 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei-Yin Loh
Variable importance scores
Feb 13, 2021

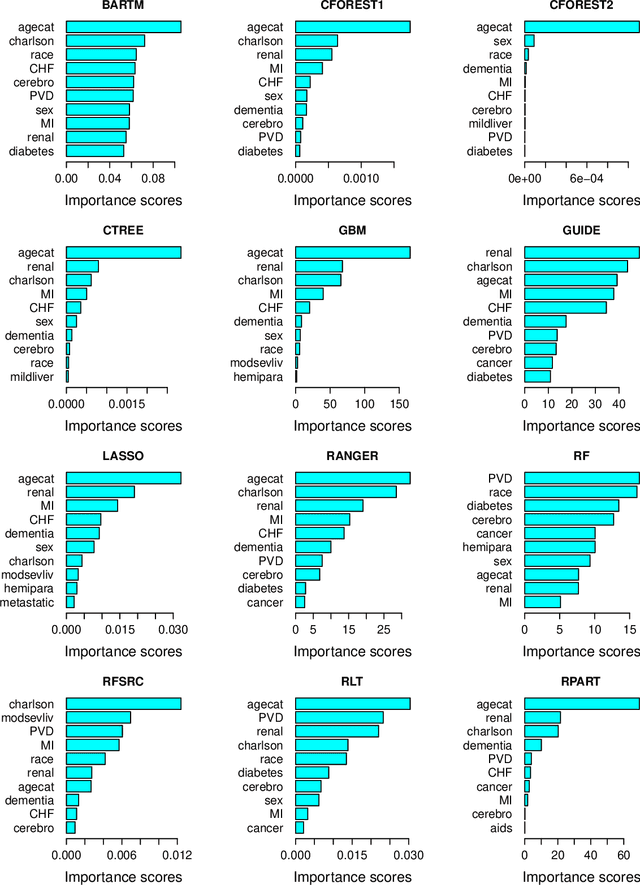
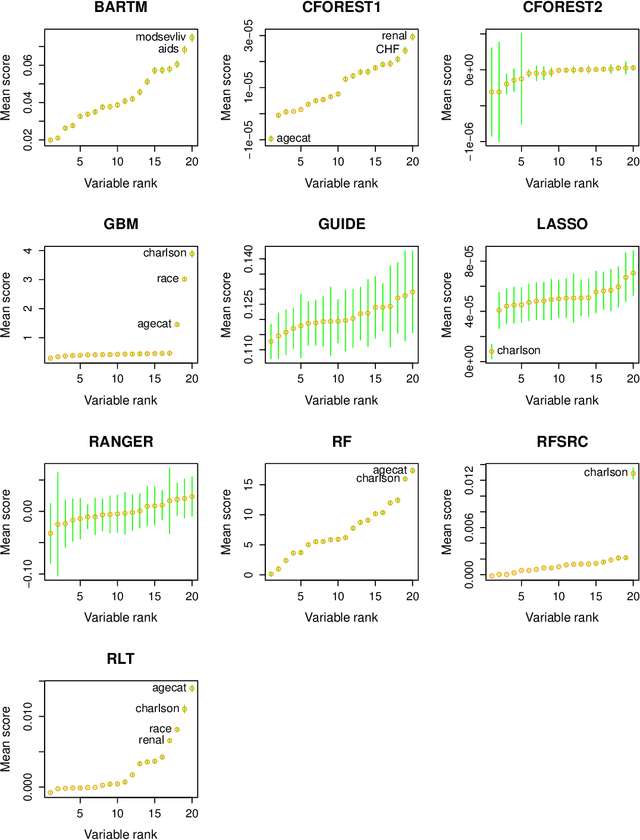
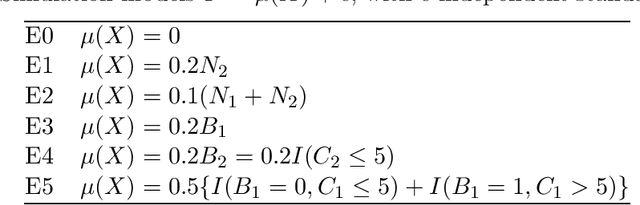
Scoring of variables for importance in predicting a response is an ill-defined concept. Several methods have been proposed but little is known of their performance. This paper fills the gap with a comparative evaluation of eleven methods and an updated one based on the GUIDE algorithm. For data without missing values, eight of the methods are shown to be biased in that they give higher or lower scores to different types of variables, even when all are independent of the response. Of the remaining four methods, only two are applicable to data with missing values, with GUIDE the only unbiased one. GUIDE achieves unbiasedness by using a self-calibrating step that is applicable to other methods for score de-biasing. GUIDE also yields a threshold for distinguishing important from unimportant variables at 95 and 99 percent confidence levels; the technique is applicable to other methods as well. Finally, the paper studies the relationship of the scores to predictive power in three data sets. It is found that the scores of many methods are more consistent with marginal predictive power than conditional predictive power.
PLUTO: Penalized Unbiased Logistic Regression Trees
Nov 25, 2014
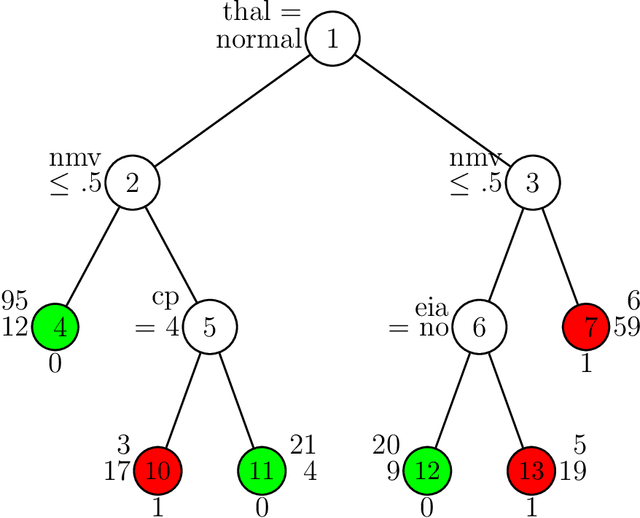
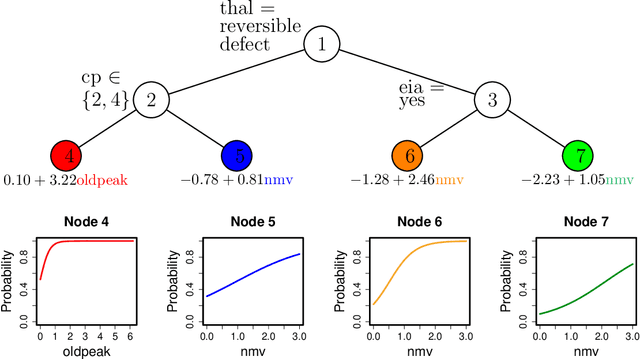

We propose a new algorithm called PLUTO for building logistic regression trees to binary response data. PLUTO can capture the nonlinear and interaction patterns in messy data by recursively partitioning the sample space. It fits a simple or a multiple linear logistic regression model in each partition. PLUTO employs the cyclical coordinate descent method for estimation of multiple linear logistic regression models with elastic net penalties, which allows it to deal with high-dimensional data efficiently. The tree structure comprises a graphical description of the data. Together with the logistic regression models, it provides an accurate classifier as well as a piecewise smooth estimate of the probability of "success". PLUTO controls selection bias by: (1) separating split variable selection from split point selection; (2) applying an adjusted chi-squared test to find the split variable instead of exhaustive search. A bootstrap calibration technique is employed to further correct selection bias. Comparison on real datasets shows that on average, the multiple linear PLUTO models predict more accurately than other algorithms.
Regression trees for longitudinal and multiresponse data
May 27, 2013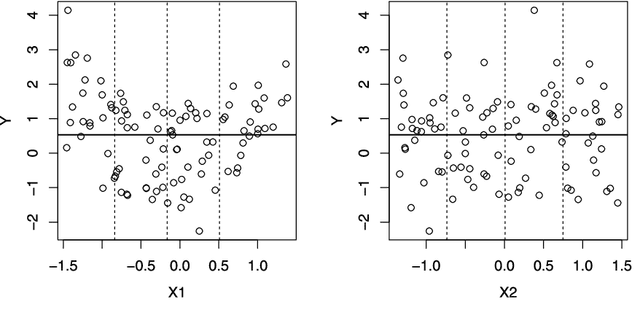
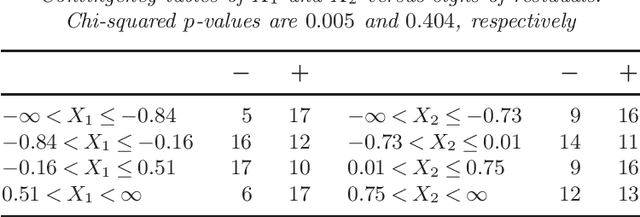
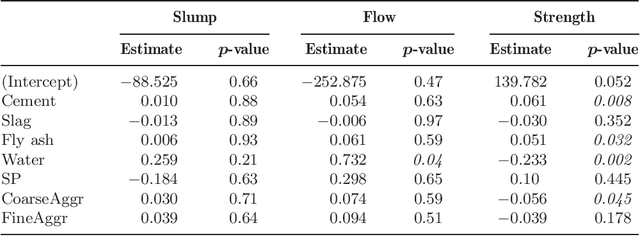
Previous algorithms for constructing regression tree models for longitudinal and multiresponse data have mostly followed the CART approach. Consequently, they inherit the same selection biases and computational difficulties as CART. We propose an alternative, based on the GUIDE approach, that treats each longitudinal data series as a curve and uses chi-squared tests of the residual curve patterns to select a variable to split each node of the tree. Besides being unbiased, the method is applicable to data with fixed and random time points and with missing values in the response or predictor variables. Simulation results comparing its mean squared prediction error with that of MVPART are given, as well as examples comparing it with standard linear mixed effects and generalized estimating equation models. Conditions for asymptotic consistency of regression tree function estimates are also given.
* Published in at http://dx.doi.org/10.1214/12-AOAS596 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)