 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVikas Sindhwani
Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
Apr 04, 2024
We present an embodied AI system which receives open-ended natural language instructions from a human, and controls two arms to collaboratively accomplish potentially long-horizon tasks over a large workspace. Our system is modular: it deploys state of the art Large Language Models for task planning,Vision-Language models for semantic perception, and Point Cloud transformers for grasping. With semantic and physical safety in mind, these modules are interfaced with a real-time trajectory optimizer and a compliant tracking controller to enable human-robot proximity. We demonstrate performance for the following tasks: bi-arm sorting, bottle opening, and trash disposal tasks. These are done zero-shot where the models used have not been trained with any real world data from this bi-arm robot, scenes or workspace.Composing both learning- and non-learning-based components in a modular fashion with interpretable inputs and outputs allows the user to easily debug points of failures and fragilities. One may also in-place swap modules to improve the robustness of the overall platform, for instance with imitation-learned policies.
SARA-RT: Scaling up Robotics Transformers with Self-Adaptive Robust Attention
Dec 04, 2023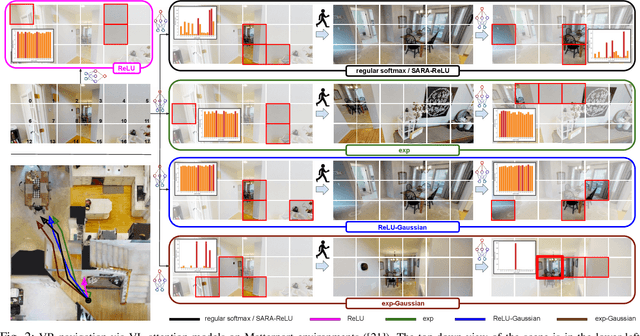

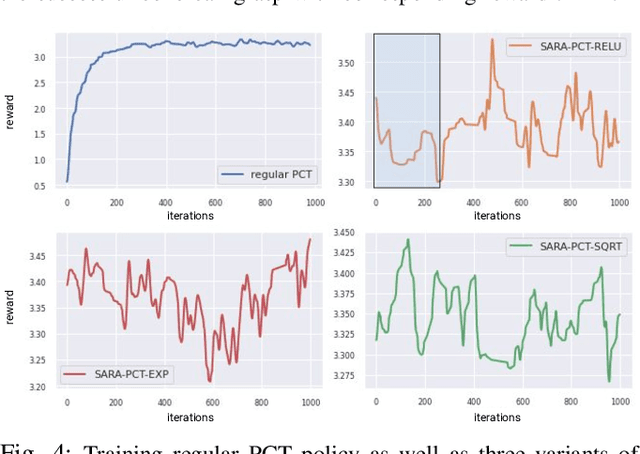

We present Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT): a new paradigm for addressing the emerging challenge of scaling up Robotics Transformers (RT) for on-robot deployment. SARA-RT relies on the new method of fine-tuning proposed by us, called up-training. It converts pre-trained or already fine-tuned Transformer-based robotic policies of quadratic time complexity (including massive billion-parameter vision-language-action models or VLAs), into their efficient linear-attention counterparts maintaining high quality. We demonstrate the effectiveness of SARA-RT by speeding up: (a) the class of recently introduced RT-2 models, the first VLA robotic policies pre-trained on internet-scale data, as well as (b) Point Cloud Transformer (PCT) robotic policies operating on large point clouds. We complement our results with the rigorous mathematical analysis providing deeper insight into the phenomenon of SARA.
Revisiting Energy Based Models as Policies: Ranking Noise Contrastive Estimation and Interpolating Energy Models
Sep 11, 2023A crucial design decision for any robot learning pipeline is the choice of policy representation: what type of model should be used to generate the next set of robot actions? Owing to the inherent multi-modal nature of many robotic tasks, combined with the recent successes in generative modeling, researchers have turned to state-of-the-art probabilistic models such as diffusion models for policy representation. In this work, we revisit the choice of energy-based models (EBM) as a policy class. We show that the prevailing folklore -- that energy models in high dimensional continuous spaces are impractical to train -- is false. We develop a practical training objective and algorithm for energy models which combines several key ingredients: (i) ranking noise contrastive estimation (R-NCE), (ii) learnable negative samplers, and (iii) non-adversarial joint training. We prove that our proposed objective function is asymptotically consistent and quantify its limiting variance. On the other hand, we show that the Implicit Behavior Cloning (IBC) objective is actually biased even at the population level, providing a mathematical explanation for the poor performance of IBC trained energy policies in several independent follow-up works. We further extend our algorithm to learn a continuous stochastic process that bridges noise and data, modeling this process with a family of EBMs indexed by scale variable. In doing so, we demonstrate that the core idea behind recent progress in generative modeling is actually compatible with EBMs. Altogether, our proposed training algorithms enable us to train energy-based models as policies which compete with -- and even outperform -- diffusion models and other state-of-the-art approaches in several challenging multi-modal benchmarks: obstacle avoidance path planning and contact-rich block pushing.
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023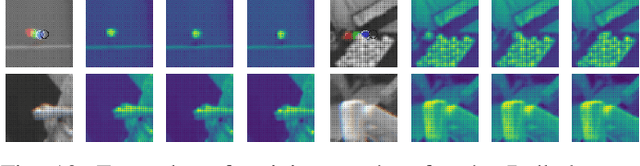

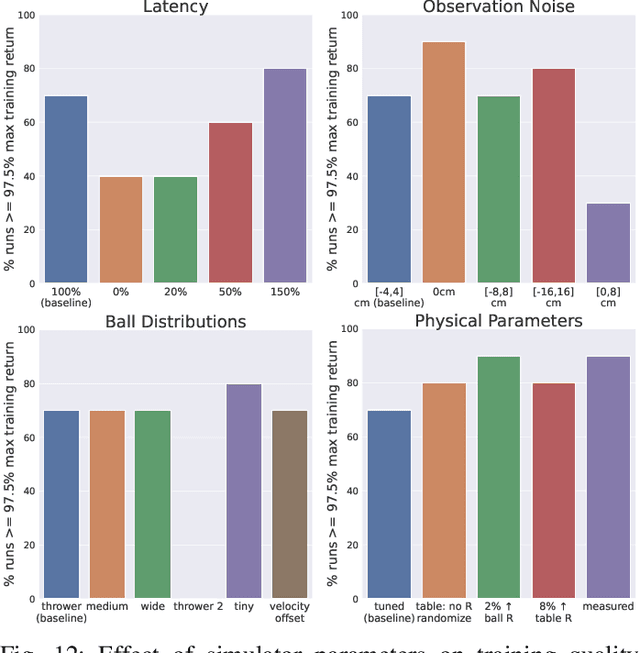
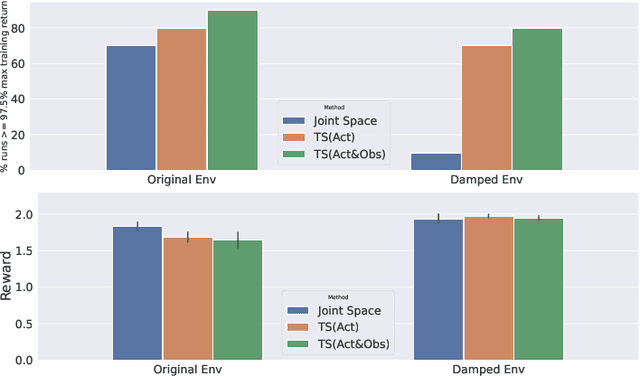
We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Agile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023
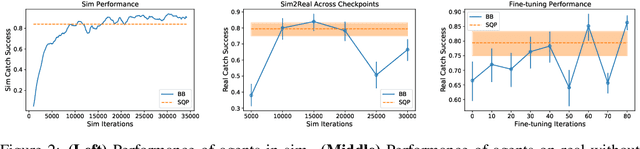
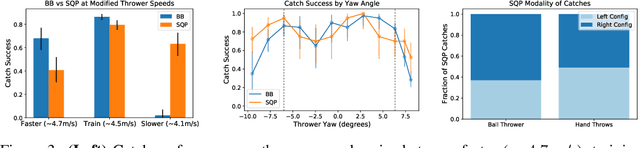
We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
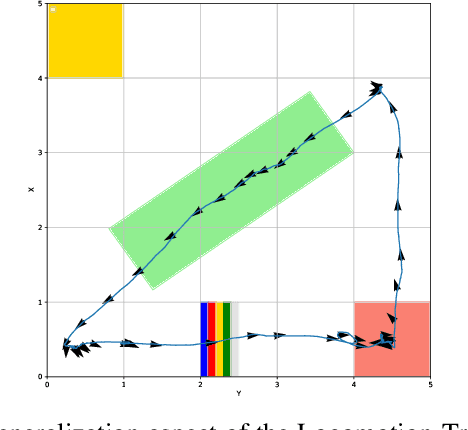
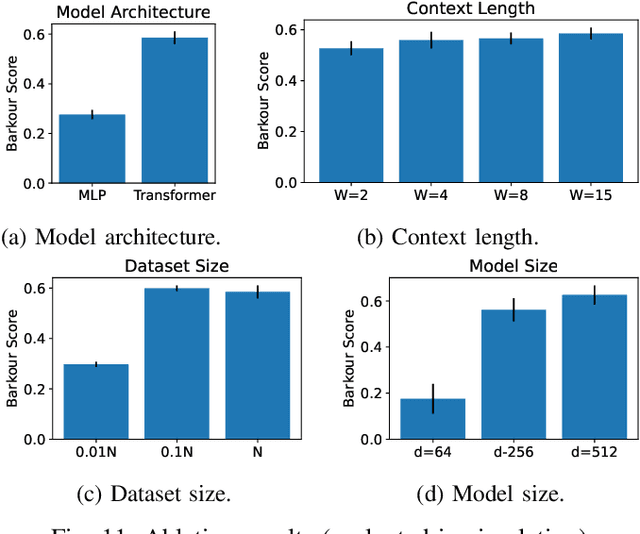

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Safely Learning Dynamical Systems
May 20, 2023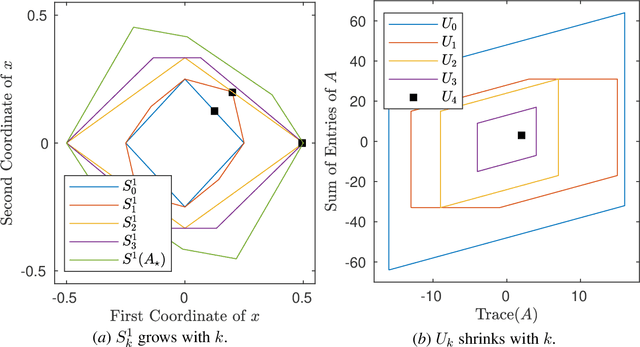
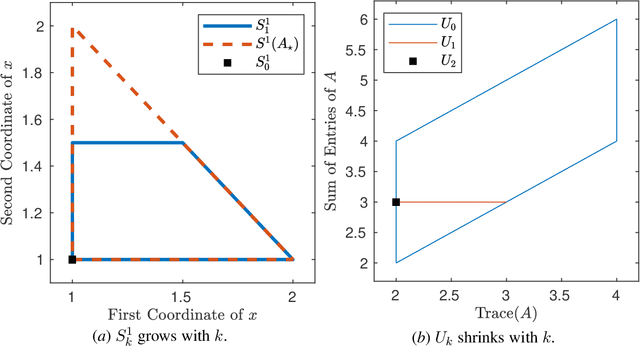
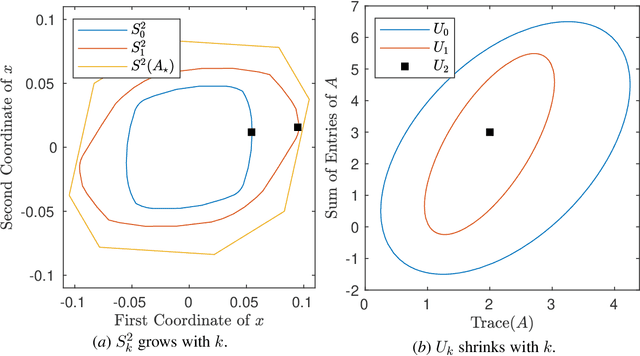
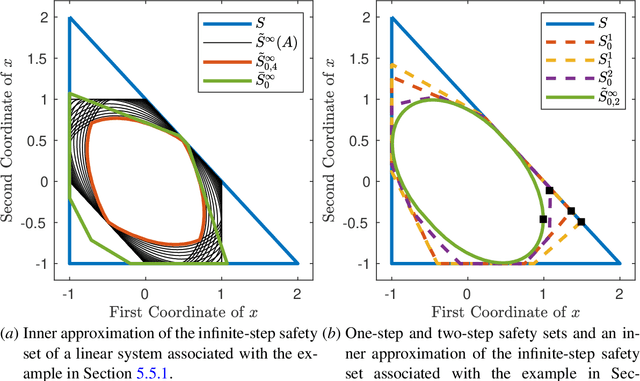
A fundamental challenge in learning an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. In this work, we formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize the next trajectory. In our framework, the state of the system is required to stay within a safety region for a horizon of $T$ time steps under the action of all dynamical systems that (i) belong to a given initial uncertainty set, and (ii) are consistent with the information gathered so far. For our first set of results, we consider the setting of safely learning a linear dynamical system involving $n$ states. For the case $T=1$, we present a linear programming-based algorithm that either safely recovers the true dynamics from at most $n$ trajectories, or certifies that safe learning is impossible. For $T=2$, we give a semidefinite representation of the set of safe initial conditions and show that $\lceil n/2 \rceil$ trajectories generically suffice for safe learning. Finally, for $T = \infty$, we provide semidefinite representable inner approximations of the set of safe initial conditions and show that one trajectory generically suffices for safe learning. Our second set of results concerns the problem of safely learning a general class of nonlinear dynamical systems. For the case $T=1$, we give a second-order cone programming based representation of the set of safe initial conditions. For $T=\infty$, we provide semidefinite representable inner approximations to the set of safe initial conditions. We show how one can safely collect trajectories and fit a polynomial model of the nonlinear dynamics that is consistent with the initial uncertainty set and best agrees with the observations.
Mnemosyne: Learning to Train Transformers with Transformers
Feb 02, 2023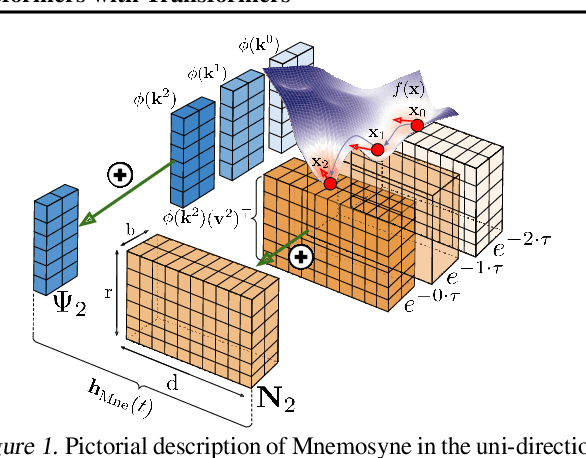

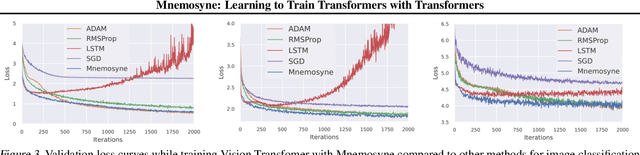
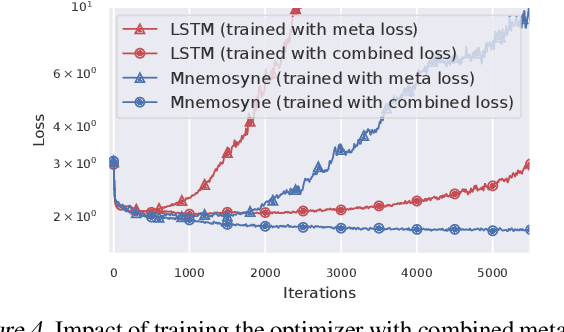
Training complex machine learning (ML) architectures requires a compute and time consuming process of selecting the right optimizer and tuning its hyper-parameters. A new paradigm of learning optimizers from data has emerged as a better alternative to hand-designed ML optimizers. We propose Mnemosyne optimizer, that uses Performers: implicit low-rank attention Transformers. It can learn to train entire neural network architectures including other Transformers without any task-specific optimizer tuning. We show that Mnemosyne: (a) generalizes better than popular LSTM optimizer, (b) in particular can successfully train Vision Transformers (ViTs) while meta--trained on standard MLPs and (c) can initialize optimizers for faster convergence in Robotics applications. We believe that these results open the possibility of using Transformers to build foundational optimization models that can address the challenges of regular Transformer training. We complement our results with an extensive theoretical analysis of the compact associative memory used by Mnemosyne.
Single-Level Differentiable Contact Simulation
Dec 13, 2022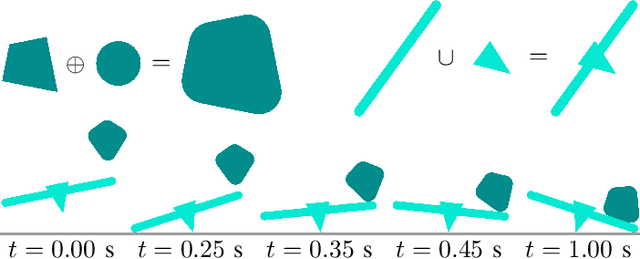
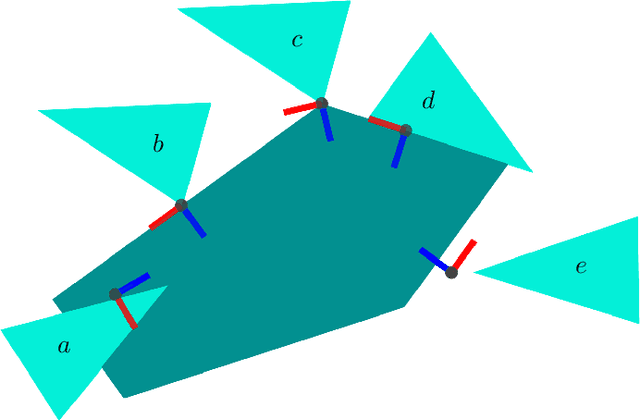
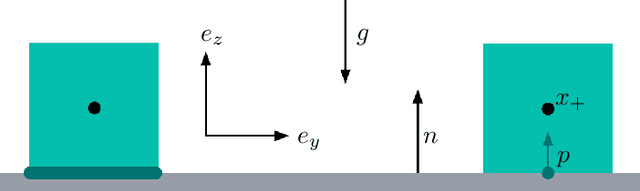

We present a differentiable formulation of rigid-body contact dynamics for objects and robots represented as compositions of convex primitives. Existing optimization-based approaches simulating contact between convex primitives rely on a bilevel formulation that separates collision detection and contact simulation. These approaches are unreliable in realistic contact simulation scenarios because isolating the collision detection problem introduces contact location non-uniqueness. Our approach combines contact simulation and collision detection into a unified single-level optimization problem. This disambiguates the collision detection problem in a physics-informed manner. Compared to previous differentiable simulation approaches, our formulation features improved simulation robustness and a reduction in computational complexity by more than an order of magnitude. We illustrate the contact and collision differentiability on a robotic manipulation task requiring optimization-through-contact. We provide a numerically efficient implementation of our formulation in the Julia language called Silico.jl.
A Contextual Bandit Approach for Learning to Plan in Environments with Probabilistic Goal Configurations
Nov 29, 2022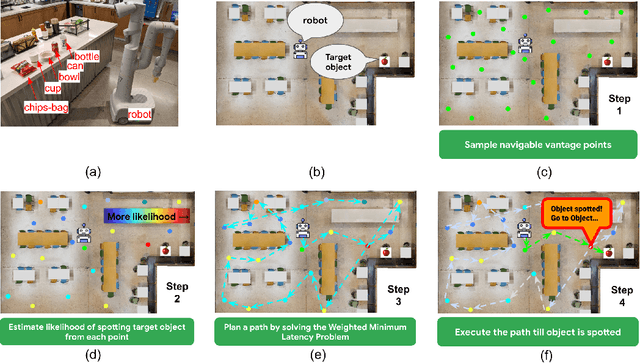

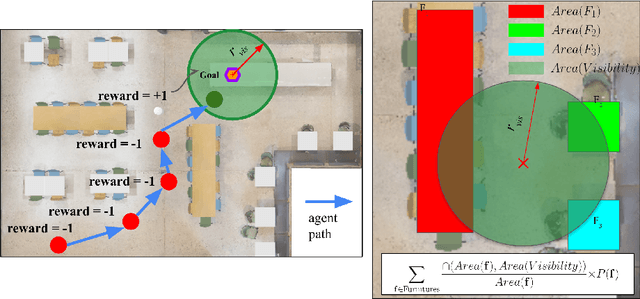
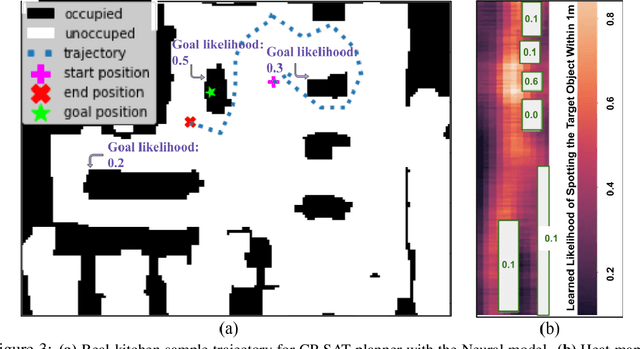
Object-goal navigation (Object-nav) entails searching, recognizing and navigating to a target object. Object-nav has been extensively studied by the Embodied-AI community, but most solutions are often restricted to considering static objects (e.g., television, fridge, etc.). We propose a modular framework for object-nav that is able to efficiently search indoor environments for not just static objects but also movable objects (e.g. fruits, glasses, phones, etc.) that frequently change their positions due to human intervention. Our contextual-bandit agent efficiently explores the environment by showing optimism in the face of uncertainty and learns a model of the likelihood of spotting different objects from each navigable location. The likelihoods are used as rewards in a weighted minimum latency solver to deduce a trajectory for the robot. We evaluate our algorithms in two simulated environments and a real-world setting, to demonstrate high sample efficiency and reliability.