 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVivek Shetty
Monitoring Fidelity of Online Reinforcement Learning Algorithms in Clinical Trials
Feb 26, 2024
Online reinforcement learning (RL) algorithms offer great potential for personalizing treatment for participants in clinical trials. However, deploying an online, autonomous algorithm in the high-stakes healthcare setting makes quality control and data quality especially difficult to achieve. This paper proposes algorithm fidelity as a critical requirement for deploying online RL algorithms in clinical trials. It emphasizes the responsibility of the algorithm to (1) safeguard participants and (2) preserve the scientific utility of the data for post-trial analyses. We also present a framework for pre-deployment planning and real-time monitoring to help algorithm developers and clinical researchers ensure algorithm fidelity. To illustrate our framework's practical application, we present real-world examples from the Oralytics clinical trial. Since Spring 2023, this trial successfully deployed an autonomous, online RL algorithm to personalize behavioral interventions for participants at risk for dental disease.
Reward Design For An Online Reinforcement Learning Algorithm Supporting Oral Self-Care
Aug 15, 2022
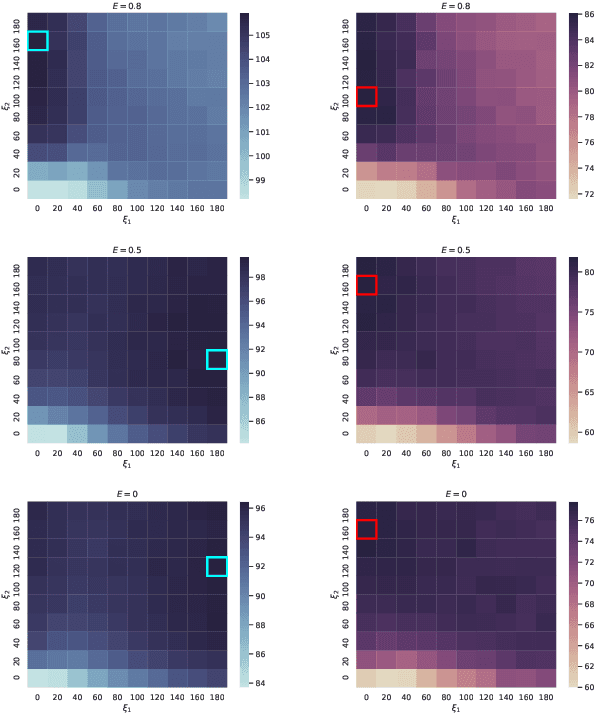

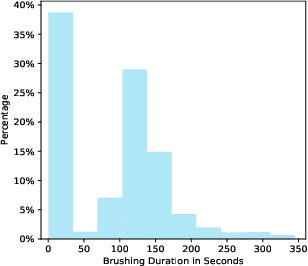
Dental disease is one of the most common chronic diseases despite being largely preventable. However, professional advice on optimal oral hygiene practices is often forgotten or abandoned by patients. Therefore patients may benefit from timely and personalized encouragement to engage in oral self-care behaviors. In this paper, we develop an online reinforcement learning (RL) algorithm for use in optimizing the delivery of mobile-based prompts to encourage oral hygiene behaviors. One of the main challenges in developing such an algorithm is ensuring that the algorithm considers the impact of the current action on the effectiveness of future actions (i.e., delayed effects), especially when the algorithm has been made simple in order to run stably and autonomously in a constrained, real-world setting (i.e., highly noisy, sparse data). We address this challenge by designing a quality reward which maximizes the desired health outcome (i.e., high-quality brushing) while minimizing user burden. We also highlight a procedure for optimizing the hyperparameters of the reward by building a simulation environment test bed and evaluating candidates using the test bed. The RL algorithm discussed in this paper will be deployed in Oralytics, an oral self-care app that provides behavioral strategies to boost patient engagement in oral hygiene practices.
Designing Reinforcement Learning Algorithms for Digital Interventions: Pre-implementation Guidelines
Jun 08, 2022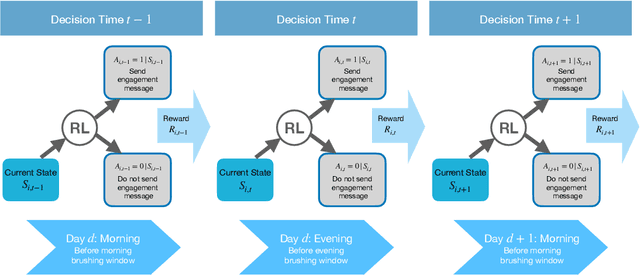

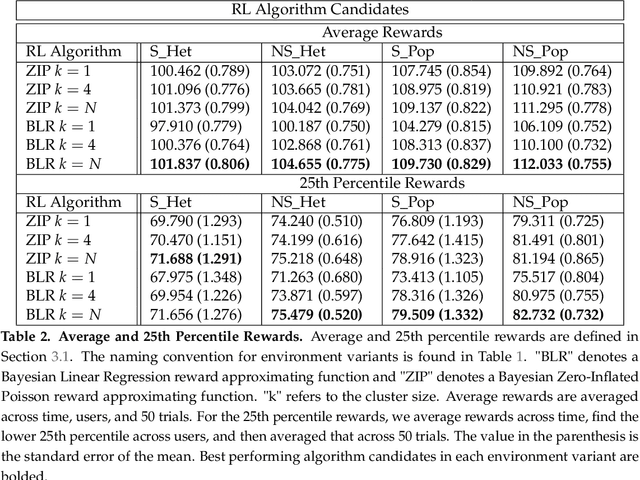
Online reinforcement learning (RL) algorithms are increasingly used to personalize digital interventions in the fields of mobile health and online education. Common challenges in designing and testing an RL algorithm in these settings include ensuring the RL algorithm can learn and run stably under real-time constraints, and accounting for the complexity of the environment, e.g., a lack of accurate mechanistic models for the user dynamics. To guide how one can tackle these challenges, we extend the PCS (Predictability, Computability, Stability) framework, a data science framework that incorporates best practices from machine learning and statistics in supervised learning (Yu and Kumbier, 2020), to the design of RL algorithms for the digital interventions setting. Further, we provide guidelines on how to design simulation environments, a crucial tool for evaluating RL candidate algorithms using the PCS framework. We illustrate the use of the PCS framework for designing an RL algorithm for Oralytics, a mobile health study aiming to improve users' tooth-brushing behaviors through the personalized delivery of intervention messages. Oralytics will go into the field in late 2022.