 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT2TF: First-Person Statement Text-To-Talking Face Generation
Dec 09, 2023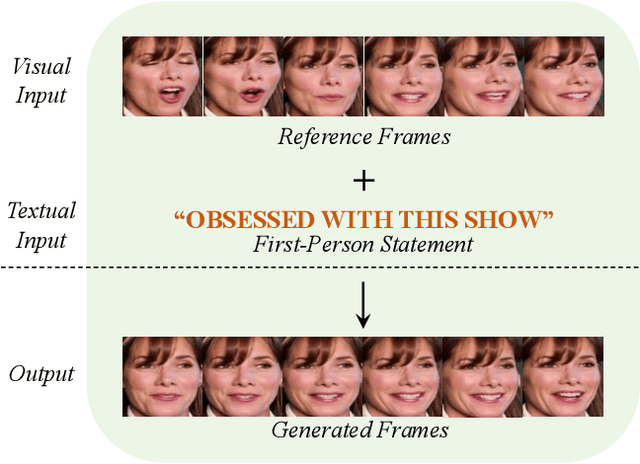
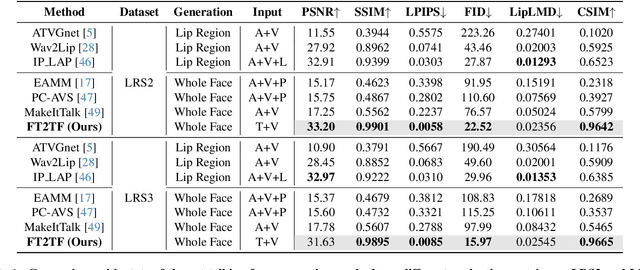
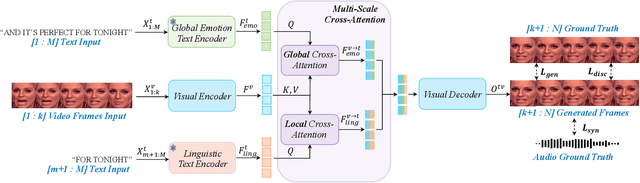
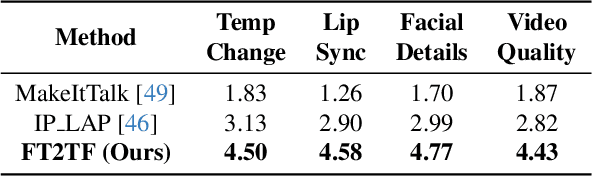
Talking face generation has gained immense popularity in the computer vision community, with various applications including AR/VR, teleconferencing, digital assistants, and avatars. Traditional methods are mainly audio-driven ones which have to deal with the inevitable resource-intensive nature of audio storage and processing. To address such a challenge, we propose FT2TF - First-Person Statement Text-To-Talking Face Generation, a novel one-stage end-to-end pipeline for talking face generation driven by first-person statement text. Moreover, FT2TF implements accurate manipulation of the facial expressions by altering the corresponding input text. Different from previous work, our model only leverages visual and textual information without any other sources (e.g. audio/landmark/pose) during inference. Extensive experiments are conducted on LRS2 and LRS3 datasets, and results on multi-dimensional evaluation metrics are reported. Both quantitative and qualitative results showcase that FT2TF outperforms existing relevant methods and reaches the state-of-the-art. This achievement highlights our model capability to bridge first-person statements and dynamic face generation, providing insightful guidance for future work.
Localizing Moments in Long Video Via Multimodal Guidance
Feb 26, 2023



The recent introduction of the large-scale long-form MAD dataset for language grounding in videos has enabled researchers to investigate the performance of current state-of-the-art methods in the long-form setup, with unexpected findings. In fact, current grounding methods alone fail at tackling this challenging task and setup due to their inability to process long video sequences. In this work, we propose an effective way to circumvent the long-form burden by introducing a new component to grounding pipelines: a Guidance model. The purpose of the Guidance model is to efficiently remove irrelevant video segments from the search space of grounding methods by coarsely aligning the sentence to chunks of the movies and then applying legacy grounding methods where high correlation is found. We term these video segments as non-describable moments. This two-stage approach reveals to be effective in boosting the performance of several different grounding baselines on the challenging MAD dataset, achieving new state-of-the-art performance.