 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeijia Li
3D Building Reconstruction from Monocular Remote Sensing Images with Multi-level Supervisions
Apr 07, 2024
3D building reconstruction from monocular remote sensing images is an important and challenging research problem that has received increasing attention in recent years, owing to its low cost of data acquisition and availability for large-scale applications. However, existing methods rely on expensive 3D-annotated samples for fully-supervised training, restricting their application to large-scale cross-city scenarios. In this work, we propose MLS-BRN, a multi-level supervised building reconstruction network that can flexibly utilize training samples with different annotation levels to achieve better reconstruction results in an end-to-end manner. To alleviate the demand on full 3D supervision, we design two new modules, Pseudo Building Bbox Calculator and Roof-Offset guided Footprint Extractor, as well as new tasks and training strategies for different types of samples. Experimental results on several public and new datasets demonstrate that our proposed MLS-BRN achieves competitive performance using much fewer 3D-annotated samples, and significantly improves the footprint extraction and 3D reconstruction performance compared with current state-of-the-art. The code and datasets of this work will be released at https://github.com/opendatalab/MLS-BRN.git.
SG-BEV: Satellite-Guided BEV Fusion for Cross-View Semantic Segmentation
Apr 03, 2024This paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using satellite and street-view image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code and datasets of this work will be released at https://github.com/yejy53/SG-BEV.
H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model
Mar 29, 2024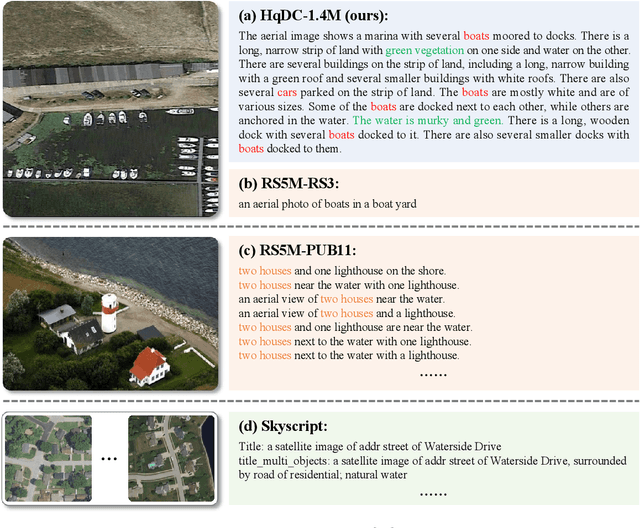
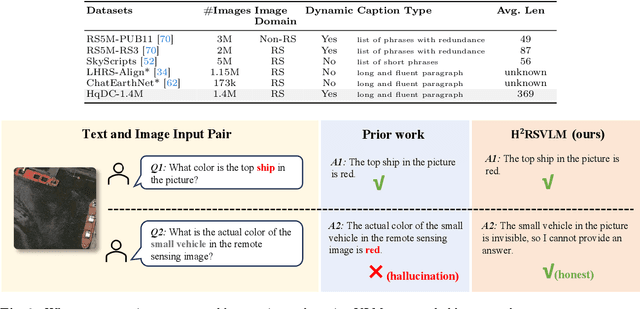
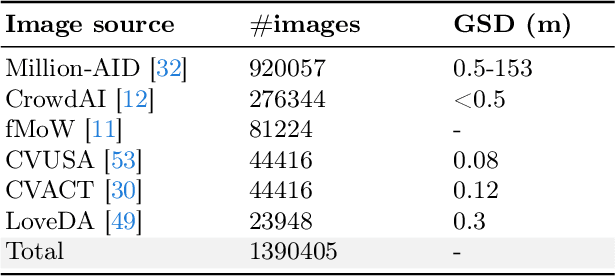

The generic large Vision-Language Models (VLMs) is rapidly developing, but still perform poorly in Remote Sensing (RS) domain, which is due to the unique and specialized nature of RS imagery and the comparatively limited spatial perception of current VLMs. Existing Remote Sensing specific Vision Language Models (RSVLMs) still have considerable potential for improvement, primarily owing to the lack of large-scale, high-quality RS vision-language datasets. We constructed HqDC-1.4M, the large scale High quality and Detailed Captions for RS images, containing 1.4 million image-caption pairs, which not only enhance the RSVLM's understanding of RS images but also significantly improve the model's spatial perception abilities, such as localization and counting, thereby increasing the helpfulness of the RSVLM. Moreover, to address the inevitable "hallucination" problem in RSVLM, we developed RSSA, the first dataset aimed at enhancing the Self-Awareness capability of RSVLMs. By incorporating a variety of unanswerable questions into typical RS visual question-answering tasks, RSSA effectively improves the truthfulness and reduces the hallucinations of the model's outputs, thereby enhancing the honesty of the RSVLM. Based on these datasets, we proposed the H2RSVLM, the Helpful and Honest Remote Sensing Vision Language Model. H2RSVLM has achieved outstanding performance on multiple RS public datasets and is capable of recognizing and refusing to answer the unanswerable questions, effectively mitigating the incorrect generations. We will release the code, data and model weights at https://github.com/opendatalab/H2RSVLM .
Building Bridges across Spatial and Temporal Resolutions: Reference-Based Super-Resolution via Change Priors and Conditional Diffusion Model
Mar 26, 2024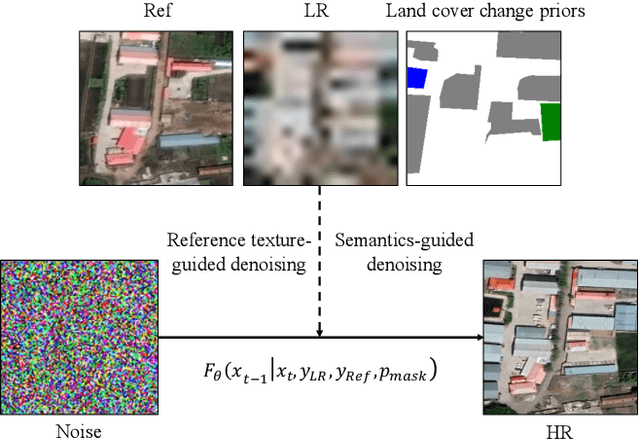
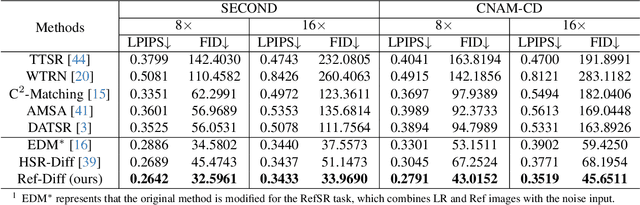
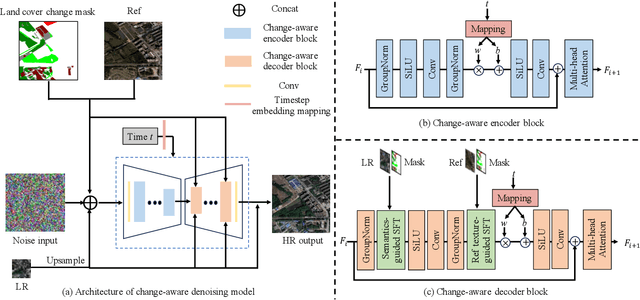

Reference-based super-resolution (RefSR) has the potential to build bridges across spatial and temporal resolutions of remote sensing images. However, existing RefSR methods are limited by the faithfulness of content reconstruction and the effectiveness of texture transfer in large scaling factors. Conditional diffusion models have opened up new opportunities for generating realistic high-resolution images, but effectively utilizing reference images within these models remains an area for further exploration. Furthermore, content fidelity is difficult to guarantee in areas without relevant reference information. To solve these issues, we propose a change-aware diffusion model named Ref-Diff for RefSR, using the land cover change priors to guide the denoising process explicitly. Specifically, we inject the priors into the denoising model to improve the utilization of reference information in unchanged areas and regulate the reconstruction of semantically relevant content in changed areas. With this powerful guidance, we decouple the semantics-guided denoising and reference texture-guided denoising processes to improve the model performance. Extensive experiments demonstrate the superior effectiveness and robustness of the proposed method compared with state-of-the-art RefSR methods in both quantitative and qualitative evaluations. The code and data are available at https://github.com/dongrunmin/RefDiff.
Parrot Captions Teach CLIP to Spot Text
Dec 28, 2023Despite CLIP being the foundation model in numerous vision-language applications, the CLIP suffers from a severe text spotting bias. Such bias causes CLIP models to 'Parrot' the visual text embedded within images while disregarding the authentic visual semantics. We uncover that in the most popular image-text dataset LAION-2B, the captions also densely parrot (spell) the text embedded in images. Our analysis shows that around 50% of images are embedded with visual text content, and 90% of their captions more or less parrot the visual text. Based on such observation, we thoroughly inspect the different released versions of CLIP models and verify that the visual text is the dominant factor in measuring the LAION-style image-text similarity for these models. To examine whether these parrot captions shape the text spotting bias, we train a series of CLIP models with LAION subsets curated by different parrot-caption-oriented criteria. We show that training with parrot captions easily shapes such bias but harms the expected visual-language representation learning in CLIP models. This suggests that it is urgent to revisit either the design of CLIP-like models or the existing image-text dataset curation pipeline built on CLIP score filtering.
A review of individual tree crown detection and delineation from optical remote sensing images
Oct 20, 2023Powered by the advances of optical remote sensing sensors, the production of very high spatial resolution multispectral images provides great potential for achieving cost-efficient and high-accuracy forest inventory and analysis in an automated way. Lots of studies that aim at providing an inventory to the level of each individual tree have generated a variety of methods for Individual Tree Crown Detection and Delineation (ITCD). This review covers ITCD methods for detecting and delineating individual tree crowns, and systematically reviews the past and present of ITCD-related researches applied to the optical remote sensing images. With the goal to provide a clear knowledge map of existing ITCD efforts, we conduct a comprehensive review of recent ITCD papers to build a meta-data analysis, including the algorithm, the study site, the tree species, the sensor type, the evaluation method, etc. We categorize the reviewed methods into three classes: (1) traditional image processing methods (such as local maximum filtering, image segmentation, etc.); (2) traditional machine learning methods (such as random forest, decision tree, etc.); and (3) deep learning based methods. With the deep learning-oriented approaches contributing a majority of the papers, we further discuss the deep learning-based methods as semantic segmentation and object detection methods. In addition, we discuss four ITCD-related issues to further comprehend the ITCD domain using optical remote sensing data, such as comparisons between multi-sensor based data and optical data in ITCD domain, comparisons among different algorithms and different ITCD tasks, etc. Finally, this review proposes some ITCD-related applications and a few exciting prospects and potential hot topics in future ITCD research.
VIGC: Visual Instruction Generation and Correction
Sep 11, 2023



The integration of visual encoders and large language models (LLMs) has driven recent progress in multimodal large language models (MLLMs). However, the scarcity of high-quality instruction-tuning data for vision-language tasks remains a challenge. The current leading paradigm, such as LLaVA, relies on language-only GPT-4 to generate data, which requires pre-annotated image captions and detection bounding boxes, suffering from understanding image details. A practical solution to this problem would be to utilize the available multimodal large language models (MLLMs) to generate instruction data for vision-language tasks. However, it's worth noting that the currently accessible MLLMs are not as powerful as their LLM counterparts, as they tend to produce inadequate responses and generate false information. As a solution for addressing the current issue, this paper proposes the Visual Instruction Generation and Correction (VIGC) framework that enables multimodal large language models to generate instruction-tuning data and progressively enhance its quality on-the-fly. Specifically, Visual Instruction Generation (VIG) guides the vision-language model to generate diverse instruction-tuning data. To ensure generation quality, Visual Instruction Correction (VIC) adopts an iterative update mechanism to correct any inaccuracies in data produced by VIG, effectively reducing the risk of hallucination. Leveraging the diverse, high-quality data generated by VIGC, we finetune mainstream models and validate data quality based on various evaluations. Experimental results demonstrate that VIGC not only compensates for the shortcomings of language-only data generation methods, but also effectively enhances the benchmark performance. The models, datasets, and code are available at https://opendatalab.github.io/VIGC.
SEPT: Towards Scalable and Efficient Visual Pre-Training
Dec 11, 2022



Recently, the self-supervised pre-training paradigm has shown great potential in leveraging large-scale unlabeled data to improve downstream task performance. However, increasing the scale of unlabeled pre-training data in real-world scenarios requires prohibitive computational costs and faces the challenge of uncurated samples. To address these issues, we build a task-specific self-supervised pre-training framework from a data selection perspective based on a simple hypothesis that pre-training on the unlabeled samples with similar distribution to the target task can bring substantial performance gains. Buttressed by the hypothesis, we propose the first yet novel framework for Scalable and Efficient visual Pre-Training (SEPT) by introducing a retrieval pipeline for data selection. SEPT first leverage a self-supervised pre-trained model to extract the features of the entire unlabeled dataset for retrieval pipeline initialization. Then, for a specific target task, SEPT retrievals the most similar samples from the unlabeled dataset based on feature similarity for each target instance for pre-training. Finally, SEPT pre-trains the target model with the selected unlabeled samples in a self-supervised manner for target data finetuning. By decoupling the scale of pre-training and available upstream data for a target task, SEPT achieves high scalability of the upstream dataset and high efficiency of pre-training, resulting in high model architecture flexibility. Results on various downstream tasks demonstrate that SEPT can achieve competitive or even better performance compared with ImageNet pre-training while reducing the size of training samples by one magnitude without resorting to any extra annotations.
OmniCity: Omnipotent City Understanding with Multi-level and Multi-view Images
Aug 04, 2022
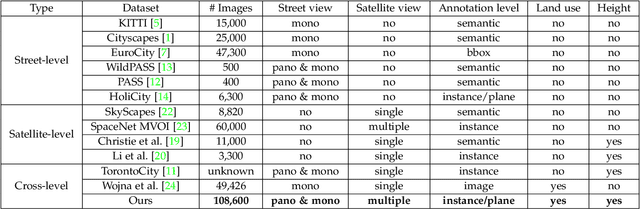
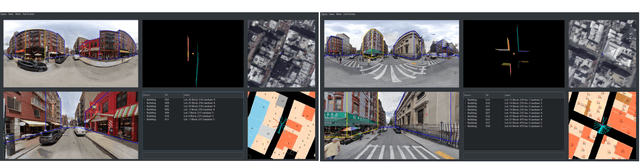

This paper presents OmniCity, a new dataset for omnipotent city understanding from multi-level and multi-view images. More precisely, the OmniCity contains multi-view satellite images as well as street-level panorama and mono-view images, constituting over 100K pixel-wise annotated images that are well-aligned and collected from 25K geo-locations in New York City. To alleviate the substantial pixel-wise annotation efforts, we propose an efficient street-view image annotation pipeline that leverages the existing label maps of satellite view and the transformation relations between different views (satellite, panorama, and mono-view). With the new OmniCity dataset, we provide benchmarks for a variety of tasks including building footprint extraction, height estimation, and building plane/instance/fine-grained segmentation. Compared with the existing multi-level and multi-view benchmarks, OmniCity contains a larger number of images with richer annotation types and more views, provides more benchmark results of state-of-the-art models, and introduces a novel task for fine-grained building instance segmentation on street-level panorama images. Moreover, OmniCity provides new problem settings for existing tasks, such as cross-view image matching, synthesis, segmentation, detection, etc., and facilitates the developing of new methods for large-scale city understanding, reconstruction, and simulation. The OmniCity dataset as well as the benchmarks will be available at https://city-super.github.io/omnicity.
Unified Interactive Image Matting
May 23, 2022



Recent image matting studies are developing towards proposing trimap-free or interactive methods for complete complex image matting tasks. Although avoiding the extensive labors of trimap annotation, existing methods still suffer from two limitations: (1) For the single image with multiple objects, it is essential to provide extra interaction information to help determining the matting target; (2) For transparent objects, the accurate regression of alpha matte from RGB image is much more difficult compared with the opaque ones. In this work, we propose a Unified Interactive image Matting method, named UIM, which solves the limitations and achieves satisfying matting results for any scenario. Specifically, UIM leverages multiple types of user interaction to avoid the ambiguity of multiple matting targets, and we compare the pros and cons of different annotation types in detail. To unify the matting performance for transparent and opaque objects, we decouple image matting into two stages, i.e., foreground segmentation and transparency prediction. Moreover, we design a multi-scale attentive fusion module to alleviate the vagueness in the boundary region. Experimental results demonstrate that UIM achieves state-of-the-art performance on the Composition-1K test set and a synthetic unified dataset. Our code and models will be released soon.