 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVinh Tran
Attentive Action and Context Factorization
Apr 10, 2019
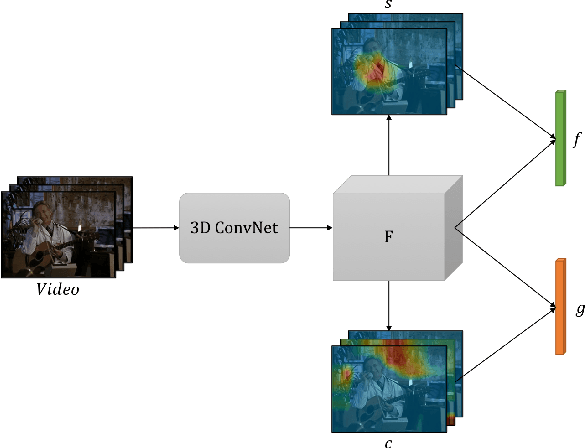
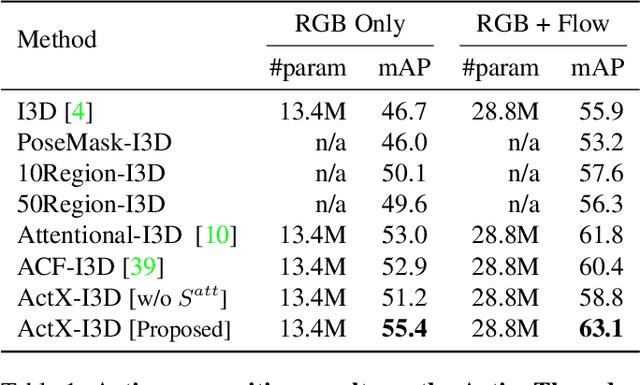
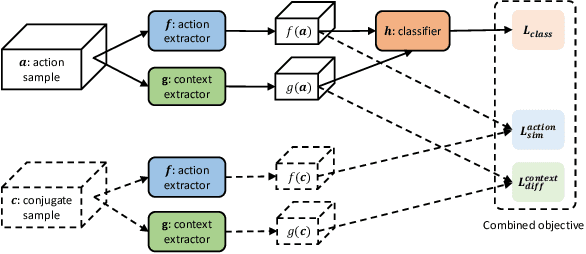
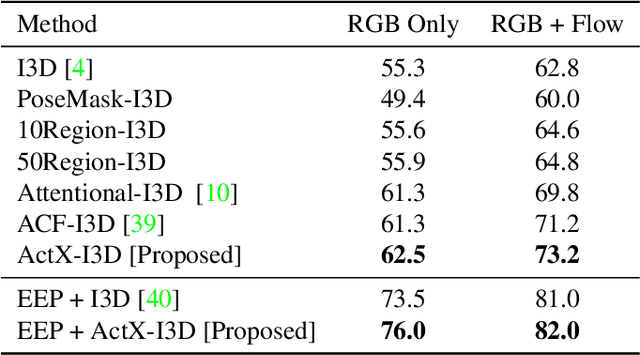
We propose a method for human action recognition, one that can localize the spatiotemporal regions that `define' the actions. This is a challenging task due to the subtlety of human actions in video and the co-occurrence of contextual elements. To address this challenge, we utilize conjugate samples of human actions, which are video clips that are contextually similar to human action samples but do not contain the action. We introduce a novel attentional mechanism that can spatially and temporally separate human actions from the co-occurring contextual factors. The separation of the action and context factors is weakly supervised, eliminating the need for laboriously detailed annotation of these two factors in training samples. Our method can be used to build human action classifiers with higher accuracy and better interpretability. Experiments on several human action recognition datasets demonstrate the quantitative and qualitative benefits of our approach.
Back to the Future: Knowledge Distillation for Human Action Anticipation
Apr 09, 2019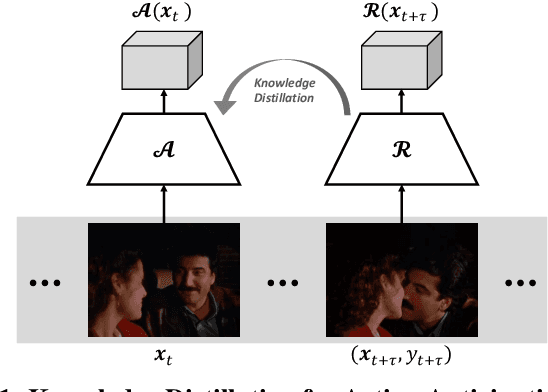
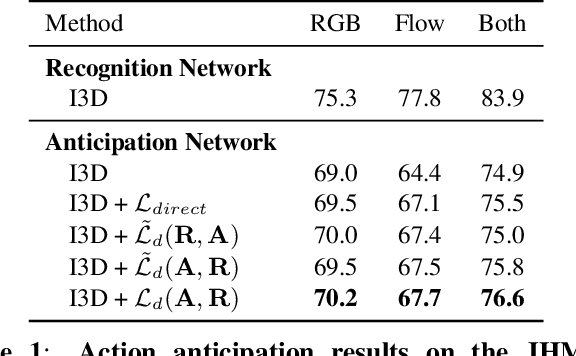
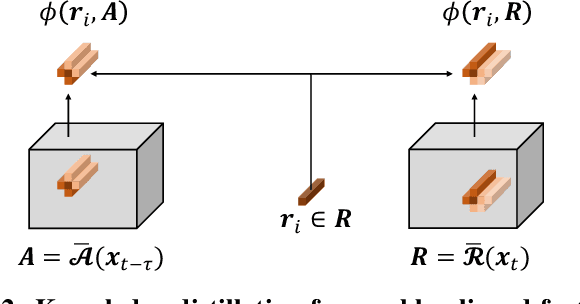

We consider the task of training a neural network to anticipate human actions in video. This task is challenging given the complexity of video data, the stochastic nature of the future, and the limited amount of annotated training data. In this paper, we propose a novel knowledge distillation framework that uses an action recognition network to supervise the training of an action anticipation network, guiding the latter to attend to the relevant information needed for correctly anticipating the future actions. This framework is possible thanks to a novel loss function to account for positional shifts of semantic concepts in a dynamic video. The knowledge distillation framework is a form of self-supervised learning, and it takes advantage of unlabeled data. Experimental results on JHMDB and EPIC-KITCHENS dataset show the effectiveness of our approach.
Eigen Evolution Pooling for Human Action Recognition
Aug 17, 2017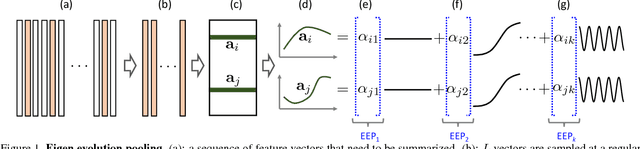
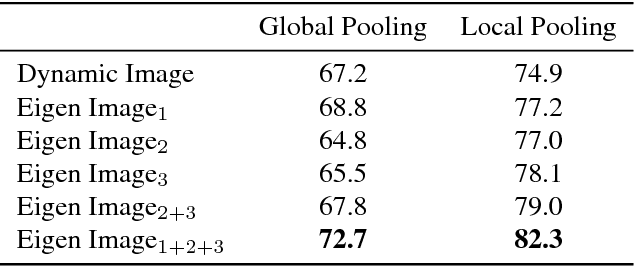
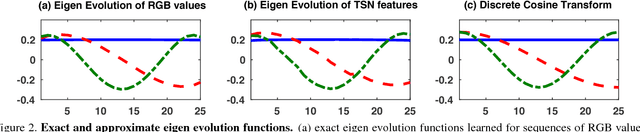
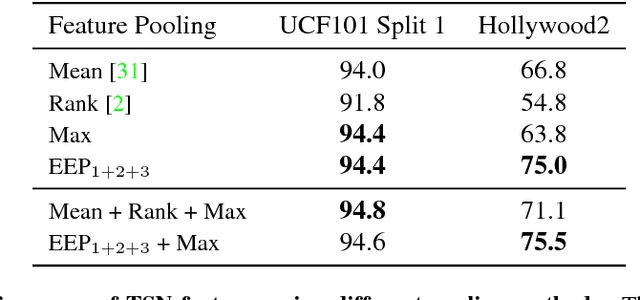
We introduce Eigen Evolution Pooling, an efficient method to aggregate a sequence of feature vectors. Eigen evolution pooling is designed to produce compact feature representations for a sequence of feature vectors, while maximally preserving as much information about the sequence as possible, especially the temporal evolution of the features over time. Eigen evolution pooling is a general pooling method that can be applied to any sequence of feature vectors, from low-level RGB values to high-level Convolutional Neural Network (CNN) feature vectors. We show that eigen evolution pooling is more effective than average, max, and rank pooling for encoding the dynamics of human actions in video. We demonstrate the power of eigen evolution pooling on UCF101 and Hollywood2 datasets, two human action recognition benchmarks, and achieve state-of-the-art performance.
Evolution-Preserving Dense Trajectory Descriptors
Feb 14, 2017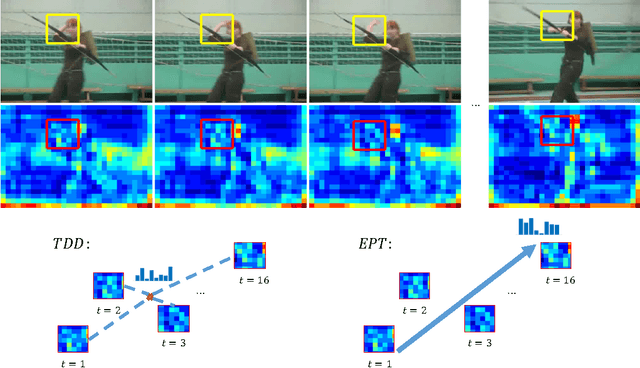
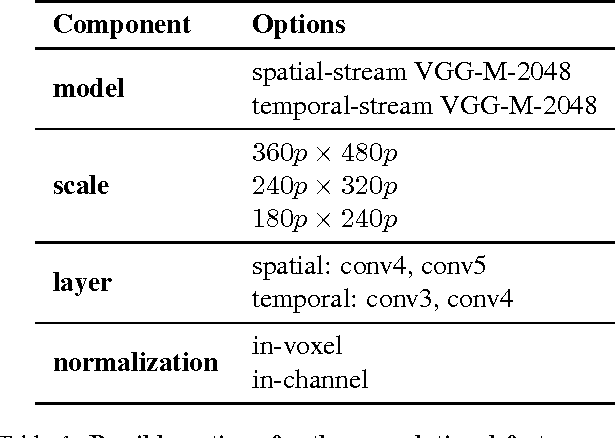
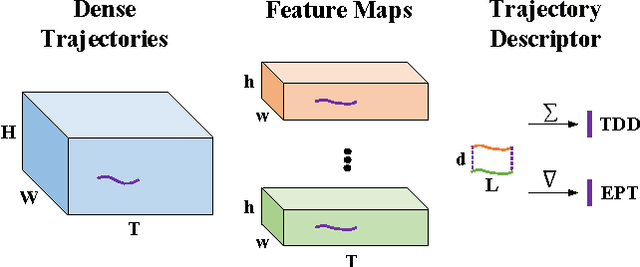

Recently Trajectory-pooled Deep-learning Descriptors were shown to achieve state-of-the-art human action recognition results on a number of datasets. This paper improves their performance by applying rank pooling to each trajectory, encoding the temporal evolution of deep learning features computed along the trajectory. This leads to Evolution-Preserving Trajectory (EPT) descriptors, a novel type of video descriptor that significantly outperforms Trajectory-pooled Deep-learning Descriptors. EPT descriptors are defined based on dense trajectories, and they provide complimentary benefits to video descriptors that are not based on trajectories. In particular, we show that the combination of EPT descriptors and VideoDarwin leads to state-of-the-art performance on Hollywood2 and UCF101 datasets.