 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVikram Sharma Mailthody
Accelerating Sampling and Aggregation Operations in GNN Frameworks with GPU Initiated Direct Storage Accesses
Jun 28, 2023
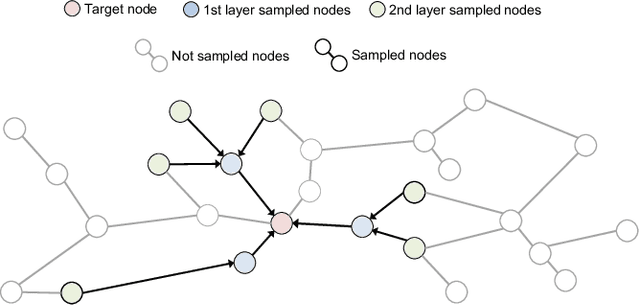

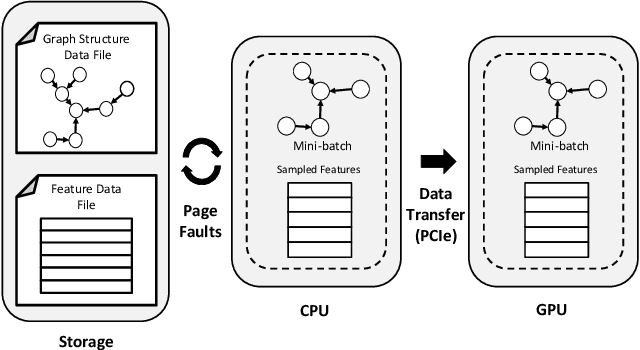
Graph Neural Networks (GNNs) are emerging as a powerful tool for learning from graph-structured data and performing sophisticated inference tasks in various application domains. Although GNNs have been shown to be effective on modest-sized graphs, training them on large-scale graphs remains a significant challenge due to lack of efficient data access and data movement methods. Existing frameworks for training GNNs use CPUs for graph sampling and feature aggregation, while the training and updating of model weights are executed on GPUs. However, our in-depth profiling shows the CPUs cannot achieve the throughput required to saturate GNN model training throughput, causing gross under-utilization of expensive GPU resources. Furthermore, when the graph and its embeddings do not fit in the CPU memory, the overhead introduced by the operating system, say for handling page-faults, comes in the critical path of execution. To address these issues, we propose the GPU Initiated Direct Storage Access (GIDS) dataloader, to enable GPU-oriented GNN training for large-scale graphs while efficiently utilizing all hardware resources, such as CPU memory, storage, and GPU memory with a hybrid data placement strategy. By enabling GPU threads to fetch feature vectors directly from storage, GIDS dataloader solves the memory capacity problem for GPU-oriented GNN training. Moreover, GIDS dataloader leverages GPU parallelism to tolerate storage latency and eliminates expensive page-fault overhead. Doing so enables us to design novel optimizations for exploiting locality and increasing effective bandwidth for GNN training. Our evaluation using a single GPU on terabyte-scale GNN datasets shows that GIDS dataloader accelerates the overall DGL GNN training pipeline by up to 392X when compared to the current, state-of-the-art DGL dataloader.
IGB: Addressing The Gaps In Labeling, Features, Heterogeneity, and Size of Public Graph Datasets for Deep Learning Research
Feb 27, 2023
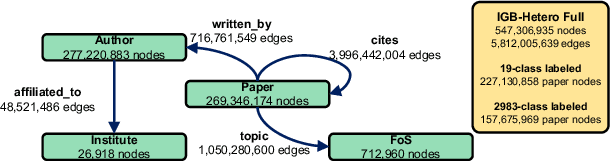

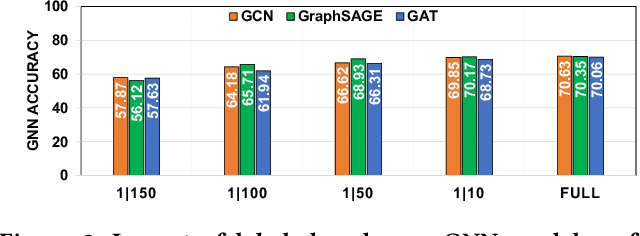
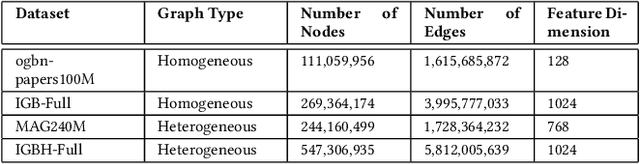
Graph neural networks (GNNs) have shown high potential for a variety of real-world, challenging applications, but one of the major obstacles in GNN research is the lack of large-scale flexible datasets. Most existing public datasets for GNNs are relatively small, which limits the ability of GNNs to generalize to unseen data. The few existing large-scale graph datasets provide very limited labeled data. This makes it difficult to determine if the GNN model's low accuracy for unseen data is inherently due to insufficient training data or if the model failed to generalize. Additionally, datasets used to train GNNs need to offer flexibility to enable a thorough study of the impact of various factors while training GNN models. In this work, we introduce the Illinois Graph Benchmark (IGB), a research dataset tool that the developers can use to train, scrutinize and systematically evaluate GNN models with high fidelity. IGB includes both homogeneous and heterogeneous graphs of enormous sizes, with more than 40% of their nodes labeled. Compared to the largest graph datasets publicly available, the IGB provides over 162X more labeled data for deep learning practitioners and developers to create and evaluate models with higher accuracy. The IGB dataset is designed to be flexible, enabling the study of various GNN architectures, embedding generation techniques, and analyzing system performance issues. IGB is open-sourced, supports DGL and PyG frameworks, and comes with releases of the raw text that we believe foster emerging language models and GNN research projects. An early public version of IGB is available at https://github.com/IllinoisGraphBenchmark/IGB-Datasets.
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020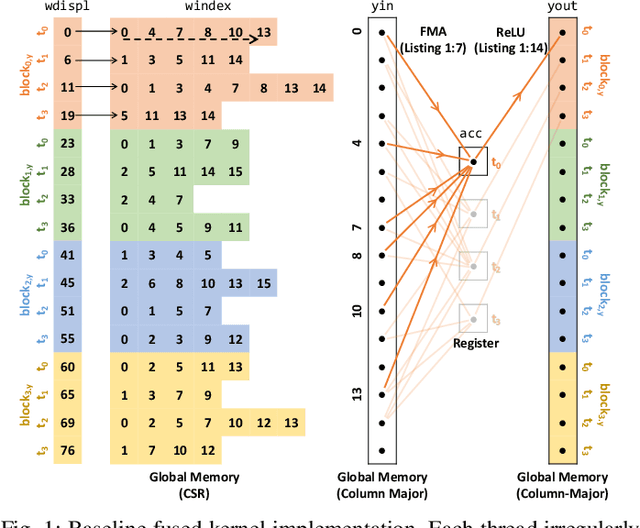
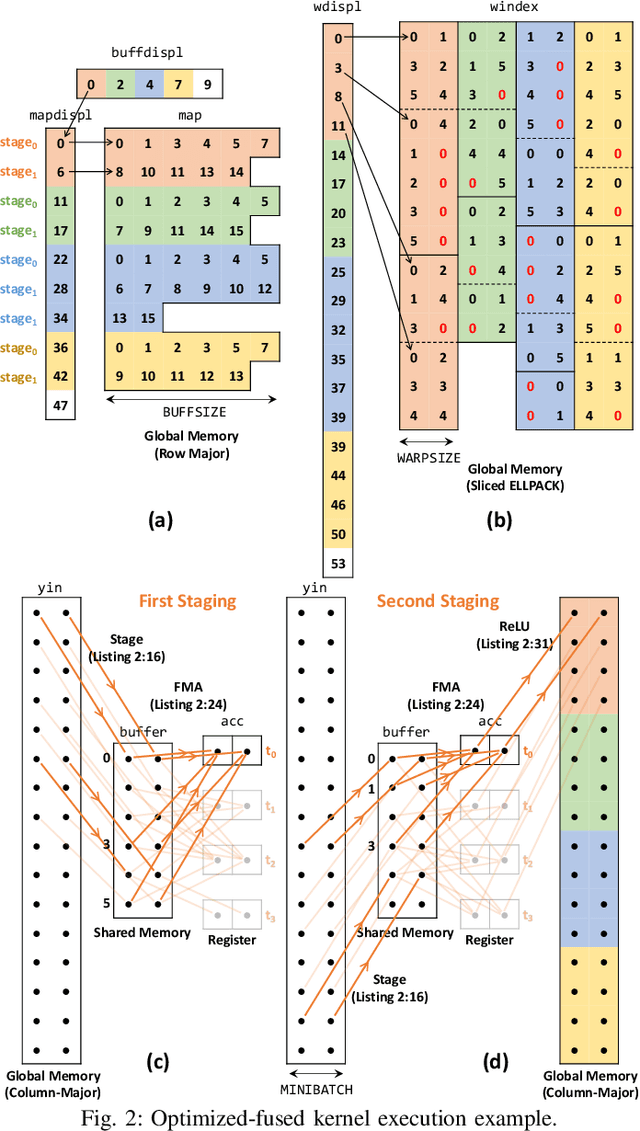
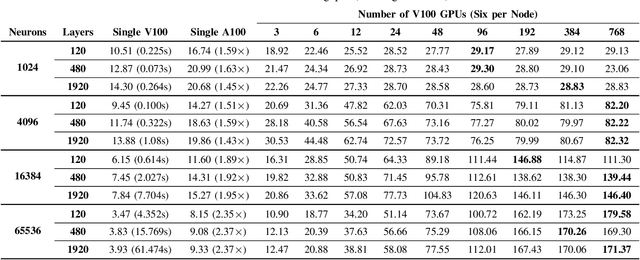
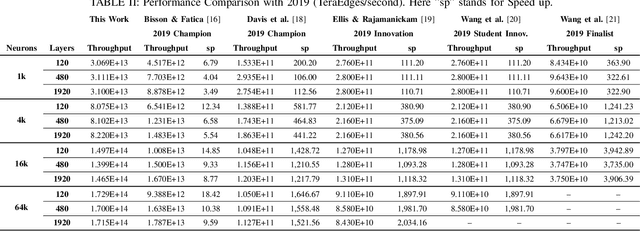
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages
I-BERT: Inductive Generalization of Transformer to Arbitrary Context Lengths
Jun 19, 2020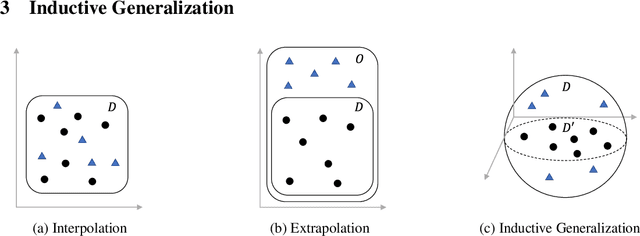
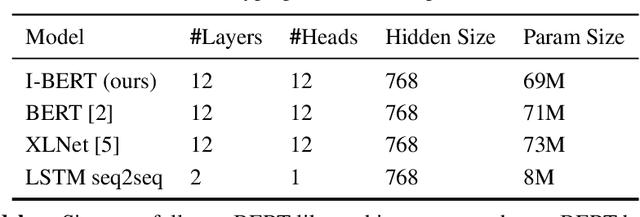
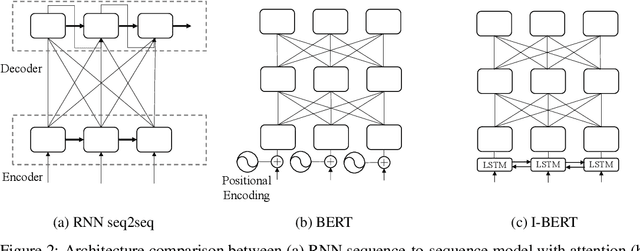
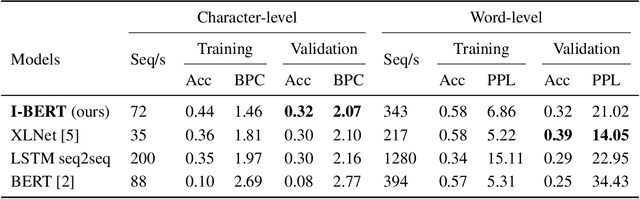
Self-attention has emerged as a vital component of state-of-the-art sequence-to-sequence models for natural language processing in recent years, brought to the forefront by pre-trained bi-directional Transformer models. Its effectiveness is partly due to its non-sequential architecture, which promotes scalability and parallelism but limits the model to inputs of a bounded length. In particular, such architectures perform poorly on algorithmic tasks, where the model must learn a procedure which generalizes to input lengths unseen in training, a capability we refer to as inductive generalization. Identifying the computational limits of existing self-attention mechanisms, we propose I-BERT, a bi-directional Transformer that replaces positional encodings with a recurrent layer. The model inductively generalizes on a variety of algorithmic tasks where state-of-the-art Transformer models fail to do so. We also test our method on masked language modeling tasks where training and validation sets are partitioned to verify inductive generalization. Out of three algorithmic and two natural language inductive generalization tasks, I-BERT achieves state-of-the-art results on four tasks.