 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisar Berisha
Learning Repeatable Speech Embeddings Using An Intra-class Correlation Regularizer
Oct 25, 2023
A good supervised embedding for a specific machine learning task is only sensitive to changes in the label of interest and is invariant to other confounding factors. We leverage the concept of repeatability from measurement theory to describe this property and propose to use the intra-class correlation coefficient (ICC) to evaluate the repeatability of embeddings. We then propose a novel regularizer, the ICC regularizer, as a complementary component for contrastive losses to guide deep neural networks to produce embeddings with higher repeatability. We use simulated data to explain why the ICC regularizer works better on minimizing the intra-class variance than the contrastive loss alone. We implement the ICC regularizer and apply it to three speech tasks: speaker verification, voice style conversion, and a clinical application for detecting dysphonic voice. The experimental results demonstrate that adding an ICC regularizer can improve the repeatability of learned embeddings compared to only using the contrastive loss; further, these embeddings lead to improved performance in these downstream tasks.
Requirements for Mass Adoption of Assistive Listening Technology by the General Public
Mar 04, 2023Assistive listening systems (ALSs) dramatically increase speech intelligibility and reduce listening effort. It is very likely that essentially everyone, not only individuals with hearing loss, would benefit from the increased signal-to-noise ratio an ALS provides in almost any listening scenario. However, ALSs are rarely used by anyone other than people with severe to profound hearing losses. To date, the reasons for this poor adoption have not been systematically investigated. The authors hypothesize that the reasons for poor adoption of assistive listening technology include (1) an inability to use personally owned receiving devices, (2) a lack of high-fidelity stereo sound, (3) receiving devices not providing an unoccluded listening experience, (4) distortion from alignment delay and (5) a lack of automatic connectivity to an available assistive listening audio signal. We propose solutions to each of these problems in an effort to pave the way for mass adoption of assistive listening technology.
Smoothly Giving up: Robustness for Simple Models
Feb 17, 2023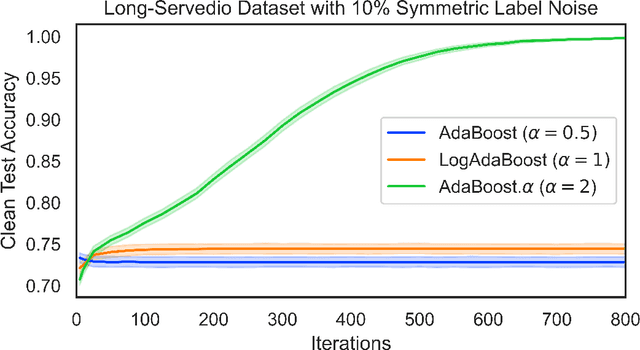

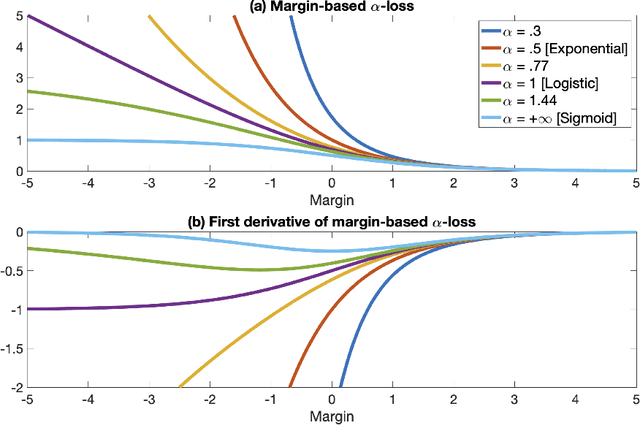

There is a growing need for models that are interpretable and have reduced energy and computational cost (e.g., in health care analytics and federated learning). Examples of algorithms to train such models include logistic regression and boosting. However, one challenge facing these algorithms is that they provably suffer from label noise; this has been attributed to the joint interaction between oft-used convex loss functions and simpler hypothesis classes, resulting in too much emphasis being placed on outliers. In this work, we use the margin-based $\alpha$-loss, which continuously tunes between canonical convex and quasi-convex losses, to robustly train simple models. We show that the $\alpha$ hyperparameter smoothly introduces non-convexity and offers the benefit of "giving up" on noisy training examples. We also provide results on the Long-Servedio dataset for boosting and a COVID-19 survey dataset for logistic regression, highlighting the efficacy of our approach across multiple relevant domains.
Active Sequential Two-Sample Testing
Feb 02, 2023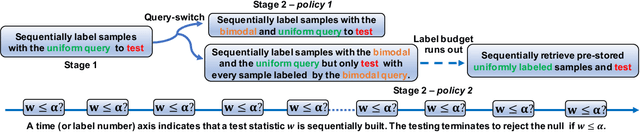
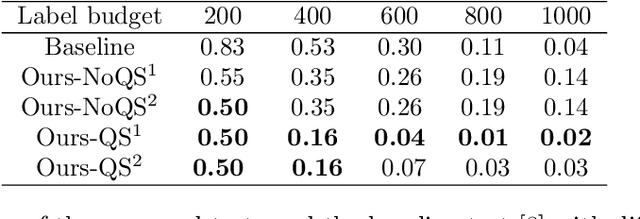
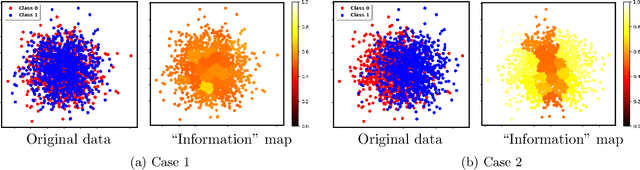

Two-sample testing tests whether the distributions generating two samples are identical. We pose the two-sample testing problem in a new scenario where the sample measurements (or sample features) are inexpensive to access, but their group memberships (or labels) are costly. We devise the first \emph{active sequential two-sample testing framework} that not only sequentially but also \emph{actively queries} sample labels to address the problem. Our test statistic is a likelihood ratio where one likelihood is found by maximization over all class priors, and the other is given by a classification model. The classification model is adaptively updated and then used to guide an active query scheme called bimodal query to label sample features in the regions with high dependency between the feature variables and the label variables. The theoretical contributions in the paper include proof that our framework produces an \emph{anytime-valid} $p$-value; and, under reachable conditions and a mild assumption, the framework asymptotically generates a minimum normalized log-likelihood ratio statistic that a passive query scheme can only achieve when the feature variable and the label variable have the highest dependence. Lastly, we provide a \emph{query-switching (QS)} algorithm to decide when to switch from passive query to active query and adapt bimodal query to increase the testing power of our test. Extensive experiments justify our theoretical contributions and the effectiveness of QS.
Robust Vocal Quality Feature Embeddings for Dysphonic Voice Detection
Nov 17, 2022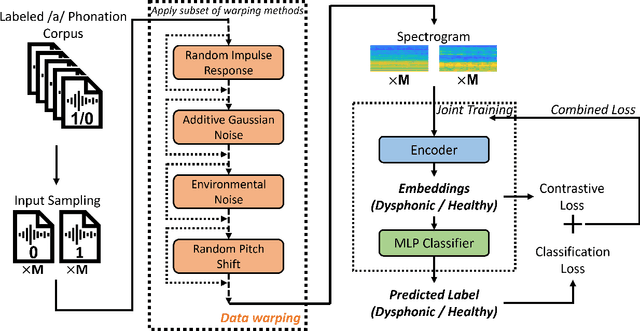
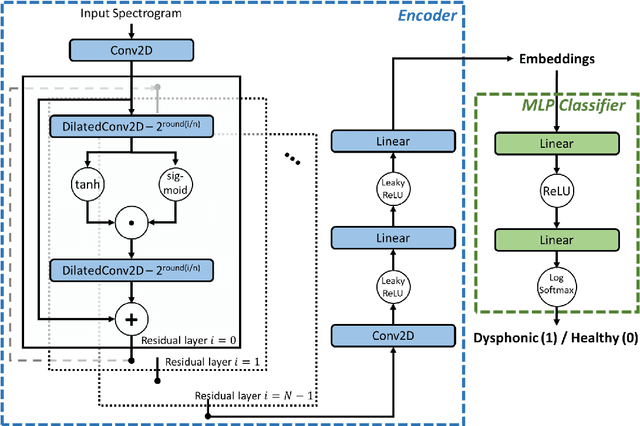
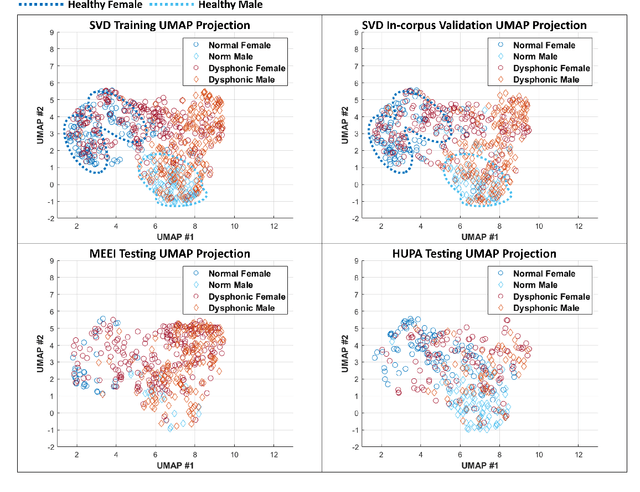
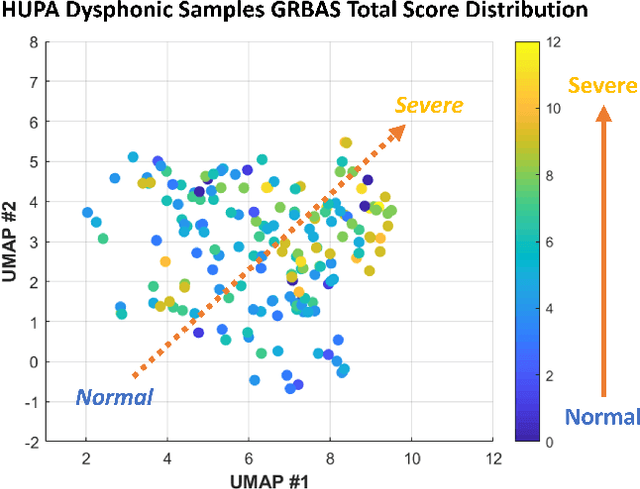
Approximately 1.2% of the world's population has impaired voice production. As a result, automatic dysphonic voice detection has attracted considerable academic and clinical interest. However, existing methods for automated voice assessment often fail to generalize outside the training conditions or to other related applications. In this paper, we propose a deep learning framework for generating acoustic feature embeddings sensitive to vocal quality and robust across different corpora. A contrastive loss is combined with a classification loss to train our deep learning model jointly. Data warping methods are used on input voice samples to improve the robustness of our method. Empirical results demonstrate that our method not only achieves high in-corpus and cross-corpus classification accuracy but also generates good embeddings sensitive to voice quality and robust across different corpora. We also compare our results against three baseline methods on clean and three variations of deteriorated in-corpus and cross-corpus datasets and demonstrate that the proposed model consistently outperforms the baseline methods.
TorchDIVA: An Extensible Computational Model of Speech Production built on an Open-Source Machine Learning Library
Oct 17, 2022



The DIVA model is a computational model of speech motor control that combines a simulation of the brain regions responsible for speech production with a model of the human vocal tract. The model is currently implemented in Matlab Simulink; however, this is less than ideal as most of the development in speech technology research is done in Python. This means there is a wealth of machine learning tools which are freely available in the Python ecosystem that cannot be easily integrated with DIVA. We present TorchDIVA, a full rebuild of DIVA in Python using PyTorch tensors. DIVA source code was directly translated from Matlab to Python, and built-in Simulink signal blocks were implemented from scratch. After implementation, the accuracy of each module was evaluated via systematic block-by-block validation. The TorchDIVA model is shown to produce outputs that closely match those of the original DIVA model, with a negligible difference between the two. We additionally present an example of the extensibility of TorchDIVA as a research platform. Speech quality enhancement in TorchDIVA is achieved through an integration with an existing PyTorch generative vocoder called DiffWave. A modified DiffWave mel-spectrum upsampler was trained on human speech waveforms and conditioned on the TorchDIVA speech production. The results indicate improved speech quality metrics in the DiffWave-enhanced output as compared to the baseline. This enhancement would have been difficult or impossible to accomplish in the original Matlab implementation. This proof-of-concept demonstrates the value TorchDIVA will bring to the research community. Researchers can download the new implementation at: https://github.com/skinahan/DIVA_PyTorch
Does human speech follow Benford's Law?
Mar 24, 2022



Researchers have observed that the frequencies of leading digits in many man-made and naturally occurring datasets follow a logarithmic curve, with digits that start with the number 1 accounting for $\sim 30\%$ of all numbers in the dataset and digits that start with the number 9 accounting for $\sim 5\%$ of all numbers in the dataset. This phenomenon, known as Benford's Law, is highly repeatable and appears in lists of numbers from electricity bills, stock prices, tax returns, house prices, death rates, lengths of rivers, and naturally occurring images. In this paper we demonstrate that human speech spectra also follow Benford's Law. We use this observation to motivate a new set of features that can be efficiently extracted from speech and demonstrate that these features can be used to classify between human speech and synthetic speech.
Consonant-Vowel Transition Models Based on Deep Learning for Objective Evaluation of Articulation
Mar 18, 2022



Spectro-temporal dynamics of consonant-vowel (CV) transition regions are considered to provide robust cues related to articulation. In this work, we propose an objective measure of precise articulation, dubbed the objective articulation measure (OAM), by analyzing the CV transitions segmented around vowel onsets. The OAM is derived based on the posteriors of a convolutional neural network pre-trained to classify between different consonants using CV regions as input. We demonstrate the OAM is correlated with perceptual measures in a variety of contexts including (a) adult dysarthric speech, (b) the speech of children with cleft lip/palate, and (c) a database of accented English speech from native Mandarin and Spanish speakers.
A label efficient two-sample test
Nov 29, 2021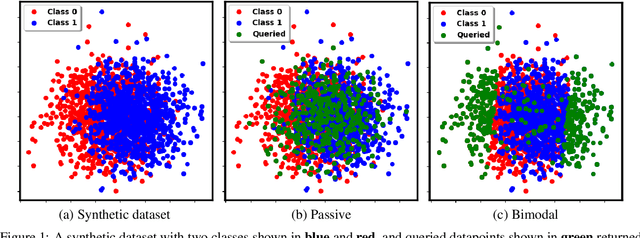
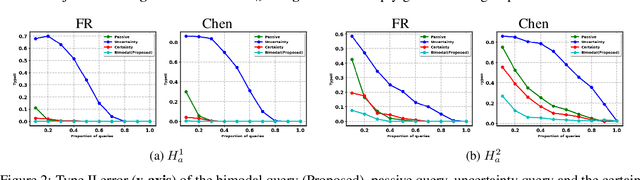
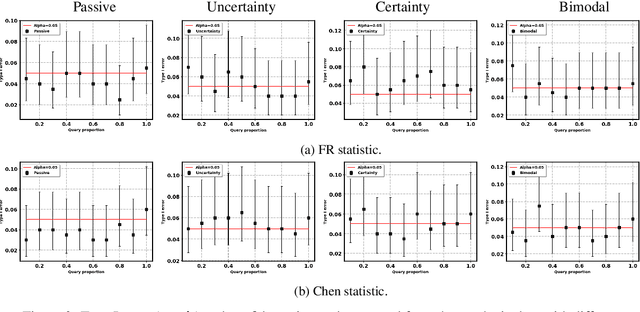
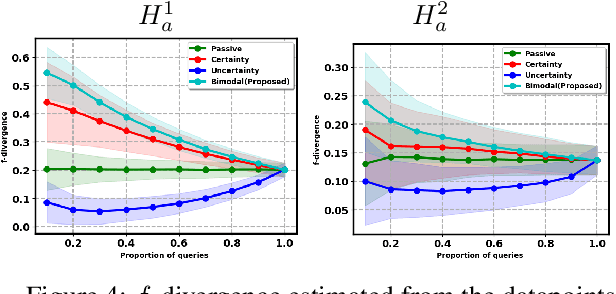
Two-sample tests evaluate whether two samples are realizations of the same distribution (the null hypothesis) or two different distributions (the alternative hypothesis). In the traditional formulation of this problem, the statistician has access to both the measurements (feature variables) and the group variable (label variable). However, in several important applications, feature variables can be easily measured but the binary label variable is unknown and costly to obtain. In this paper, we consider this important variation on the classical two-sample test problem and pose it as a problem of obtaining the labels of only a small number of samples in service of performing a two-sample test. We devise a label efficient three-stage framework: firstly, a classifier is trained with samples uniformly labeled to model the posterior probabilities of the labels; secondly, a novel query scheme dubbed \emph{bimodal query} is used to query labels of samples from both classes with maximum posterior probabilities, and lastly, the classical Friedman-Rafsky (FR) two-sample test is performed on the queried samples. Our theoretical analysis shows that bimodal query is optimal for two-sample testing using the FR statistic under reasonable conditions and that the three-stage framework controls the Type I error. Extensive experiments performed on synthetic, benchmark, and application-specific datasets demonstrate that the three-stage framework has decreased Type II error over uniform querying and certainty-based querying with same number of labels while controlling the Type I error. Source code for our algorithms and experimental results is available at https://github.com/wayne0908/Label-Efficient-Two-Sample.
Restoring degraded speech via a modified diffusion model
Apr 22, 2021



There are many deterministic mathematical operations (e.g. compression, clipping, downsampling) that degrade speech quality considerably. In this paper we introduce a neural network architecture, based on a modification of the DiffWave model, that aims to restore the original speech signal. DiffWave, a recently published diffusion-based vocoder, has shown state-of-the-art synthesized speech quality and relatively shorter waveform generation times, with only a small set of parameters. We replace the mel-spectrum upsampler in DiffWave with a deep CNN upsampler, which is trained to alter the degraded speech mel-spectrum to match that of the original speech. The model is trained using the original speech waveform, but conditioned on the degraded speech mel-spectrum. Post-training, only the degraded mel-spectrum is used as input and the model generates an estimate of the original speech. Our model results in improved speech quality (original DiffWave model as baseline) on several different experiments. These include improving the quality of speech degraded by LPC-10 compression, AMR-NB compression, and signal clipping. Compared to the original DiffWave architecture, our scheme achieves better performance on several objective perceptual metrics and in subjective comparisons. Improvements over baseline are further amplified in a out-of-corpus evaluation setting.