 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiwei Tian
Inject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023
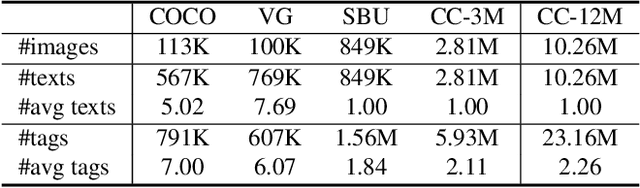
In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023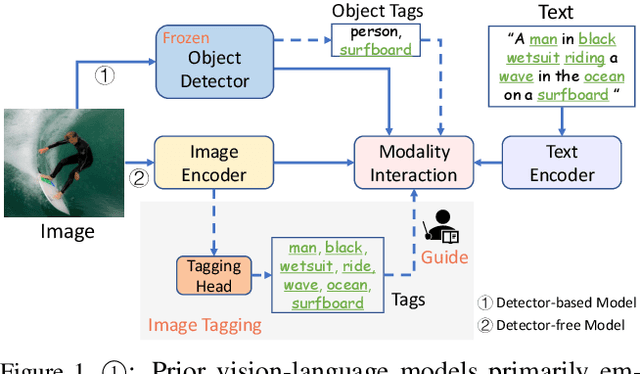
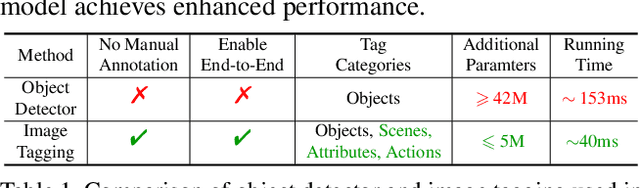

This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.
IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training
Jul 12, 2022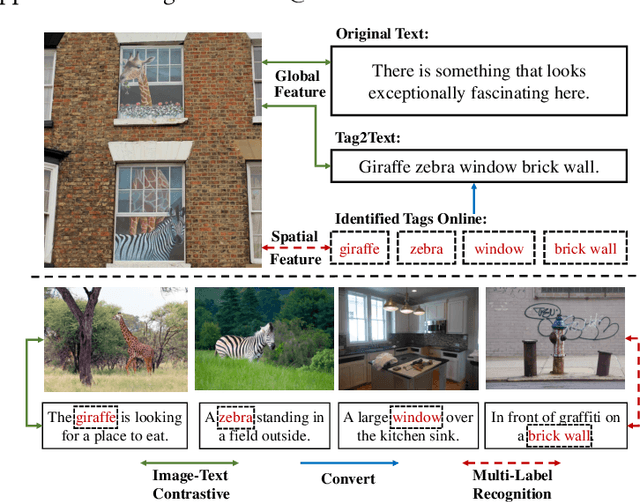
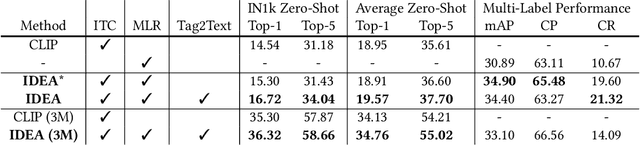
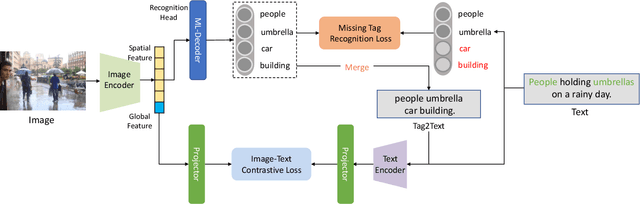
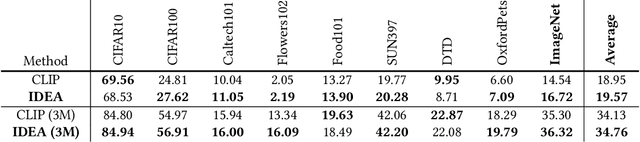
Vision-Language Pre-training (VLP) with large-scale image-text pairs has demonstrated superior performance in various fields. However, the image-text pairs co-occurrent on the Internet typically lack explicit alignment information, which is suboptimal for VLP. Existing methods proposed to adopt an off-the-shelf object detector to utilize additional image tag information. However, the object detector is time-consuming and can only identify the pre-defined object categories, limiting the model capacity. Inspired by the observation that the texts incorporate incomplete fine-grained image information, we introduce IDEA, which stands for increasing text diversity via online multi-label recognition for VLP. IDEA shows that multi-label learning with image tags extracted from the texts can be jointly optimized during VLP. Moreover, IDEA can identify valuable image tags online to provide more explicit textual supervision. Comprehensive experiments demonstrate that IDEA can significantly boost the performance on multiple downstream datasets with a small extra computational cost.