 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei-Lin Chen
Measuring Taiwanese Mandarin Language Understanding
Mar 29, 2024
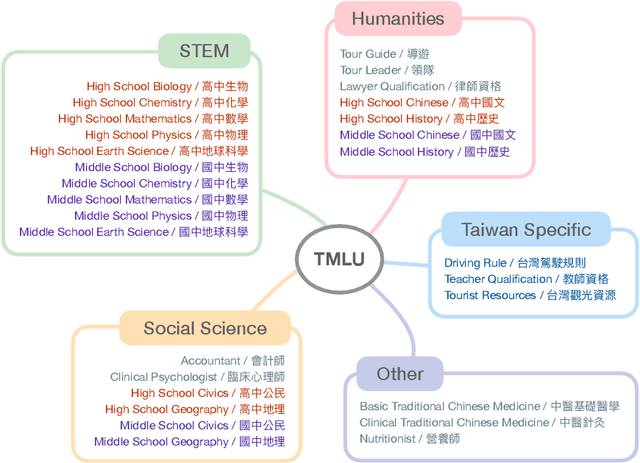

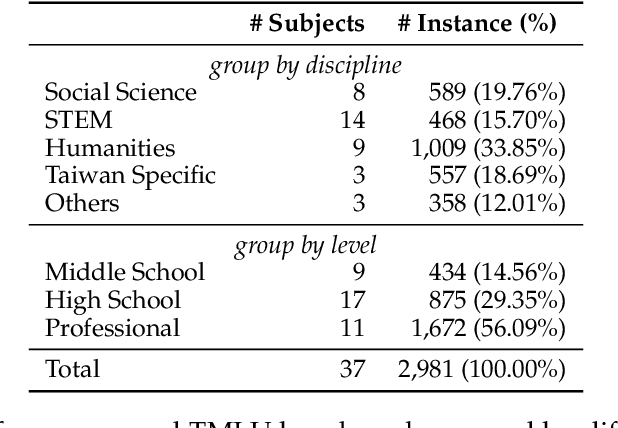

The evaluation of large language models (LLMs) has drawn substantial attention in the field recently. This work focuses on evaluating LLMs in a Chinese context, specifically, for Traditional Chinese which has been largely underrepresented in existing benchmarks. We present TMLU, a holistic evaluation suit tailored for assessing the advanced knowledge and reasoning capability in LLMs, under the context of Taiwanese Mandarin. TMLU consists of an array of 37 subjects across social science, STEM, humanities, Taiwan-specific content, and others, ranging from middle school to professional levels. In addition, we curate chain-of-thought-like few-shot explanations for each subject to facilitate the evaluation of complex reasoning skills. To establish a comprehensive baseline, we conduct extensive experiments and analysis on 24 advanced LLMs. The results suggest that Chinese open-weight models demonstrate inferior performance comparing to multilingual proprietary ones, and open-weight models tailored for Taiwanese Mandarin lag behind the Simplified-Chinese counterparts. The findings indicate great headrooms for improvement, and emphasize the goal of TMLU to foster the development of localized Taiwanese-Mandarin LLMs. We release the benchmark and evaluation scripts for the community to promote future research.
Fidelity-Enriched Contrastive Search: Reconciling the Faithfulness-Diversity Trade-Off in Text Generation
Oct 23, 2023In this paper, we address the hallucination problem commonly found in natural language generation tasks. Language models often generate fluent and convincing content but can lack consistency with the provided source, resulting in potential inaccuracies. We propose a new decoding method called Fidelity-Enriched Contrastive Search (FECS), which augments the contrastive search framework with context-aware regularization terms. FECS promotes tokens that are semantically similar to the provided source while penalizing repetitiveness in the generated text. We demonstrate its effectiveness across two tasks prone to hallucination: abstractive summarization and dialogue generation. Results show that FECS consistently enhances faithfulness across various language model sizes while maintaining output diversity comparable to well-performing decoding algorithms.
Large Language Models Perform Diagnostic Reasoning
Jul 18, 2023



We explore the extension of chain-of-thought (CoT) prompting to medical reasoning for the task of automatic diagnosis. Motivated by doctors' underlying reasoning process, we present Diagnostic-Reasoning CoT (DR-CoT). Empirical results demonstrate that by simply prompting large language models trained only on general text corpus with two DR-CoT exemplars, the diagnostic accuracy improves by 15% comparing to standard prompting. Moreover, the gap reaches a pronounced 18% in out-domain settings. Our findings suggest expert-knowledge reasoning in large language models can be elicited through proper promptings.
Self-ICL: Zero-Shot In-Context Learning with Self-Generated Demonstrations
May 24, 2023



Large language models (LMs) have exhibited superior in-context learning (ICL) ability to adopt to target tasks by prompting with a few input-output demonstrations. Towards better ICL, different methods are proposed to select representative demonstrations from existing training corpora. However, such a setting is not aligned with real-world practices, as end-users usually query LMs without accesses to demonstration pools. Inspired by evidence suggesting LMs' zero-shot capabilities are underrated, and the role of demonstrations are primarily for exposing models' intrinsic functionalities, we introduce Self-ICL, a simple framework for zero-shot ICL. Given a test input, Self-ICL first prompts the model to generate pseudo-inputs. Next, the model predicts pseudo-labels for the pseudo-inputs via zero-shot prompting. Finally, we construct pseudo-demonstrations from pseudo-input-label pairs, and perform ICL for the test input. Evaluation on BIG-Bench Hard shows Self-ICL steadily surpasses zero-shot and zero-shot chain-of-thought baselines on head-to-head and all-task average performance. Our findings suggest the possibility to bootstrap LMs' intrinsic capabilities towards better zero-shot performance.
ZARA: Improving Few-Shot Self-Rationalization for Small Language Models
May 12, 2023



Language models (LMs) that jointly generate end-task answers as well as free-text rationales are known as self-rationalization models. Recent works demonstrate great performance gain for self-rationalization by few-shot prompting LMs with rationale-augmented exemplars. However, the ability to benefit from explanations only emerges with large-scale LMs, which have poor accessibility. In this work, we explore the less-studied setting of leveraging explanations for small LMs to improve few-shot self-rationalization. We first revisit the relationship between rationales and answers. Inspired by the implicit mental process of how human beings assess explanations, we present a novel approach, Zero-shot Augmentation of Rationale-Answer pairs (ZARA), to automatically construct pseudo-parallel data for self-training by reducing the problem of plausibility judgement to natural language inference. Experimental results show ZARA achieves SOTA performance on the FEB benchmark, for both the task accuracy and the explanation metric. In addition, we conduct human and quantitative evaluation validating ZARA's ability to automatically identify plausible and accurate rationale-answer pairs.