 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeimin Xiong
Rationale-Enhanced Language Models are Better Continual Relation Learners
Oct 10, 2023

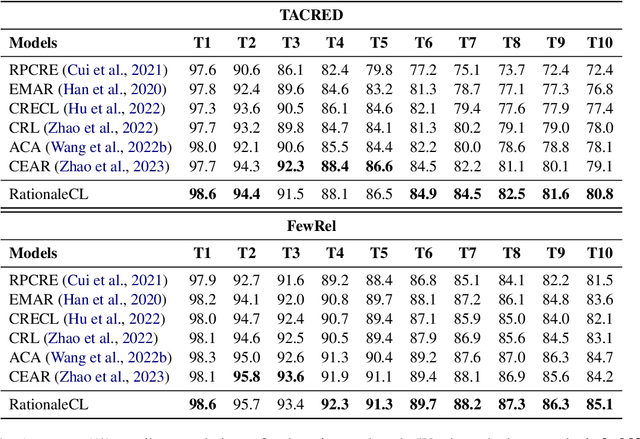
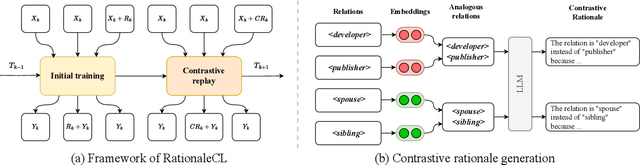
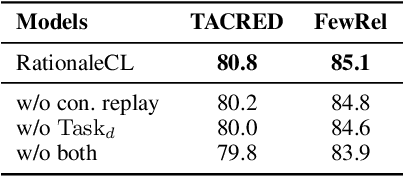
Continual relation extraction (CRE) aims to solve the problem of catastrophic forgetting when learning a sequence of newly emerging relations. Recent CRE studies have found that catastrophic forgetting arises from the model's lack of robustness against future analogous relations. To address the issue, we introduce rationale, i.e., the explanations of relation classification results generated by large language models (LLM), into CRE task. Specifically, we design the multi-task rationale tuning strategy to help the model learn current relations robustly. We also conduct contrastive rationale replay to further distinguish analogous relations. Experimental results on two standard benchmarks demonstrate that our method outperforms the state-of-the-art CRE models.
InfoCL: Alleviating Catastrophic Forgetting in Continual Text Classification from An Information Theoretic Perspective
Oct 10, 2023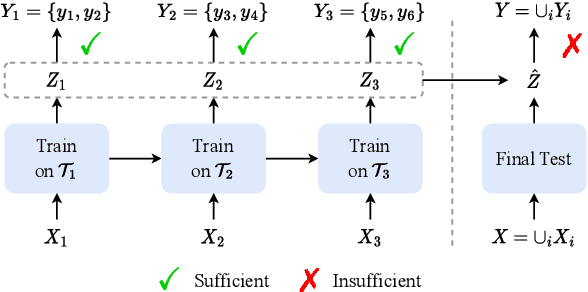
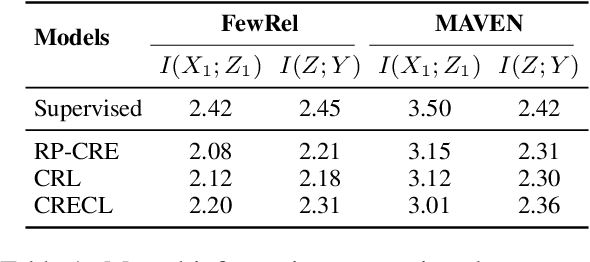
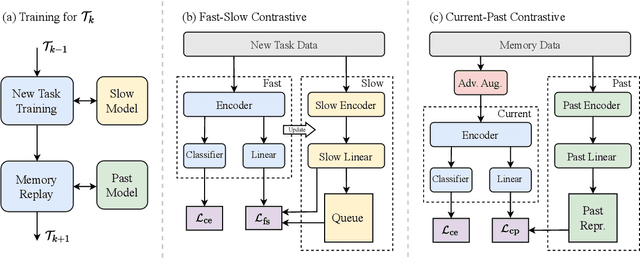
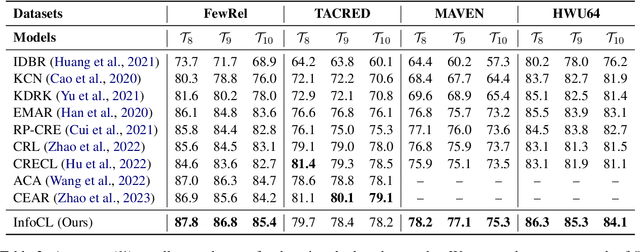
Continual learning (CL) aims to constantly learn new knowledge over time while avoiding catastrophic forgetting on old tasks. We focus on continual text classification under the class-incremental setting. Recent CL studies have identified the severe performance decrease on analogous classes as a key factor for catastrophic forgetting. In this paper, through an in-depth exploration of the representation learning process in CL, we discover that the compression effect of the information bottleneck leads to confusion on analogous classes. To enable the model learn more sufficient representations, we propose a novel replay-based continual text classification method, InfoCL. Our approach utilizes fast-slow and current-past contrastive learning to perform mutual information maximization and better recover the previously learned representations. In addition, InfoCL incorporates an adversarial memory augmentation strategy to alleviate the overfitting problem of replay. Experimental results demonstrate that InfoCL effectively mitigates forgetting and achieves state-of-the-art performance on three text classification tasks. The code is publicly available at https://github.com/Yifan-Song793/InfoCL.
The Program Testing Ability of Large Language Models for Code
Oct 09, 2023



Recent development of large language models (LLMs) for code like CodeX and CodeT5+ demonstrates tremendous promise in achieving code intelligence. Their ability of synthesizing code that completes a program for performing a pre-defined task has been intensively tested and verified on benchmark datasets including HumanEval and MBPP. Yet, evaluation of these LLMs from more perspectives (than just program synthesis) is also anticipated, considering their broad scope of applications in software engineering. In this paper, we explore the ability of LLMs for testing programs/code. By performing thorough analyses of recent LLMs for code in program testing, we show a series of intriguing properties of these models and demonstrate how program testing ability of LLMs can be improved. Following recent work which utilizes generated test cases to enhance program synthesis, we further leverage our findings in improving the quality of the synthesized programs and show +11.77% and +4.22% higher code pass rates on HumanEval+ comparing with the GPT-3.5-turbo baseline and the recent state-of-the-art, respectively.
RestGPT: Connecting Large Language Models with Real-World Applications via RESTful APIs
Jun 11, 2023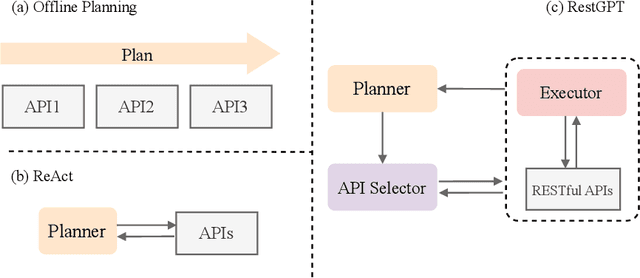
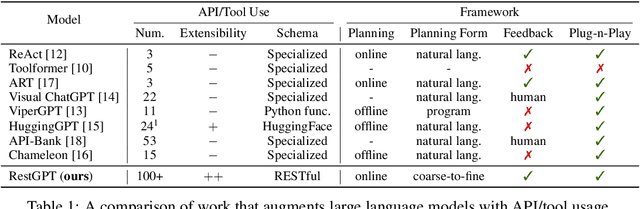
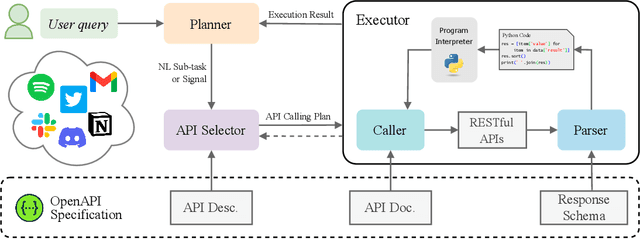
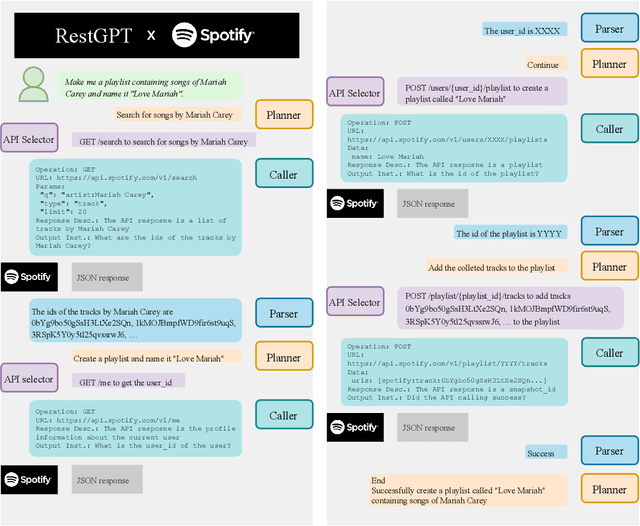
Tool-augmented large language models (LLMs) have achieved remarkable progress in tackling a broad range of queries. However, existing work are still in the experimental stage and has limitations in extensibility and robustness, especially facing the real-world applications. In this paper, we consider a more realistic scenario, connecting LLMs with RESTful APIs, which use the commonly adopted REST software architectural style for web service development. To address the practical challenges of planning and API usage, we introduce RestGPT, which leverages LLMs to solve user requests by connecting with RESTful APIs. Specifically, we propose a coarse-to-fine online planning mechanism to enhance the ability of planning and API selection. For the complex scenario of calling RESTful APIs, we also specially designed an API executor to formulate parameters and parse API responses. Experiments show that RestGPT is able to achieve impressive results in complex tasks and has strong robustness, which paves a new way towards AGI.
DocRED-FE: A Document-Level Fine-Grained Entity And Relation Extraction Dataset
Mar 21, 2023



Joint entity and relation extraction (JERE) is one of the most important tasks in information extraction. However, most existing works focus on sentence-level coarse-grained JERE, which have limitations in real-world scenarios. In this paper, we construct a large-scale document-level fine-grained JERE dataset DocRED-FE, which improves DocRED with Fine-Grained Entity Type. Specifically, we redesign a hierarchical entity type schema including 11 coarse-grained types and 119 fine-grained types, and then re-annotate DocRED manually according to this schema. Through comprehensive experiments we find that: (1) DocRED-FE is challenging to existing JERE models; (2) Our fine-grained entity types promote relation classification. We make DocRED-FE with instruction and the code for our baselines publicly available at https://github.com/PKU-TANGENT/DOCRED-FE.