 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeijian Deng
An Empirical Study Into What Matters for Calibrating Vision-Language Models
Feb 12, 2024
Vision--Language Models (VLMs) have emerged as the dominant approach for zero-shot recognition, adept at handling diverse scenarios and significant distribution changes. However, their deployment in risk-sensitive areas requires a deeper understanding of their uncertainty estimation capabilities, a relatively uncharted area. In this study, we explore the calibration properties of VLMs across different architectures, datasets, and training strategies. In particular, we analyze the uncertainty estimation performance of VLMs when calibrated in one domain, label set or hierarchy level, and tested in a different one. Our findings reveal that while VLMs are not inherently calibrated for uncertainty, temperature scaling significantly and consistently improves calibration, even across shifts in distribution and changes in label set. Moreover, VLMs can be calibrated with a very small set of examples. Through detailed experimentation, we highlight the potential applications and importance of our insights, aiming for more reliable and effective use of VLMs in critical, real-world scenarios.
A Closer Look at the Robustness of Contrastive Language-Image Pre-Training (CLIP)
Feb 12, 2024Contrastive Language-Image Pre-training (CLIP) models have demonstrated remarkable generalization capabilities across multiple challenging distribution shifts. However, there is still much to be explored in terms of their robustness to the variations of specific visual factors. In real-world applications, reliable and safe systems must consider other safety objectives beyond classification accuracy, such as predictive uncertainty. Yet, the effectiveness of CLIP models on such safety-related features is less-explored. Driven by the above, this work comprehensively investigates the safety objectives of CLIP models, specifically focusing on three key properties: resilience to visual factor variations, calibrated uncertainty estimations, and the ability to detect anomalous inputs. To this end, we study 83 CLIP models and 127 ImageNet classifiers. They are diverse in architecture, (pre)training distribution and training strategies. We consider 10 visual factors (e.g., shape and pattern), 5 types of out-of-distribution data, and 8 natural and challenging test conditions with different shift types, such as texture, style, and perturbation shifts. Our study has unveiled several previously unknown insights into CLIP models. For instance, they are not consistently more calibrated than other ImageNet models, which contradicts existing findings. Additionally, our analysis underscores the significance of training source design by showcasing its profound influence on the three safety-related properties. We believe our comprehensive study can shed light on and help guide the development of more robust and reliable CLIP models.
3D-GPT: Procedural 3D Modeling with Large Language Models
Oct 19, 2023In the pursuit of efficient automated content creation, procedural generation, leveraging modifiable parameters and rule-based systems, emerges as a promising approach. Nonetheless, it could be a demanding endeavor, given its intricate nature necessitating a deep understanding of rules, algorithms, and parameters. To reduce workload, we introduce 3D-GPT, a framework utilizing large language models~(LLMs) for instruction-driven 3D modeling. 3D-GPT positions LLMs as proficient problem solvers, dissecting the procedural 3D modeling tasks into accessible segments and appointing the apt agent for each task. 3D-GPT integrates three core agents: the task dispatch agent, the conceptualization agent, and the modeling agent. They collaboratively achieve two objectives. First, it enhances concise initial scene descriptions, evolving them into detailed forms while dynamically adapting the text based on subsequent instructions. Second, it integrates procedural generation, extracting parameter values from enriched text to effortlessly interface with 3D software for asset creation. Our empirical investigations confirm that 3D-GPT not only interprets and executes instructions, delivering reliable results but also collaborates effectively with human designers. Furthermore, it seamlessly integrates with Blender, unlocking expanded manipulation possibilities. Our work highlights the potential of LLMs in 3D modeling, offering a basic framework for future advancements in scene generation and animation.
A Bag-of-Prototypes Representation for Dataset-Level Applications
Mar 23, 2023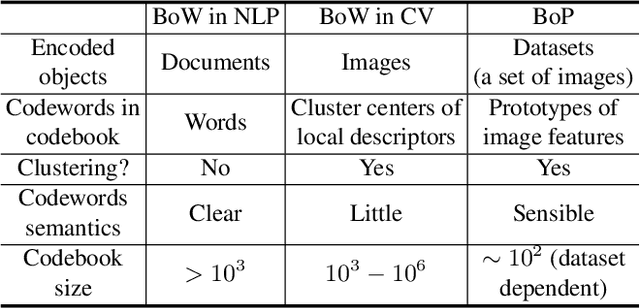
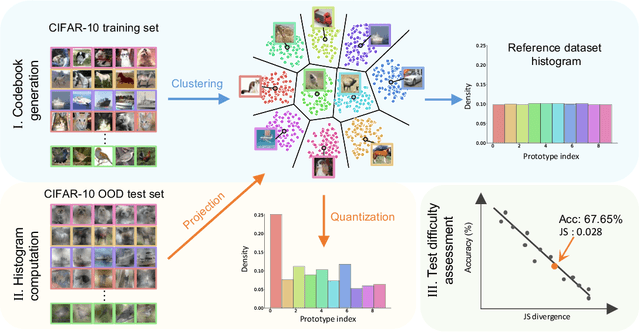
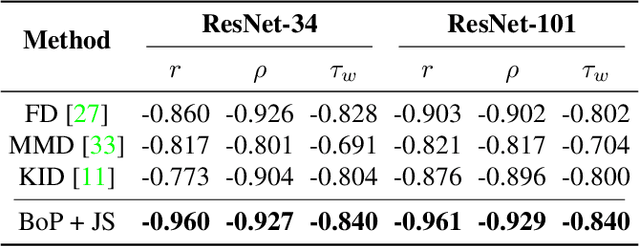
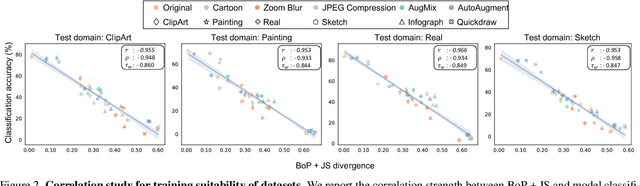
This work investigates dataset vectorization for two dataset-level tasks: assessing training set suitability and test set difficulty. The former measures how suitable a training set is for a target domain, while the latter studies how challenging a test set is for a learned model. Central to the two tasks is measuring the underlying relationship between datasets. This needs a desirable dataset vectorization scheme, which should preserve as much discriminative dataset information as possible so that the distance between the resulting dataset vectors can reflect dataset-to-dataset similarity. To this end, we propose a bag-of-prototypes (BoP) dataset representation that extends the image-level bag consisting of patch descriptors to dataset-level bag consisting of semantic prototypes. Specifically, we develop a codebook consisting of K prototypes clustered from a reference dataset. Given a dataset to be encoded, we quantize each of its image features to a certain prototype in the codebook and obtain a K-dimensional histogram. Without assuming access to dataset labels, the BoP representation provides a rich characterization of the dataset semantic distribution. Furthermore, BoP representations cooperate well with Jensen-Shannon divergence for measuring dataset-to-dataset similarity. Although very simple, BoP consistently shows its advantage over existing representations on a series of benchmarks for two dataset-level tasks.
Adaptive Calibrator Ensemble for Model Calibration under Distribution Shift
Mar 09, 2023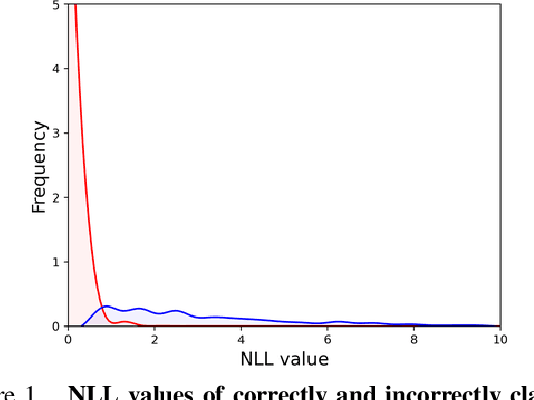
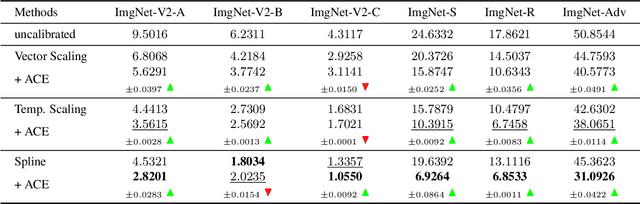
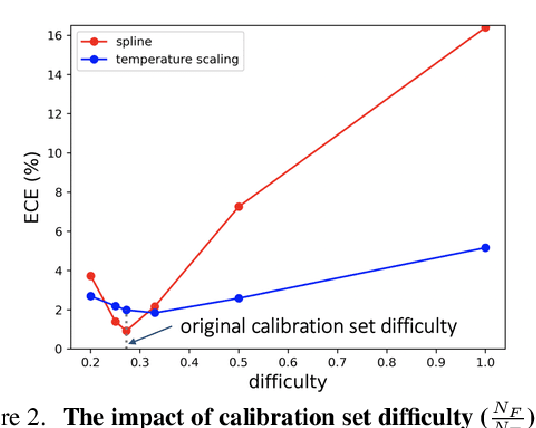

Model calibration usually requires optimizing some parameters (e.g., temperature) w.r.t an objective function (e.g., negative log-likelihood). In this paper, we report a plain, important but often neglected fact that the objective function is influenced by calibration set difficulty, i.e., the ratio of the number of incorrectly classified samples to that of correctly classified samples. If a test set has a drastically different difficulty level from the calibration set, the optimal calibration parameters of the two datasets would be different. In other words, a calibrator optimal on the calibration set would be suboptimal on the OOD test set and thus has degraded performance. With this knowledge, we propose a simple and effective method named adaptive calibrator ensemble (ACE) to calibrate OOD datasets whose difficulty is usually higher than the calibration set. Specifically, two calibration functions are trained, one for in-distribution data (low difficulty), and the other for severely OOD data (high difficulty). To achieve desirable calibration on a new OOD dataset, ACE uses an adaptive weighting method that strikes a balance between the two extreme functions. When plugged in, ACE generally improves the performance of a few state-of-the-art calibration schemes on a series of OOD benchmarks. Importantly, such improvement does not come at the cost of the in-distribution calibration accuracy.
Confidence and Dispersity Speak: Characterising Prediction Matrix for Unsupervised Accuracy Estimation
Feb 02, 2023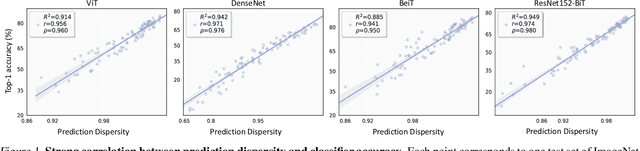
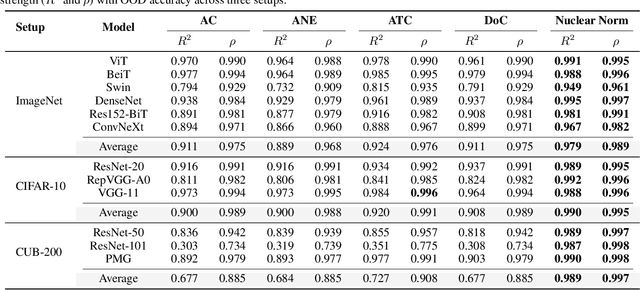
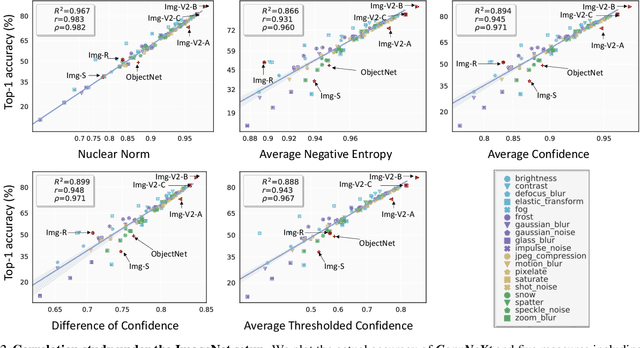
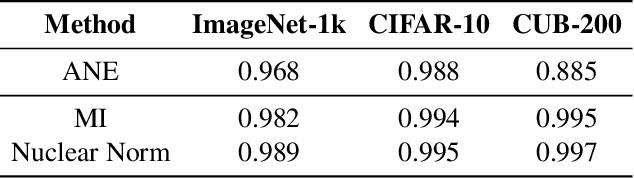
This work aims to assess how well a model performs under distribution shifts without using labels. While recent methods study prediction confidence, this work reports prediction dispersity is another informative cue. Confidence reflects whether the individual prediction is certain; dispersity indicates how the overall predictions are distributed across all categories. Our key insight is that a well-performing model should give predictions with high confidence and high dispersity. That is, we need to consider both properties so as to make more accurate estimates. To this end, we use the nuclear norm that has been shown to be effective in characterizing both properties. Extensive experiments validate the effectiveness of nuclear norm for various models (e.g., ViT and ConvNeXt), different datasets (e.g., ImageNet and CUB-200), and diverse types of distribution shifts (e.g., style shift and reproduction shift). We show that the nuclear norm is more accurate and robust in accuracy estimation than existing methods. Furthermore, we validate the feasibility of other measurements (e.g., mutual information maximization) for characterizing dispersity and confidence. Lastly, we investigate the limitation of the nuclear norm, study its improved variant under severe class imbalance, and discuss potential directions.
On the Strong Correlation Between Model Invariance and Generalization
Jul 14, 2022

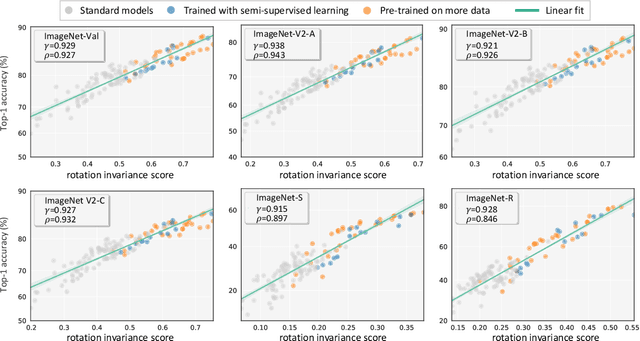
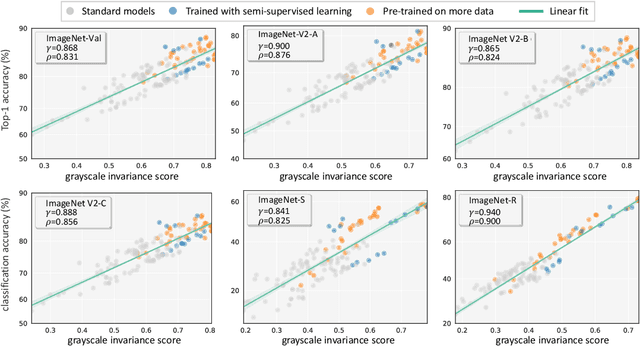
Generalization and invariance are two essential properties of any machine learning model. Generalization captures a model's ability to classify unseen data while invariance measures consistency of model predictions on transformations of the data. Existing research suggests a positive relationship: a model generalizing well should be invariant to certain visual factors. Building on this qualitative implication we make two contributions. First, we introduce effective invariance (EI), a simple and reasonable measure of model invariance which does not rely on image labels. Given predictions on a test image and its transformed version, EI measures how well the predictions agree and with what level of confidence. Second, using invariance scores computed by EI, we perform large-scale quantitative correlation studies between generalization and invariance, focusing on rotation and grayscale transformations. From a model-centric view, we observe generalization and invariance of different models exhibit a strong linear relationship, on both in-distribution and out-of-distribution datasets. From a dataset-centric view, we find a certain model's accuracy and invariance linearly correlated on different test sets. Apart from these major findings, other minor but interesting insights are also discussed.
Ranking Models in Unlabeled New Environments
Sep 06, 2021
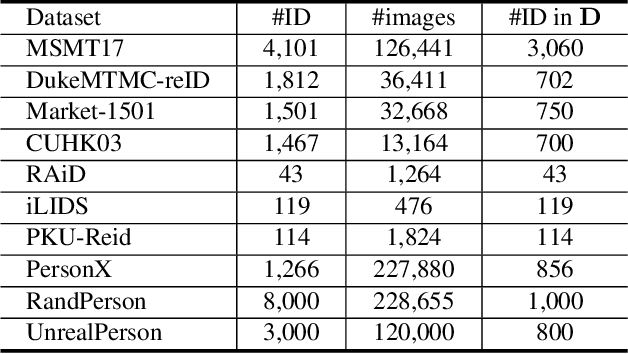
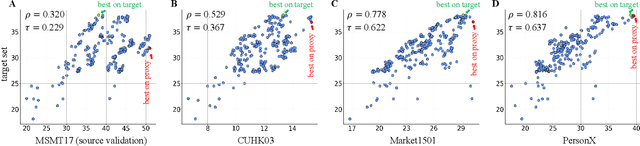
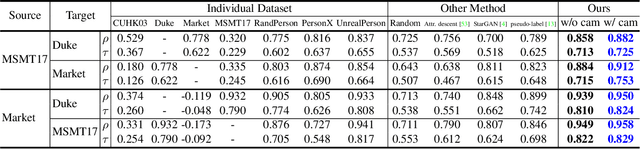
Consider a scenario where we are supplied with a number of ready-to-use models trained on a certain source domain and hope to directly apply the most appropriate ones to different target domains based on the models' relative performance. Ideally we should annotate a validation set for model performance assessment on each new target environment, but such annotations are often very expensive. Under this circumstance, we introduce the problem of ranking models in unlabeled new environments. For this problem, we propose to adopt a proxy dataset that 1) is fully labeled and 2) well reflects the true model rankings in a given target environment, and use the performance rankings on the proxy sets as surrogates. We first select labeled datasets as the proxy. Specifically, datasets that are more similar to the unlabeled target domain are found to better preserve the relative performance rankings. Motivated by this, we further propose to search the proxy set by sampling images from various datasets that have similar distributions as the target. We analyze the problem and its solutions on the person re-identification (re-ID) task, for which sufficient datasets are publicly available, and show that a carefully constructed proxy set effectively captures relative performance ranking in new environments. Code is available at \url{https://github.com/sxzrt/Proxy-Set}.
What Does Rotation Prediction Tell Us about Classifier Accuracy under Varying Testing Environments?
Jun 10, 2021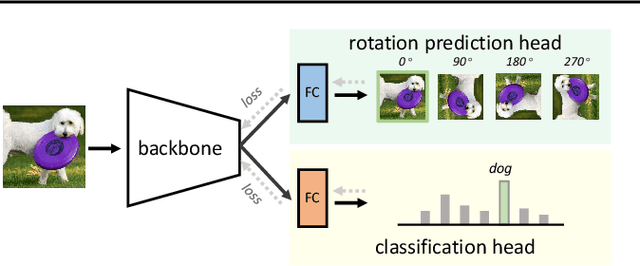
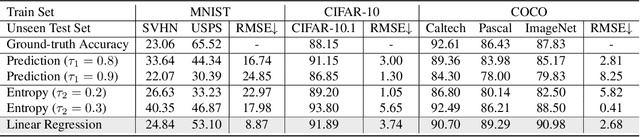

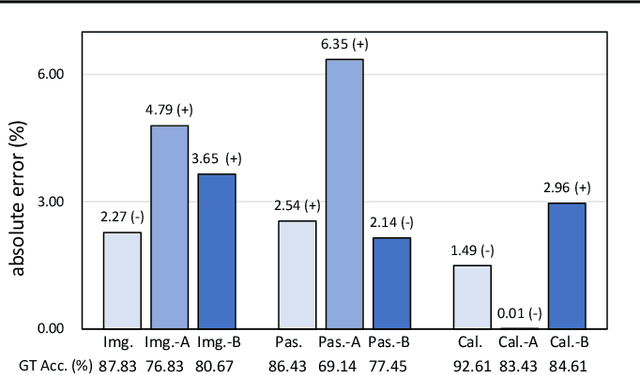
Understanding classifier decision under novel environments is central to the community, and a common practice is evaluating it on labeled test sets. However, in real-world testing, image annotations are difficult and expensive to obtain, especially when the test environment is changing. A natural question then arises: given a trained classifier, can we evaluate its accuracy on varying unlabeled test sets? In this work, we train semantic classification and rotation prediction in a multi-task way. On a series of datasets, we report an interesting finding, i.e., the semantic classification accuracy exhibits a strong linear relationship with the accuracy of the rotation prediction task (Pearson's Correlation r > 0.88). This finding allows us to utilize linear regression to estimate classifier performance from the accuracy of rotation prediction which can be obtained on the test set through the freely generated rotation labels.
Fine-grained Classification via Categorical Memory Networks
Dec 12, 2020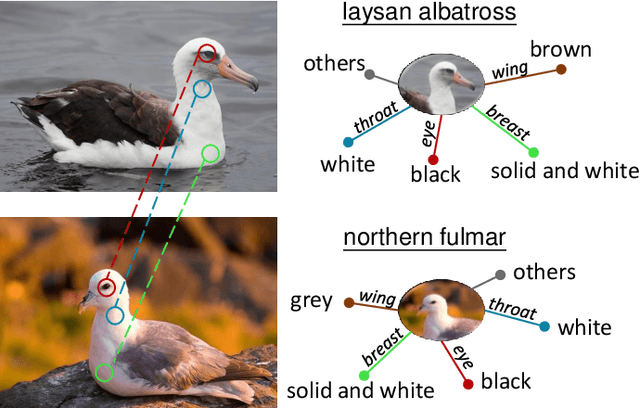


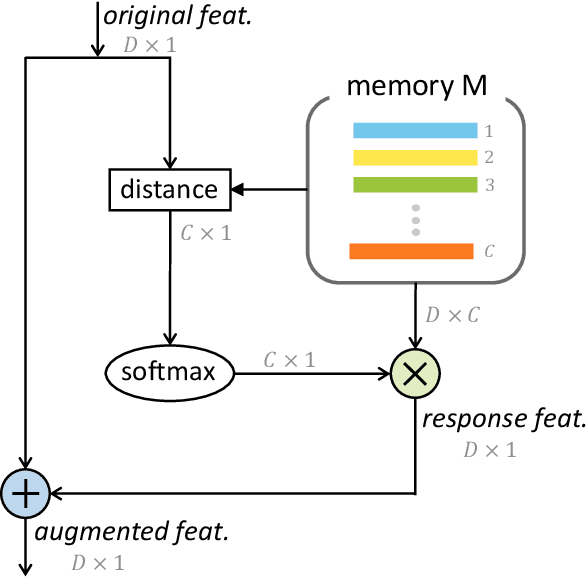
Motivated by the desire to exploit patterns shared across classes, we present a simple yet effective class-specific memory module for fine-grained feature learning. The memory module stores the prototypical feature representation for each category as a moving average. We hypothesize that the combination of similarities with respect to each category is itself a useful discriminative cue. To detect these similarities, we use attention as a querying mechanism. The attention scores with respect to each class prototype are used as weights to combine prototypes via weighted sum, producing a uniquely tailored response feature representation for a given input. The original and response features are combined to produce an augmented feature for classification. We integrate our class-specific memory module into a standard convolutional neural network, yielding a Categorical Memory Network. Our memory module significantly improves accuracy over baseline CNNs, achieving competitive accuracy with state-of-the-art methods on four benchmarks, including CUB-200-2011, Stanford Cars, FGVC Aircraft, and NABirds.