 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanchun Liu
Semantic-aware Transmission Scheduling: a Monotonicity-driven Deep Reinforcement Learning Approach
May 23, 2023



For cyber-physical systems in the 6G era, semantic communications connecting distributed devices for dynamic control and remote state estimation are required to guarantee application-level performance, not merely focus on communication-centric performance. Semantics here is a measure of the usefulness of information transmissions. Semantic-aware transmission scheduling of a large system often involves a large decision-making space, and the optimal policy cannot be obtained by existing algorithms effectively. In this paper, we first investigate the fundamental properties of the optimal semantic-aware scheduling policy and then develop advanced deep reinforcement learning (DRL) algorithms by leveraging the theoretical guidelines. Our numerical results show that the proposed algorithms can substantially reduce training time and enhance training performance compared to benchmark algorithms.
Splitting Receiver with Multiple Antennas
Mar 08, 2023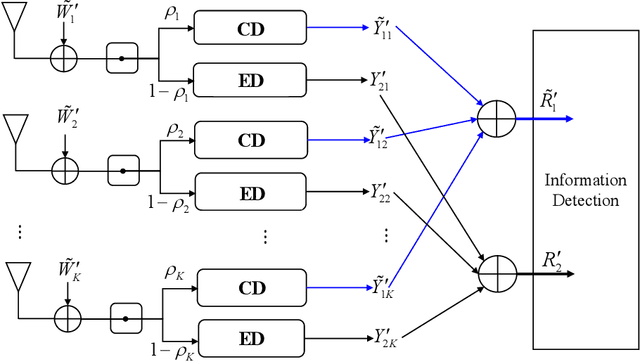
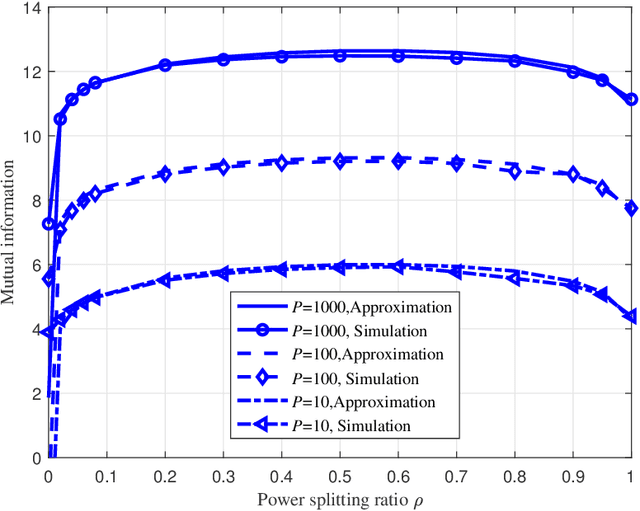
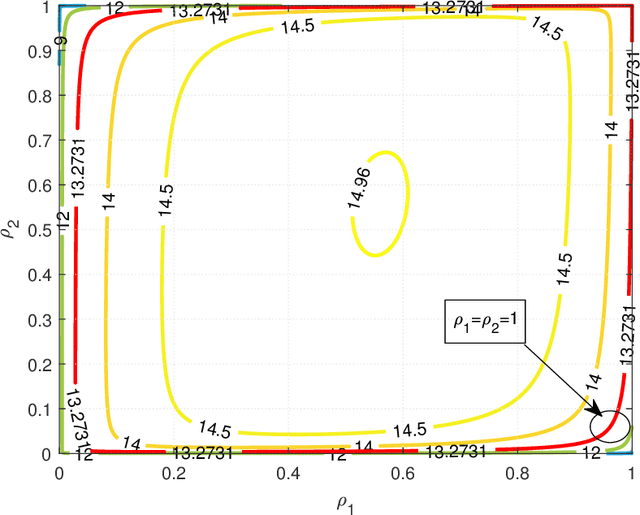
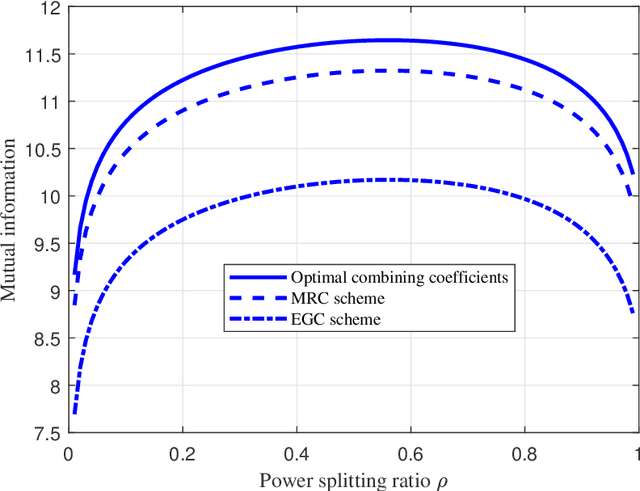
Recently proposed splitting receivers, utilizing both coherently and non-coherently processed signals for detection, have demonstrated remarkable performance gain compared to conventional receivers in the single-antenna scenario. In this paper, we propose a multi-antenna splitting receiver, where the received signal at each antenna is split into an envelope detection (ED) branch and a coherent detection (CD) branch, and the processed signals from both branches of all antennas are then jointly utilized for recovering the transmitted information. We derive a closed-form approximation of the achievable mutual information (MI) in terms of the key receiver design parameters, including the power splitting ratio at each antenna and the signal combining coefficients from all the ED and CD branches. We further optimize these receiver design parameters and demonstrate important design insights for the proposed multi-antenna ED-CD splitting receiver: 1) the optimal splitting ratio is identical at each antenna, and 2) the optimal combining coefficients for the ED and CD branches are the same, and each coefficient is proportional to the corresponding antenna's channel power gain. Our numerical results also demonstrate the MI performance improvement of the proposed receiver over conventional non-splitting receivers.
Structure-Enhanced DRL for Optimal Transmission Scheduling
Dec 24, 2022



Remote state estimation of large-scale distributed dynamic processes plays an important role in Industry 4.0 applications. In this paper, we focus on the transmission scheduling problem of a remote estimation system. First, we derive some structural properties of the optimal sensor scheduling policy over fading channels. Then, building on these theoretical guidelines, we develop a structure-enhanced deep reinforcement learning (DRL) framework for optimal scheduling of the system to achieve the minimum overall estimation mean-square error (MSE). In particular, we propose a structure-enhanced action selection method, which tends to select actions that obey the policy structure. This explores the action space more effectively and enhances the learning efficiency of DRL agents. Furthermore, we introduce a structure-enhanced loss function to add penalties to actions that do not follow the policy structure. The new loss function guides the DRL to converge to the optimal policy structure quickly. Our numerical experiments illustrate that the proposed structure-enhanced DRL algorithms can save the training time by 50% and reduce the remote estimation MSE by 10% to 25% when compared to benchmark DRL algorithms. In addition, we show that the derived structural properties exist in a wide range of dynamic scheduling problems that go beyond remote state estimation.
Structure-Enhanced Deep Reinforcement Learning for Optimal Transmission Scheduling
Nov 20, 2022



Remote state estimation of large-scale distributed dynamic processes plays an important role in Industry 4.0 applications. In this paper, by leveraging the theoretical results of structural properties of optimal scheduling policies, we develop a structure-enhanced deep reinforcement learning (DRL) framework for optimal scheduling of a multi-sensor remote estimation system to achieve the minimum overall estimation mean-square error (MSE). In particular, we propose a structure-enhanced action selection method, which tends to select actions that obey the policy structure. This explores the action space more effectively and enhances the learning efficiency of DRL agents. Furthermore, we introduce a structure-enhanced loss function to add penalty to actions that do not follow the policy structure. The new loss function guides the DRL to converge to the optimal policy structure quickly. Our numerical results show that the proposed structure-enhanced DRL algorithms can save the training time by 50% and reduce the remote estimation MSE by 10% to 25%, when compared to benchmark DRL algorithms.
Deep Learning for Wireless Networked Systems: a joint Estimation-Control-Scheduling Approach
Oct 03, 2022



Wireless networked control system (WNCS) connecting sensors, controllers, and actuators via wireless communications is a key enabling technology for highly scalable and low-cost deployment of control systems in the Industry 4.0 era. Despite the tight interaction of control and communications in WNCSs, most existing works adopt separative design approaches. This is mainly because the co-design of control-communication policies requires large and hybrid state and action spaces, making the optimal problem mathematically intractable and difficult to be solved effectively by classic algorithms. In this paper, we systematically investigate deep learning (DL)-based estimator-control-scheduler co-design for a model-unknown nonlinear WNCS over wireless fading channels. In particular, we propose a co-design framework with the awareness of the sensor's age-of-information (AoI) states and dynamic channel states. We propose a novel deep reinforcement learning (DRL)-based algorithm for controller and scheduler optimization utilizing both model-free and model-based data. An AoI-based importance sampling algorithm that takes into account the data accuracy is proposed for enhancing learning efficiency. We also develop novel schemes for enhancing the stability of joint training. Extensive experiments demonstrate that the proposed joint training algorithm can effectively solve the estimation-control-scheduling co-design problem in various scenarios and provide significant performance gain compared to separative design and some benchmark policies.
DRL-based Resource Allocation in Remote State Estimation
May 24, 2022



Remote state estimation, where sensors send their measurements of distributed dynamic plants to a remote estimator over shared wireless resources, is essential for mission-critical applications of Industry 4.0. Existing algorithms on dynamic radio resource allocation for remote estimation systems assumed oversimplified wireless communications models and can only work for small-scale settings. In this work, we consider remote estimation systems with practical wireless models over the orthogonal multiple-access and non-orthogonal multiple-access schemes. We derive necessary and sufficient conditions under which remote estimation systems can be stabilized. The conditions are described in terms of the transmission power budget, channel statistics, and plants' parameters. For each multiple-access scheme, we formulate a novel dynamic resource allocation problem as a decision-making problem for achieving the minimum overall long-term average estimation mean-square error. Both the estimation quality and the channel quality states are taken into account for decision making. We systematically investigated the problems under different multiple-access schemes with large discrete, hybrid discrete-and-continuous, and continuous action spaces, respectively. We propose novel action-space compression methods and develop advanced deep reinforcement learning algorithms to solve the problems. Numerical results show that our algorithms solve the resource allocation problems effectively and provide much better scalability than the literature.
Deep Reinforcement Learning for Radio Resource Allocation in NOMA-based Remote State Estimation
May 24, 2022



Remote state estimation, where many sensors send their measurements of distributed dynamic plants to a remote estimator over shared wireless resources, is essential for mission-critical applications of Industry 4.0. Most of the existing works on remote state estimation assumed orthogonal multiple access and the proposed dynamic radio resource allocation algorithms can only work for very small-scale settings. In this work, we consider a remote estimation system with non-orthogonal multiple access. We formulate a novel dynamic resource allocation problem for achieving the minimum overall long-term average estimation mean-square error. Both the estimation quality state and the channel quality state are taken into account for decision making at each time. The problem has a large hybrid discrete and continuous action space for joint channel assignment and power allocation. We propose a novel action-space compression method and develop an advanced deep reinforcement learning algorithm to solve the problem. Numerical results show that our algorithm solves the resource allocation problem effectively, presents much better scalability than the literature, and provides significant performance gain compared to some benchmarks.
Remote State Estimation of Multiple Systems over Semi-Markov Wireless Fading Channels
Mar 31, 2022



This work studies remote state estimation of multiple linear time-invariant systems over shared wireless time-varying communication channels. We model the channel states by a semi-Markov process which captures both the random holding period of each channel state and the state transitions. The model is sufficiently general to be used in both fast and slow fading scenarios. We derive necessary and sufficient stability conditions of the multi-sensor-multi-channel system in terms of the system parameters. We further investigate how the delay of the channel state information availability and the holding period of channel states affect the stability. In particular, we show that, from a system stability perspective, fast fading channels may be preferable to slow fading ones.
Splitting Receiver with Joint Envelope and Coherent Detection
Mar 02, 2022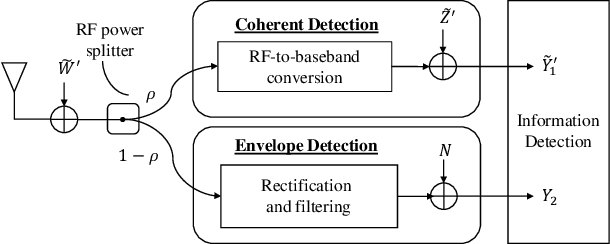
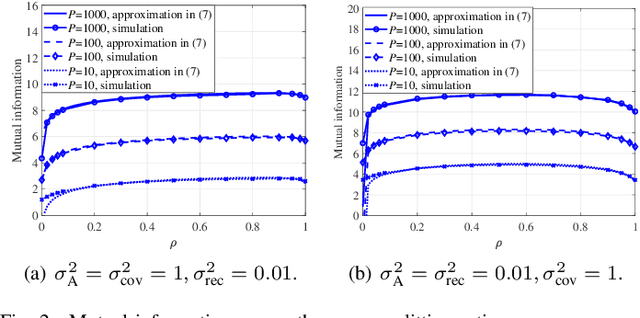
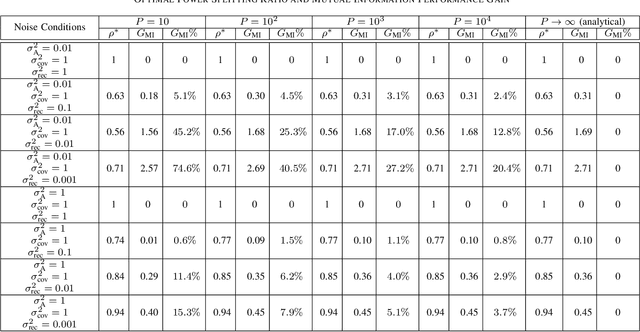
This letter proposes a new splitting receiver design with joint envelope detection (ED) and coherent detection (CD). To characterize its fundamental performance limit, we conduct high signal-to-noise ratio (SNR) analysis on the proposed ED-CD splitting receiver and obtain closed-form approximations of both the achievable mutual information and the optimal splitting ratio (i.e., a key design parameter of the receiver). Our numerical results show that these high SNR approximations are accurate over a wide range of moderate SNR values, signifying the usefulness of the obtained analytical results. We also provide insights on the conditions at which the proposed splitting receiver has significant performance advantages over the traditional receivers.
Deep Reinforcement Learning for Wireless Scheduling in Distributed Networked Control
Sep 26, 2021



In the literature of transmission scheduling in wireless networked control systems (WNCSs) over shared wireless resources, most research works have focused on partially distributed settings, i.e., where either the controller and actuator, or the sensor and controller are co-located. To overcome this limitation, the present work considers a fully distributed WNCS with distributed plants, sensors, actuators and a controller, sharing a limited number of frequency channels. To overcome communication limitations, the controller schedules the transmissions and generates sequential predictive commands for control. Using elements of stochastic systems theory, we derive a sufficient stability condition of the WNCS, which is stated in terms of both the control and communication system parameters. Once the condition is satisfied, there exists at least one stationary and deterministic scheduling policy that can stabilize all plants of the WNCS. By analyzing and representing the per-step cost function of the WNCS in terms of a finite-length countable vector state, we formulate the optimal transmission scheduling problem into a Markov decision process problem and develop a deep-reinforcement-learning-based algorithm for solving it. Numerical results show that the proposed algorithm significantly outperforms the benchmark policies.