 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisak CV Kumar
Sim-to-Real Transfer for Biped Locomotion
Mar 04, 2019

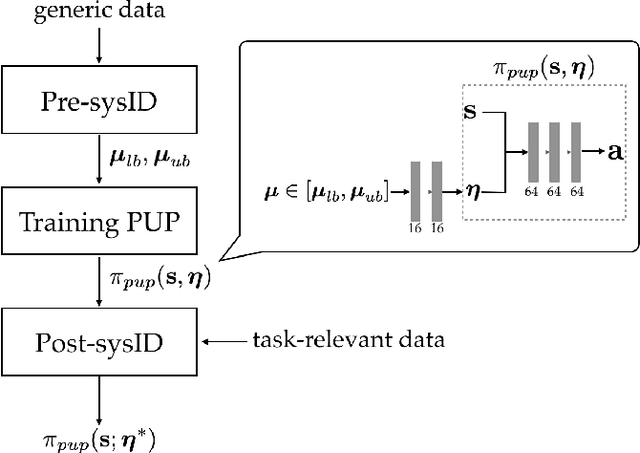

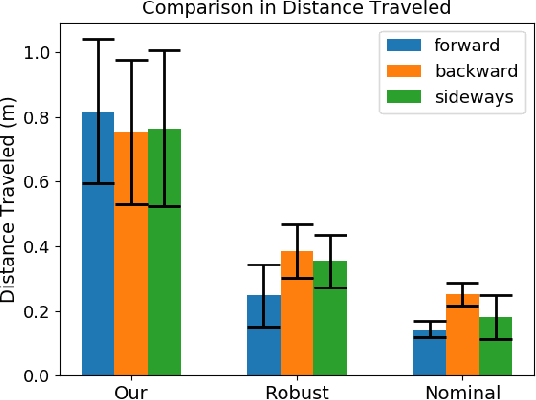
We present a new approach for transfer of dynamic robot control policies such as biped locomotion from simulation to real hardware. Key to our approach is to perform system identification of the model parameters {\mu} of the hardware (e.g. friction, center-of-mass) in two distinct stages, before policy learning (pre-sysID) and after policy learning (post-sysID). Pre-sysID begins by collecting trajectories from the physical hardware based on a set of generic motion sequences. Because the trajectories may not be related to the task of interest, presysID does not attempt to accurately identify the true value of {\mu}, but only to approximate the range of {\mu} to guide the policy learning. Next, a Projected Universal Policy (PUP) is created by simultaneously training a network that projects {\mu} to a low-dimensional latent variable {\eta} and a family of policies that are conditioned on {\eta}. The second round of system identification (post-sysID) is then carried out by deploying the PUP on the robot hardware using task-relevant trajectories. We use Bayesian Optimization to determine the values for {\eta} that optimizes the performance of PUP on the real hardware. We have used this approach to create three successful biped locomotion controllers (walk forward, walk backwards, walk sideways) on the Darwin OP2 robot.
Learning a Unified Control Policy for Safe Falling
Apr 20, 2017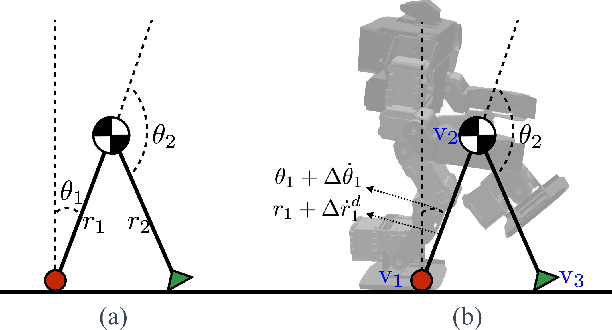
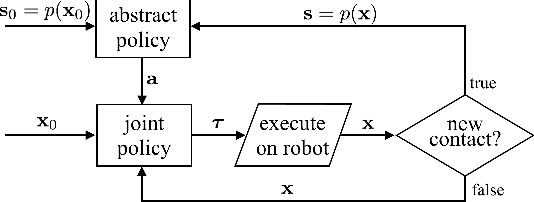
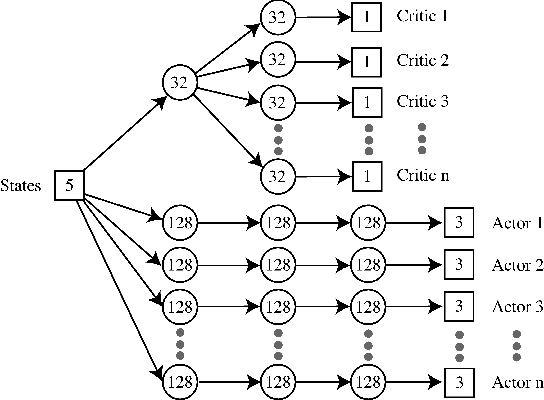
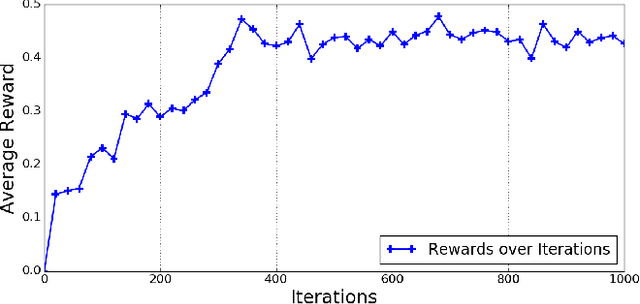
Being able to fall safely is a necessary motor skill for humanoids performing highly dynamic tasks, such as running and jumping. We propose a new method to learn a policy that minimizes the maximal impulse during the fall. The optimization solves for both a discrete contact planning problem and a continuous optimal control problem. Once trained, the policy can compute the optimal next contacting body part (e.g. left foot, right foot, or hands), contact location and timing, and the required joint actuation. We represent the policy as a mixture of actor-critic neural network, which consists of n control policies and the corresponding value functions. Each pair of actor-critic is associated with one of the n possible contacting body parts. During execution, the policy corresponding to the highest value function will be executed while the associated body part will be the next contact with the ground. With this mixture of actor-critic architecture, the discrete contact sequence planning is solved through the selection of the best critics while the continuous control problem is solved by the optimization of actors. We show that our policy can achieve comparable, sometimes even higher, rewards than a recursive search of the action space using dynamic programming, while enjoying 50 to 400 times of speed gain during online execution.