 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVivek Kumar
PhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024
The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Ask the experts: sourcing high-quality datasets for nutritional counselling through Human-AI collaboration
Jan 16, 2024Large Language Models (LLMs), with their flexible generation abilities, can be powerful data sources in domains with few or no available corpora. However, problems like hallucinations and biases limit such applications. In this case study, we pick nutrition counselling, a domain lacking any public resource, and show that high-quality datasets can be gathered by combining LLMs, crowd-workers and nutrition experts. We first crowd-source and cluster a novel dataset of diet-related issues, then work with experts to prompt ChatGPT into producing related supportive text. Finally, we let the experts evaluate the safety of the generated text. We release HAI-coaching, the first expert-annotated nutrition counselling dataset containing ~2.4K dietary struggles from crowd workers, and ~97K related supportive texts generated by ChatGPT. Extensive analysis shows that ChatGPT while producing highly fluent and human-like text, also manifests harmful behaviours, especially in sensitive topics like mental health, making it unsuitable for unsupervised use.
VISU at WASSA 2023 Shared Task: Detecting Emotions in Reaction to News Stories Leveraging BERT and Stacked Embeddings
Jul 27, 2023



Our system, VISU, participated in the WASSA 2023 Shared Task (3) of Emotion Classification from essays written in reaction to news articles. Emotion detection from complex dialogues is challenging and often requires context/domain understanding. Therefore in this research, we have focused on developing deep learning (DL) models using the combination of word embedding representations with tailored prepossessing strategies to capture the nuances of emotions expressed. Our experiments used static and contextual embeddings (individual and stacked) with Bidirectional Long short-term memory (BiLSTM) and Transformer based models. We occupied rank tenth in the emotion detection task by scoring a Macro F1-Score of 0.2717, validating the efficacy of our implemented approaches for small and imbalanced datasets with mixed categories of target emotions.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023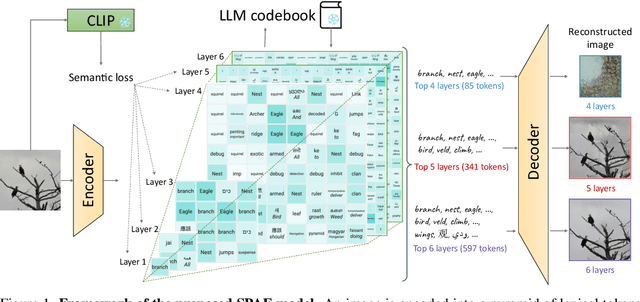

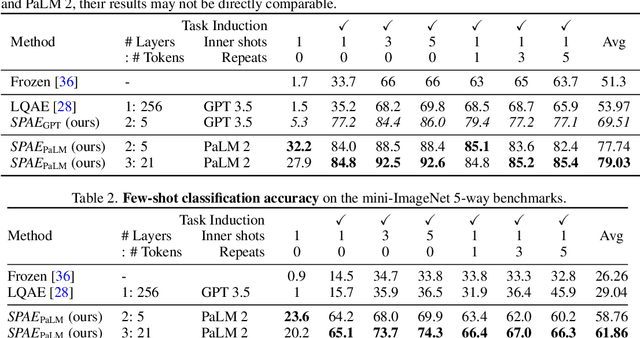
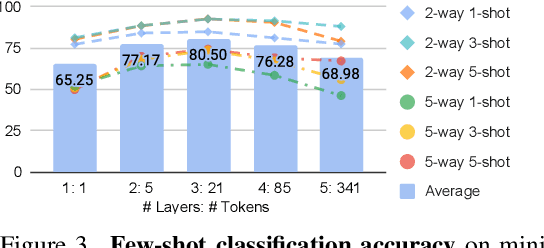
In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior
Jul 21, 2022
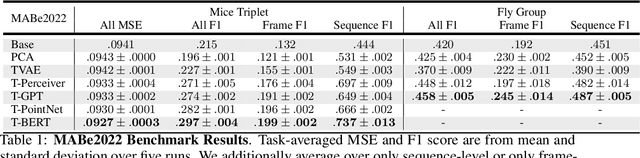
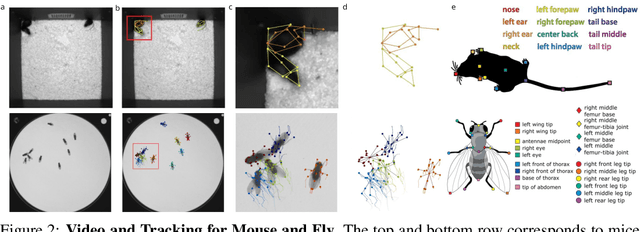
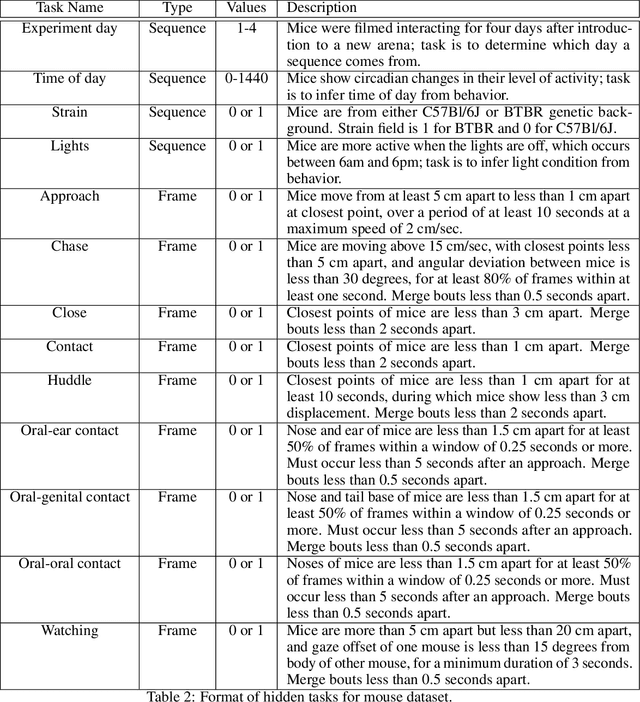
Real-world behavior is often shaped by complex interactions between multiple agents. To scalably study multi-agent behavior, advances in unsupervised and self-supervised learning have enabled a variety of different behavioral representations to be learned from trajectory data. To date, there does not exist a unified set of benchmarks that can enable comparing methods quantitatively and systematically across a broad set of behavior analysis settings. We aim to address this by introducing a large-scale, multi-agent trajectory dataset from real-world behavioral neuroscience experiments that covers a range of behavior analysis tasks. Our dataset consists of trajectory data from common model organisms, with 9.6 million frames of mouse data and 4.4 million frames of fly data, in a variety of experimental settings, such as different strains, lengths of interaction, and optogenetic stimulation. A subset of the frames also consist of expert-annotated behavior labels. Improvements on our dataset corresponds to behavioral representations that work across multiple organisms and is able to capture differences for common behavior analysis tasks.
Practice Makes a Solver Perfect: Data Augmentation for Math Word Problem Solvers
Apr 30, 2022



Existing Math Word Problem (MWP) solvers have achieved high accuracy on benchmark datasets. However, prior works have shown that such solvers do not generalize well and rely on superficial cues to achieve high performance. In this paper, we first conduct experiments to showcase that this behaviour is mainly associated with the limited size and diversity present in existing MWP datasets. Next, we propose several data augmentation techniques broadly categorized into Substitution and Paraphrasing based methods. By deploying these methods we increase the size of existing datasets by five folds. Extensive experiments on two benchmark datasets across three state-of-the-art MWP solvers show that proposed methods increase the generalization and robustness of existing solvers. On average, proposed methods significantly increase the state-of-the-art results by over five percentage points on benchmark datasets. Further, the solvers trained on the augmented dataset perform comparatively better on the challenge test set. We also show the effectiveness of proposed techniques through ablation studies and verify the quality of augmented samples through human evaluation.
Pneumonia Detection in Chest X-Rays using Neural Networks
Apr 07, 2022



With the advancement in AI, deep learning techniques are widely used to design robust classification models in several areas such as medical diagnosis tasks in which it achieves good performance. In this paper, we have proposed the CNN model (Convolutional Neural Network) for the classification of Chest X-ray images for Radiological Society of North America Pneumonia (RSNA) datasets. The study also tries to achieve the same RSNA benchmark results using the limited computational resources by trying out various approaches to the methodologies that have been implemented in recent years. The proposed method is based on a non-complex CNN and the use of transfer learning algorithms like Xception, InceptionV3/V4, EfficientNetB7. Along with this, the study also tries to achieve the same RSNA benchmark results using the limited computational resources by trying out various approaches to the methodologies that have been implemented in recent years. The RSNA benchmark MAP score is 0.25, but using the Mask RCNN model on a stratified sample of 3017 along with image augmentation gave a MAP score of 0.15. Meanwhile, the YoloV3 without any hyperparameter tuning gave the MAP score of 0.32 but still, the loss keeps decreasing. Running the model for a greater number of iterations can give better results.
Adversarial Examples for Evaluating Math Word Problem Solvers
Sep 13, 2021



Standard accuracy metrics have shown that Math Word Problem (MWP) solvers have achieved high performance on benchmark datasets. However, the extent to which existing MWP solvers truly understand language and its relation with numbers is still unclear. In this paper, we generate adversarial attacks to evaluate the robustness of state-of-the-art MWP solvers. We propose two methods Question Reordering and Sentence Paraphrasing to generate adversarial attacks. We conduct experiments across three neural MWP solvers over two benchmark datasets. On average, our attack method is able to reduce the accuracy of MWP solvers by over 40 percentage points on these datasets. Our results demonstrate that existing MWP solvers are sensitive to linguistic variations in the problem text. We verify the validity and quality of generated adversarial examples through human evaluation.
TF-IDF vs Word Embeddings for Morbidity Identification in Clinical Notes: An Initial Study
Jun 09, 2021



Today, we are seeing an ever-increasing number of clinical notes that contain clinical results, images, and textual descriptions of patient's health state. All these data can be analyzed and employed to cater novel services that can help people and domain experts with their common healthcare tasks. However, many technologies such as Deep Learning and tools like Word Embeddings have started to be investigated only recently, and many challenges remain open when it comes to healthcare domain applications. To address these challenges, we propose the use of Deep Learning and Word Embeddings for identifying sixteen morbidity types within textual descriptions of clinical records. For this purpose, we have used a Deep Learning model based on Bidirectional Long-Short Term Memory (LSTM) layers which can exploit state-of-the-art vector representations of data such as Word Embeddings. We have employed pre-trained Word Embeddings namely GloVe and Word2Vec, and our own Word Embeddings trained on the target domain. Furthermore, we have compared the performances of the deep learning approaches against the traditional tf-idf using Support Vector Machine and Multilayer perceptron (our baselines). From the obtained results it seems that the latter outperforms the combination of Deep Learning approaches using any word embeddings. Our preliminary results indicate that there are specific features that make the dataset biased in favour of traditional machine learning approaches.
Towards Detecting Need for Empathetic Response in Motivational Interviewing
May 20, 2021

Empathetic response from the therapist is key to the success of clinical psychotherapy, especially motivational interviewing. Previous work on computational modelling of empathy in motivational interviewing has focused on offline, session-level assessment of therapist empathy, where empathy captures all efforts that the therapist makes to understand the client's perspective and convey that understanding to the client. In this position paper, we propose a novel task of turn-level detection of client need for empathy. Concretely, we propose to leverage pre-trained language models and empathy-related general conversation corpora in a unique labeller-detector framework, where the labeller automatically annotates a motivational interviewing conversation corpus with empathy labels to train the detector that determines the need for therapist empathy. We also lay out our strategies of extending the detector with additional-input and multi-task setups to improve its detection and explainability.