 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeijian Li
Outlier-Efficient Hopfield Layers for Large Transformer-Based Models
Apr 04, 2024
We introduce an Outlier-Efficient Modern Hopfield Model (termed $\mathtt{OutEffHop}$) and use it to address the outlier-induced challenge of quantizing gigantic transformer-based models. Our main contribution is a novel associative memory model facilitating \textit{outlier-efficient} associative memory retrievals. Interestingly, this memory model manifests a model-based interpretation of an outlier-efficient attention mechanism ($\text{Softmax}_1$): it is an approximation of the memory retrieval process of $\mathtt{OutEffHop}$. Methodologically, this allows us to debut novel outlier-efficient Hopfield layers a powerful attention alternative with superior post-quantization performance. Theoretically, the Outlier-Efficient Modern Hopfield Model retains and improves the desirable properties of the standard modern Hopfield models, including fixed point convergence and exponential storage capacity. Empirically, we demonstrate the proposed model's efficacy across large-scale transformer-based and Hopfield-based models (including BERT, OPT, ViT and STanHop-Net), benchmarking against state-of-the-art methods including $\mathtt{Clipped\_Softmax}$ and $\mathtt{Gated\_Attention}$. Notably, $\mathtt{OutEffHop}$ achieves on average $\sim$22+\% reductions in both average kurtosis and maximum infinity norm of model outputs accross 4 models.
BiSHop: Bi-Directional Cellular Learning for Tabular Data with Generalized Sparse Modern Hopfield Model
Apr 04, 2024We introduce the \textbf{B}i-Directional \textbf{S}parse \textbf{Hop}field Network (\textbf{BiSHop}), a novel end-to-end framework for deep tabular learning. BiSHop handles the two major challenges of deep tabular learning: non-rotationally invariant data structure and feature sparsity in tabular data. Our key motivation comes from the recent established connection between associative memory and attention mechanisms. Consequently, BiSHop uses a dual-component approach, sequentially processing data both column-wise and row-wise through two interconnected directional learning modules. Computationally, these modules house layers of generalized sparse modern Hopfield layers, a sparse extension of the modern Hopfield model with adaptable sparsity. Methodologically, BiSHop facilitates multi-scale representation learning, capturing both intra-feature and inter-feature interactions, with adaptive sparsity at each scale. Empirically, through experiments on diverse real-world datasets, we demonstrate that BiSHop surpasses current SOTA methods with significantly less HPO runs, marking it a robust solution for deep tabular learning.
STanHop: Sparse Tandem Hopfield Model for Memory-Enhanced Time Series Prediction
Dec 28, 2023We present STanHop-Net (Sparse Tandem Hopfield Network) for multivariate time series prediction with memory-enhanced capabilities. At the heart of our approach is STanHop, a novel Hopfield-based neural network block, which sparsely learns and stores both temporal and cross-series representations in a data-dependent fashion. In essence, STanHop sequentially learn temporal representation and cross-series representation using two tandem sparse Hopfield layers. In addition, StanHop incorporates two additional external memory modules: a Plug-and-Play module and a Tune-and-Play module for train-less and task-aware memory-enhancements, respectively. They allow StanHop-Net to swiftly respond to certain sudden events. Methodologically, we construct the StanHop-Net by stacking STanHop blocks in a hierarchical fashion, enabling multi-resolution feature extraction with resolution-specific sparsity. Theoretically, we introduce a sparse extension of the modern Hopfield model (Generalized Sparse Modern Hopfield Model) and show that it endows a tighter memory retrieval error compared to the dense counterpart without sacrificing memory capacity. Empirically, we validate the efficacy of our framework on both synthetic and real-world settings.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023
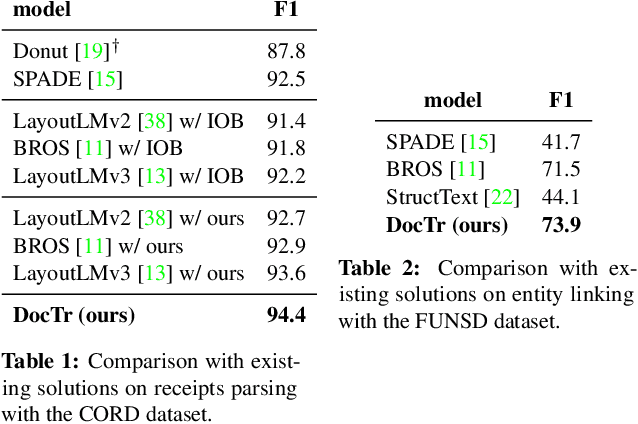
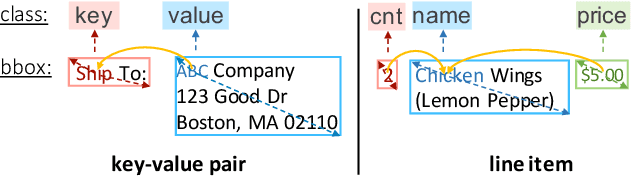
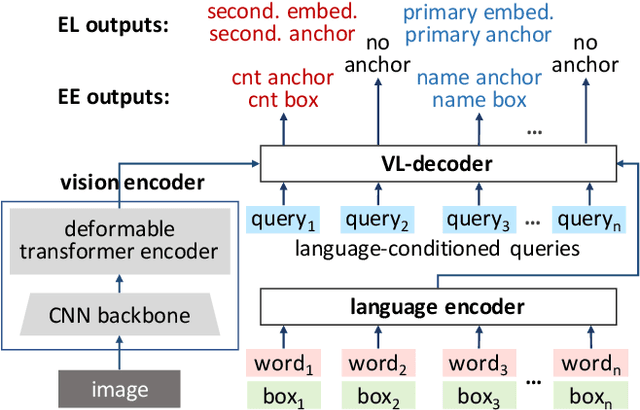
We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genome
Jun 26, 2023Decoding the linguistic intricacies of the genome is a crucial problem in biology, and pre-trained foundational models such as DNABERT and Nucleotide Transformer have made significant strides in this area. Existing works have largely hinged on k-mer, fixed-length permutations of A, T, C, and G, as the token of the genome language due to its simplicity. However, we argue that the computation and sample inefficiencies introduced by k-mer tokenization are primary obstacles in developing large genome foundational models. We provide conceptual and empirical insights into genome tokenization, building on which we propose to replace k-mer tokenization with Byte Pair Encoding (BPE), a statistics-based data compression algorithm that constructs tokens by iteratively merging the most frequent co-occurring genome segment in the corpus. We demonstrate that BPE not only overcomes the limitations of k-mer tokenization but also benefits from the computational efficiency of non-overlapping tokenization. Based on these insights, we introduce DNABERT-2, a refined genome foundation model that adapts an efficient tokenizer and employs multiple strategies to overcome input length constraints, reduce time and memory expenditure, and enhance model capability. Furthermore, we identify the absence of a comprehensive and standardized benchmark for genome understanding as another significant impediment to fair comparative analysis. In response, we propose the Genome Understanding Evaluation (GUE), a comprehensive multi-species genome classification dataset that amalgamates $28$ distinct datasets across $7$ tasks, with input lengths ranging from $70$ to $1000$. Through comprehensive experiments on the GUE benchmark, we demonstrate that DNABERT-2 achieves comparable performance to the state-of-the-art model with $21 \times$ fewer parameters and approximately $56 \times$ less GPU time in pre-training.
Feature Programming for Multivariate Time Series Prediction
Jun 09, 2023



We introduce the concept of programmable feature engineering for time series modeling and propose a feature programming framework. This framework generates large amounts of predictive features for noisy multivariate time series while allowing users to incorporate their inductive bias with minimal effort. The key motivation of our framework is to view any multivariate time series as a cumulative sum of fine-grained trajectory increments, with each increment governed by a novel spin-gas dynamical Ising model. This fine-grained perspective motivates the development of a parsimonious set of operators that summarize multivariate time series in an abstract fashion, serving as the foundation for large-scale automated feature engineering. Numerically, we validate the efficacy of our method on several synthetic and real-world noisy time series datasets.
Unsupervised Self-Driving Attention Prediction via Uncertainty Mining and Knowledge Embedding
Mar 22, 2023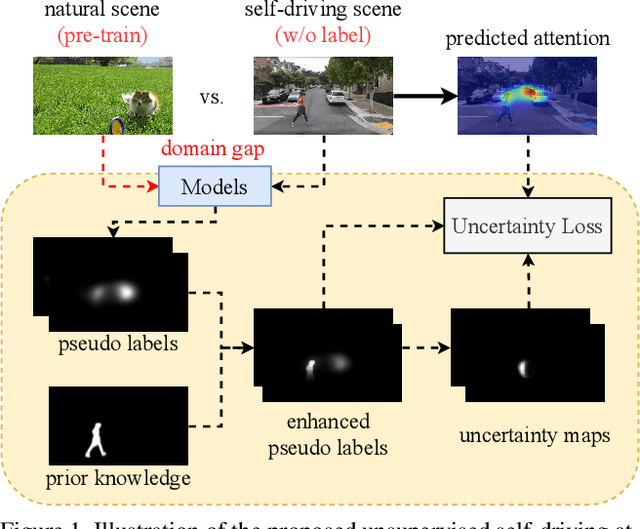
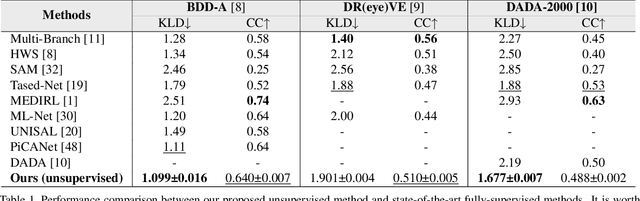
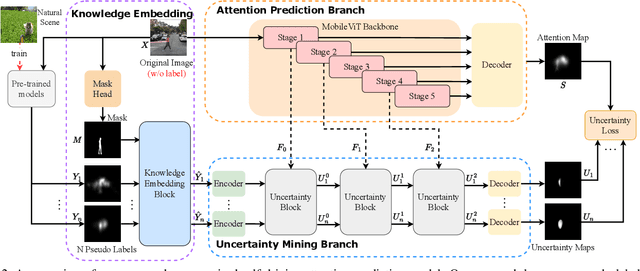

Predicting attention regions of interest is an important yet challenging task for self-driving systems. Existing methodologies rely on large-scale labeled traffic datasets that are labor-intensive to obtain. Besides, the huge domain gap between natural scenes and traffic scenes in current datasets also limits the potential for model training. To address these challenges, we are the first to introduce an unsupervised way to predict self-driving attention by uncertainty modeling and driving knowledge integration. Our approach's Uncertainty Mining Branch (UMB) discovers commonalities and differences from multiple generated pseudo-labels achieved from models pre-trained on natural scenes by actively measuring the uncertainty. Meanwhile, our Knowledge Embedding Block (KEB) bridges the domain gap by incorporating driving knowledge to adaptively refine the generated pseudo-labels. Quantitative and qualitative results with equivalent or even more impressive performance compared to fully-supervised state-of-the-art approaches across all three public datasets demonstrate the effectiveness of the proposed method and the potential of this direction. The code will be made publicly available.
Interdisciplinary Discovery of Nanomaterials Based on Convolutional Neural Networks
Dec 06, 2022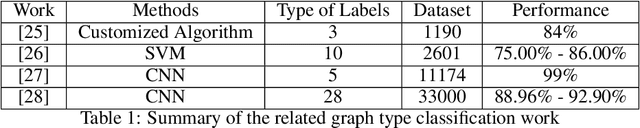

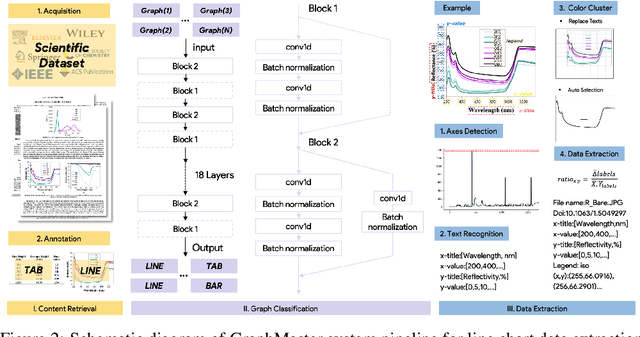
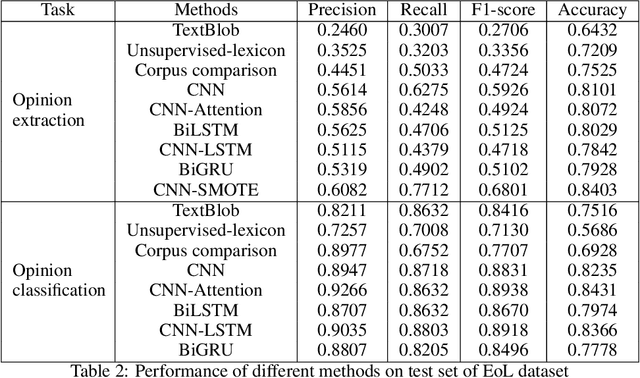
The material science literature contains up-to-date and comprehensive scientific knowledge of materials. However, their content is unstructured and diverse, resulting in a significant gap in providing sufficient information for material design and synthesis. To this end, we used natural language processing (NLP) and computer vision (CV) techniques based on convolutional neural networks (CNN) to discover valuable experimental-based information about nanomaterials and synthesis methods in energy-material-related publications. Our first system, TextMaster, extracts opinions from texts and classifies them into challenges and opportunities, achieving 94% and 92% accuracy, respectively. Our second system, GraphMaster, realizes data extraction of tables and figures from publications with 98.3\% classification accuracy and 4.3% data extraction mean square error. Our results show that these systems could assess the suitability of materials for a certain application by evaluation of synthesis insights and case analysis with detailed references. This work offers a fresh perspective on mining knowledge from scientific literature, providing a wide swatch to accelerate nanomaterial research through CNN.
Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate
Oct 14, 2022



Decentralized optimization is an emerging paradigm in distributed learning in which agents achieve network-wide solutions by peer-to-peer communication without the central server. Since communication tends to be slower than computation, when each agent communicates with only a few neighboring agents per iteration, they can complete iterations faster than with more agents or a central server. However, the total number of iterations to reach a network-wide solution is affected by the speed at which the agents' information is ``mixed'' by communication. We found that popular communication topologies either have large maximum degrees (such as stars and complete graphs) or are ineffective at mixing information (such as rings and grids). To address this problem, we propose a new family of topologies, EquiTopo, which has an (almost) constant degree and a network-size-independent consensus rate that is used to measure the mixing efficiency. In the proposed family, EquiStatic has a degree of $\Theta(\ln(n))$, where $n$ is the network size, and a series of time-dependent one-peer topologies, EquiDyn, has a constant degree of 1. We generate EquiDyn through a certain random sampling procedure. Both of them achieve an $n$-independent consensus rate. We apply them to decentralized SGD and decentralized gradient tracking and obtain faster communication and better convergence, theoretically and empirically. Our code is implemented through BlueFog and available at \url{https://github.com/kexinjinnn/EquiTopo}
Causal Inference via Nonlinear Variable Decorrelation for Healthcare Applications
Sep 29, 2022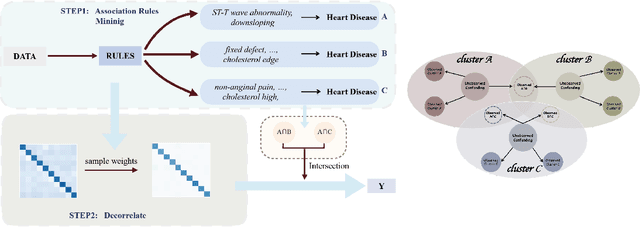
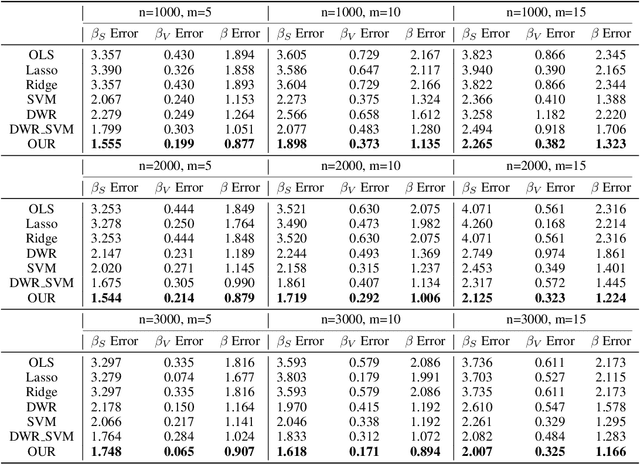
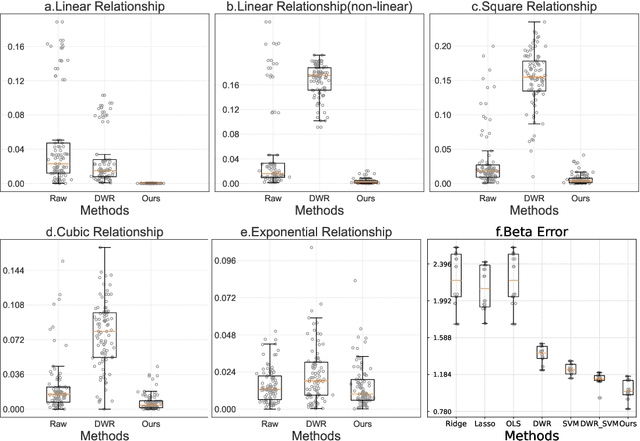
Causal inference and model interpretability research are gaining increasing attention, especially in the domains of healthcare and bioinformatics. Despite recent successes in this field, decorrelating features under nonlinear environments with human interpretable representations has not been adequately investigated. To address this issue, we introduce a novel method with a variable decorrelation regularizer to handle both linear and nonlinear confounding. Moreover, we employ association rules as new representations using association rule mining based on the original features to further proximate human decision patterns to increase model interpretability. Extensive experiments are conducted on four healthcare datasets (one synthetically generated and three real-world collections on different diseases). Quantitative results in comparison to baseline approaches on parameter estimation and causality computation indicate the model's superior performance. Furthermore, expert evaluation given by healthcare professionals validates the effectiveness and interpretability of the proposed model.