 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVlad Eidelman
BillSum: A Corpus for Automatic Summarization of US Legislation
Oct 01, 2019
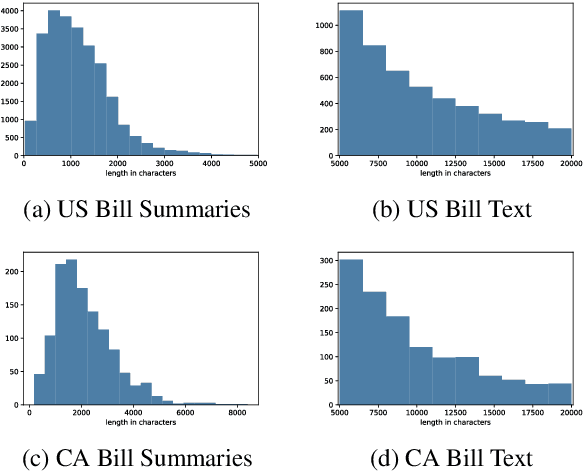
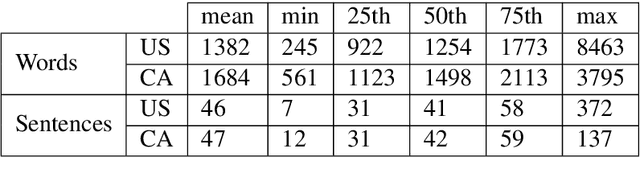

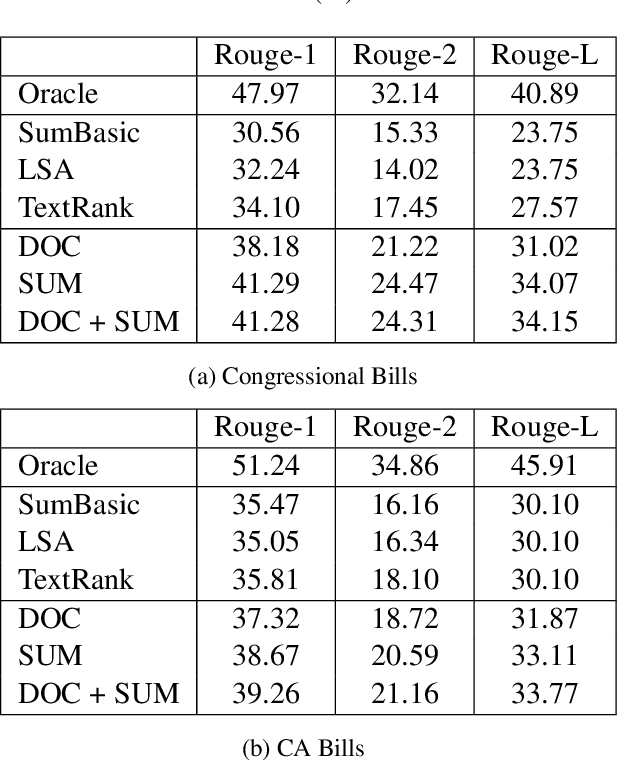
Automatic summarization methods have been studied on a variety of domains, including news and scientific articles. Yet, legislation has not previously been considered for this task, despite US Congress and state governments releasing tens of thousands of bills every year. In this paper, we introduce BillSum, the first dataset for summarization of US Congressional and California state bills (https://github.com/FiscalNote/BillSum). We explain the properties of the dataset that make it more challenging to process than other domains. Then, we benchmark extractive methods that consider neural sentence representations and traditional contextual features. Finally, we demonstrate that models built on Congressional bills can be used to summarize California bills, thus, showing that methods developed on this dataset can transfer to states without human-written summaries.
Argument Identification in Public Comments from eRulemaking
May 14, 2019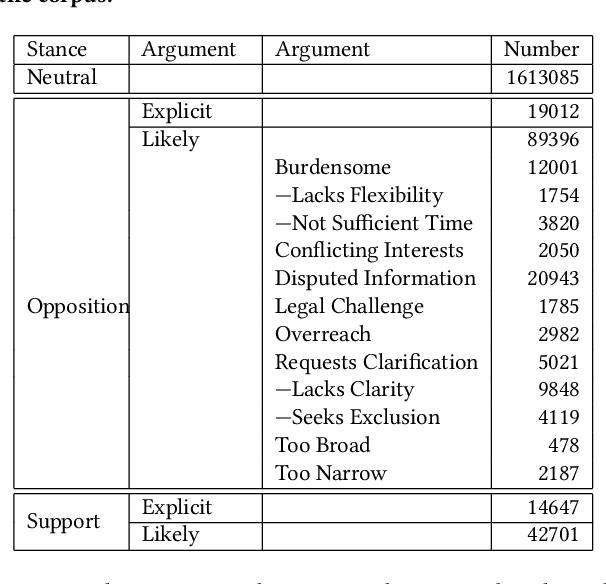
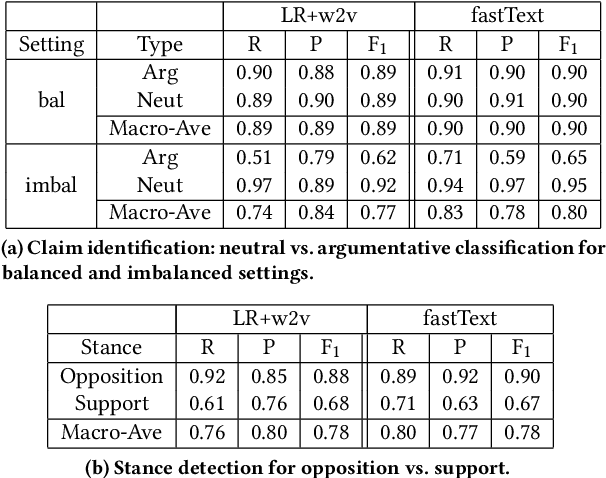
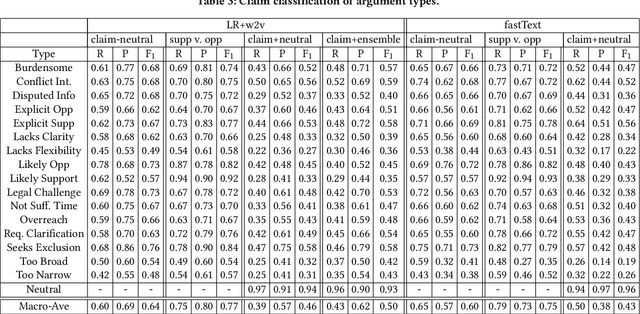
Administrative agencies in the United States receive millions of comments each year concerning proposed agency actions during the eRulemaking process. These comments represent a diversity of arguments in support and opposition of the proposals. While agencies are required to identify and respond to substantive comments, they have struggled to keep pace with the volume of information. In this work we address the tasks of identifying argumentative text, classifying the type of argument claims employed, and determining the stance of the comment. First, we propose a taxonomy of argument claims based on an analysis of thousands of rules and millions of comments. Second, we collect and semi-automatically bootstrap annotations to create a dataset of millions of sentences with argument claim type annotation at the sentence level. Third, we build a system for automatically determining argumentative spans and claim type using our proposed taxonomy in a hierarchical classification model.
How Predictable is Your State? Leveraging Lexical and Contextual Information for Predicting Legislative Floor Action at the State Level
Jun 13, 2018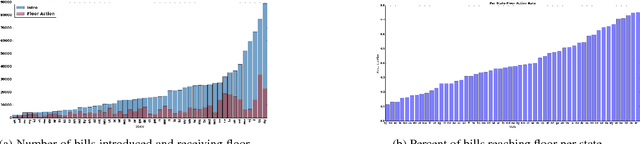



Modeling U.S. Congressional legislation and roll-call votes has received significant attention in previous literature. However, while legislators across 50 state governments and D.C. propose over 100,000 bills each year, and on average enact over 30% of them, state level analysis has received relatively less attention due in part to the difficulty in obtaining the necessary data. Since each state legislature is guided by their own procedures, politics and issues, however, it is difficult to qualitatively asses the factors that affect the likelihood of a legislative initiative succeeding. Herein, we present several methods for modeling the likelihood of a bill receiving floor action across all 50 states and D.C. We utilize the lexical content of over 1 million bills, along with contextual legislature and legislator derived features to build our predictive models, allowing a comparison of the factors that are important to the lawmaking process. Furthermore, we show that these signals hold complementary predictive power, together achieving an average improvement in accuracy of 18% over state specific baselines.
Party Matters: Enhancing Legislative Embeddings with Author Attributes for Vote Prediction
May 21, 2018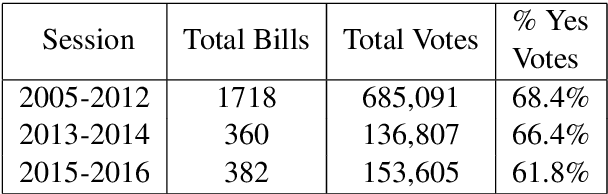
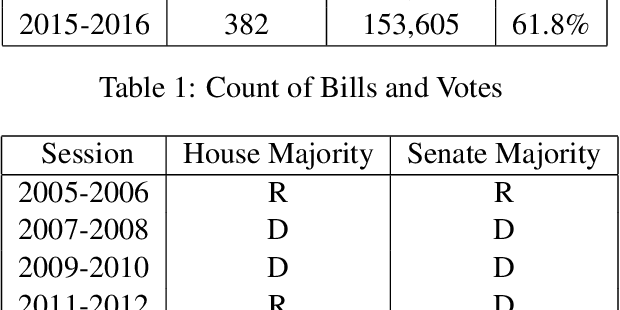
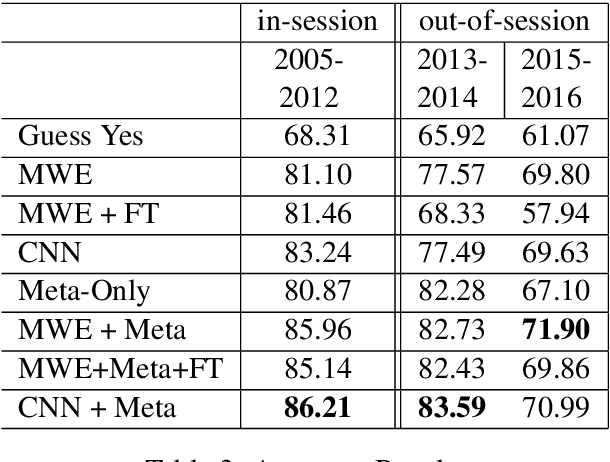
Predicting how Congressional legislators will vote is important for understanding their past and future behavior. However, previous work on roll-call prediction has been limited to single session settings, thus did not consider generalization across sessions. In this paper, we show that metadata is crucial for modeling voting outcomes in new contexts, as changes between sessions lead to changes in the underlying data generation process. We show how augmenting bill text with the sponsors' ideologies in a neural network model can achieve an average of a 4% boost in accuracy over the previous state-of-the-art.