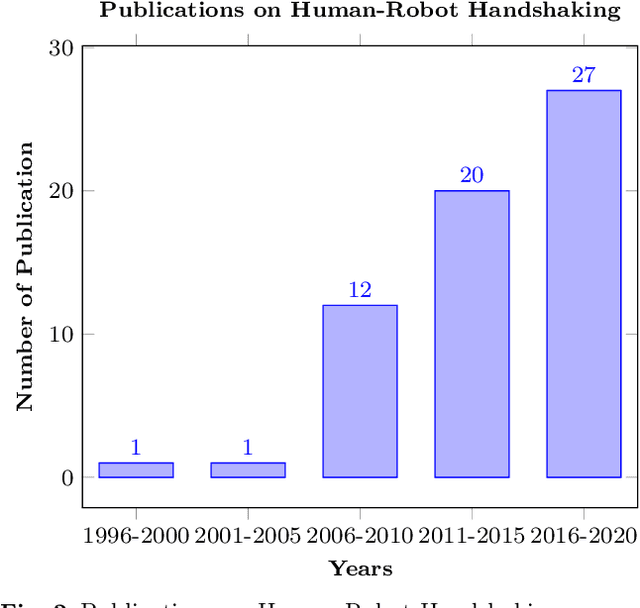
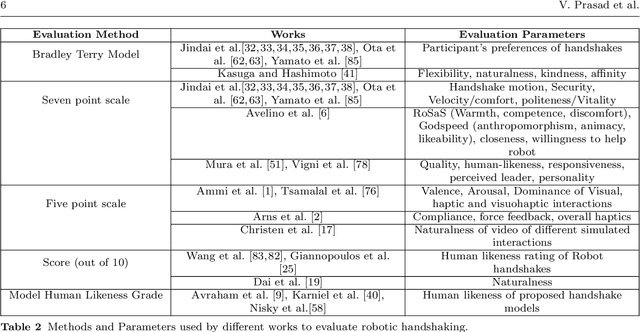
For some years now, the use of social, anthropomorphic robots in various situations has been on the rise. These are robots developed to interact with humans and are equipped with corresponding extremities. They already support human users in various industries, such as retail, gastronomy, hotels, education and healthcare. During such Human-Robot Interaction (HRI) scenarios, physical touch plays a central role in the various applications of social robots as interactive non-verbal behaviour is a key factor in making the interaction more natural. Shaking hands is a simple, natural interaction used commonly in many social contexts and is seen as a symbol of greeting, farewell and congratulations. In this paper, we take a look at the existing state of Human-Robot Handshaking research, categorise the works based on their focus areas, draw out the major findings of these areas while analysing their pitfalls. We mainly see that some form of synchronisation exists during the different phases of the interaction. In addition to this, we also find that additional factors like gaze, voice facial expressions etc. can affect the perception of a robotic handshake and that internal factors like personality and mood can affect the way in which handshaking behaviours are executed by humans. Based on the findings and insights, we finally discuss possible ways forward for research on such physically interactive behaviours.
Advances in Human-Robot Handshaking
Aug 26, 2020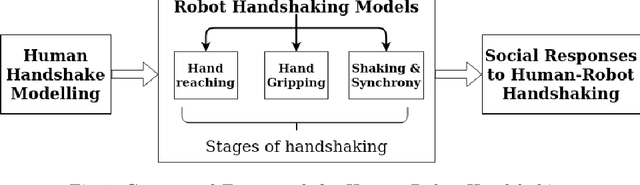
The use of social, anthropomorphic robots to support humans in various industries has been on the rise. During Human-Robot Interaction (HRI), physically interactive non-verbal behaviour is key for more natural interactions. Handshaking is one such natural interaction used commonly in many social contexts. It is one of the first non-verbal interactions which takes place and should, therefore, be part of the repertoire of a social robot. In this paper, we explore the existing state of Human-Robot Handshaking and discuss possible ways forward for such physically interactive behaviours.
Variational Clustering: Leveraging Variational Autoencoders for Image Clustering
May 10, 2020
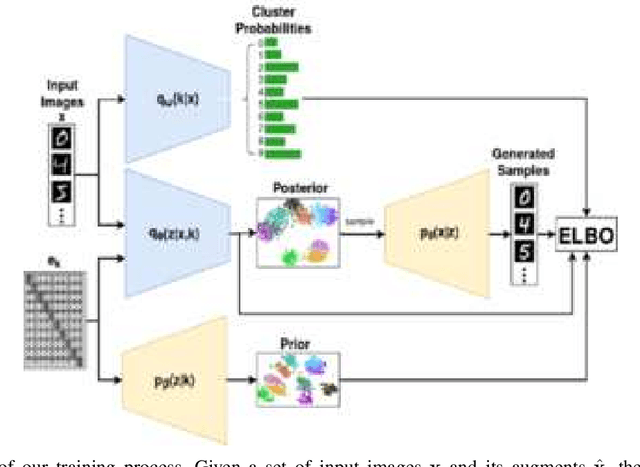
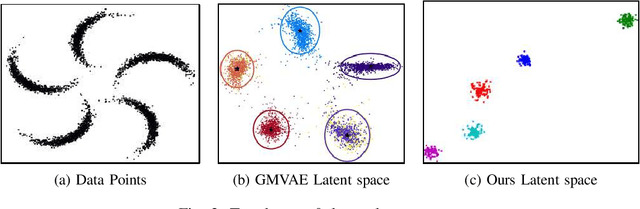
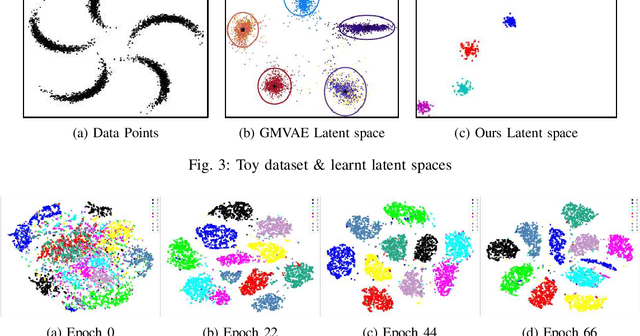
Recent advances in deep learning have shown their ability to learn strong feature representations for images. The task of image clustering naturally requires good feature representations to capture the distribution of the data and subsequently differentiate data points from one another. Often these two aspects are dealt with independently and thus traditional feature learning alone does not suffice in partitioning the data meaningfully. Variational Autoencoders (VAEs) naturally lend themselves to learning data distributions in a latent space. Since we wish to efficiently discriminate between different clusters in the data, we propose a method based on VAEs where we use a Gaussian Mixture prior to help cluster the images accurately. We jointly learn the parameters of both the prior and the posterior distributions. Our method represents a true Gaussian Mixture VAE. This way, our method simultaneously learns a prior that captures the latent distribution of the images and a posterior to help discriminate well between data points. We also propose a novel reparametrization of the latent space consisting of a mixture of discrete and continuous variables. One key takeaway is that our method generalizes better across different datasets without using any pre-training or learnt models, unlike existing methods, allowing it to be trained from scratch in an end-to-end manner. We verify our efficacy and generalizability experimentally by achieving state-of-the-art results among unsupervised methods on a variety of datasets. To the best of our knowledge, we are the first to pursue image clustering using VAEs in a purely unsupervised manner on real image datasets.
Evaluation of the Handshake Turing Test for anthropomorphic Robots
Jan 28, 2020
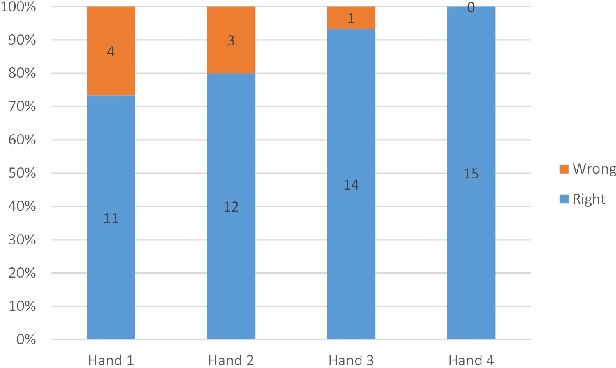
Handshakes are fundamental and common greeting and parting gestures among humans. They are important in shaping first impressions as people tend to associate character traits with a person's handshake. To widen the social acceptability of robots and make a lasting first impression, a good handshaking ability is an important skill for social robots. Therefore, to test the human-likeness of a robot handshake, we propose an initial Turing-like test, primarily for the hardware interface to future AI agents. We evaluate the test on an android robot's hand to determine if it can pass for a human hand. This is an important aspect of Turing tests for motor intelligence where humans have to interact with a physical device rather than a virtual one. We also propose some modifications to the definition of a Turing test for such scenarios taking into account that a human needs to interact with a physical medium.
Epipolar Geometry based Learning of Multi-view Depth and Ego-Motion from Monocular Sequences
Jan 07, 2019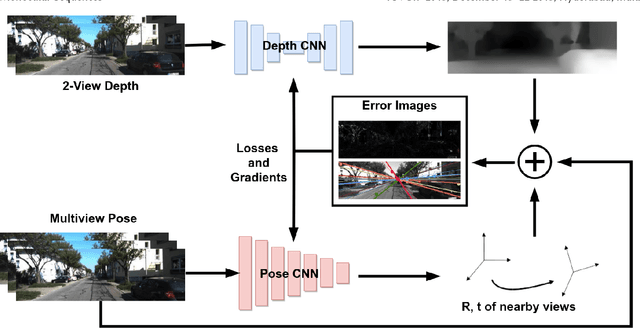
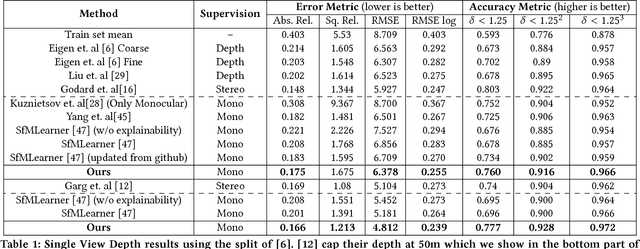

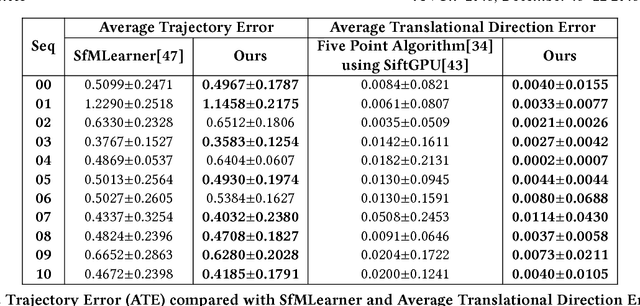
Deep approaches to predict monocular depth and ego-motion have grown in recent years due to their ability to produce dense depth from monocular images. The main idea behind them is to optimize the photometric consistency over image sequences by warping one view into another, similar to direct visual odometry methods. One major drawback is that these methods infer depth from a single view, which might not effectively capture the relation between pixels. Moreover, simply minimizing the photometric loss does not ensure proper pixel correspondences, which is a key factor for accurate depth and pose estimations. In contrast, we propose a 2-view depth network to infer the scene depth from consecutive frames, thereby learning inter-pixel relationships. To ensure better correspondences, thereby better geometric understanding, we propose incorporating epipolar constraints to make the learning more geometrically sound. We use the Essential matrix obtained using Nist'er's Five Point Algorithm, to enforce meaningful geometric constraints, rather than using it as training labels. This allows us to use lesser no. of trainable parameters compared to state-of-the-art methods. The proposed method results in better depth images and pose estimates, which capture the scene structure and motion in a better way. Such a geometrically constrained learning performs successfully even in cases where simply minimizing the photometric error would fail.
Learning to Prevent Monocular SLAM Failure using Reinforcement Learning
Dec 23, 2018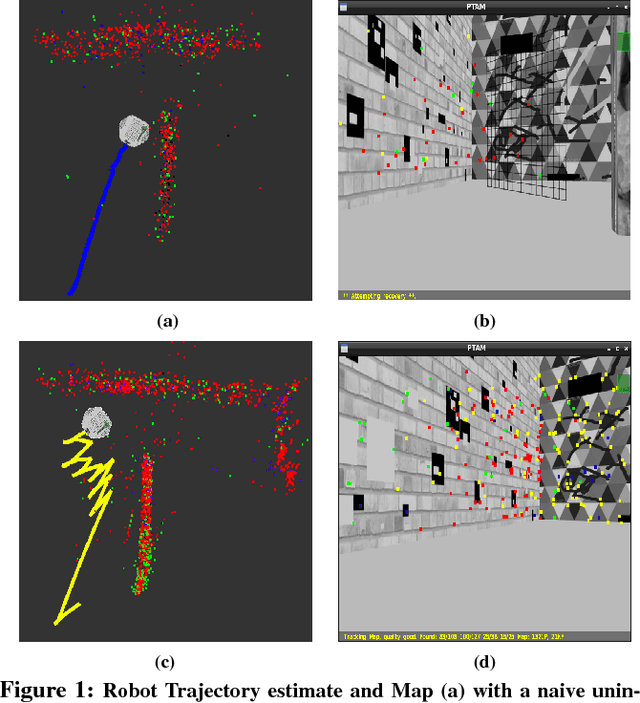

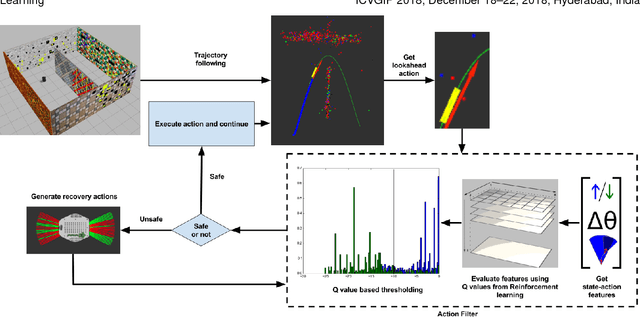
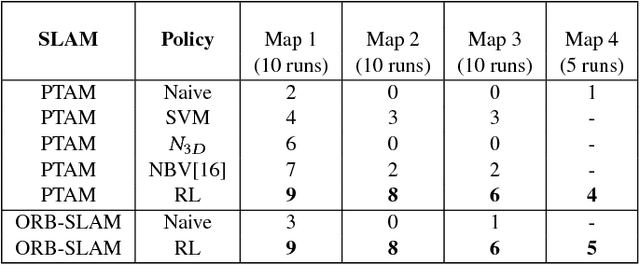
Monocular SLAM refers to using a single camera to estimate robot ego motion while building a map of the environment. While Monocular SLAM is a well studied problem, automating Monocular SLAM by integrating it with trajectory planning frameworks is particularly challenging. This paper presents a novel formulation based on Reinforcement Learning (RL) that generates fail safe trajectories wherein the SLAM generated outputs do not deviate largely from their true values. Quintessentially, the RL framework successfully learns the otherwise complex relation between perceptual inputs and motor actions and uses this knowledge to generate trajectories that do not cause failure of SLAM. We show systematically in simulations how the quality of the SLAM dramatically improves when trajectories are computed using RL. Our method scales effectively across Monocular SLAM frameworks in both simulation and in real world experiments with a mobile robot.