 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeizhi Zhu
Generative Adversarial Nets for Robust Scatter Estimation: A Proper Scoring Rule Perspective
Mar 05, 2019



Robust scatter estimation is a fundamental task in statistics. The recent discovery on the connection between robust estimation and generative adversarial nets (GANs) by Gao et al. (2018) suggests that it is possible to compute depth-like robust estimators using similar techniques that optimize GANs. In this paper, we introduce a general learning via classification framework based on the notion of proper scoring rules. This framework allows us to understand both matrix depth function and various GANs through the lens of variational approximations of $f$-divergences induced by proper scoring rules. We then propose a new class of robust scatter estimators in this framework by carefully constructing discriminators with appropriate neural network structures. These estimators are proved to achieve the minimax rate of scatter estimation under Huber's contamination model. Our numerical results demonstrate its good performance under various settings against competitors in the literature.
On Breiman's Dilemma in Neural Networks: Phase Transitions of Margin Dynamics
Oct 18, 2018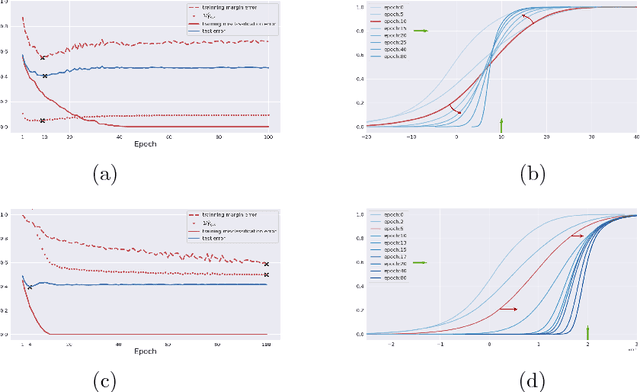
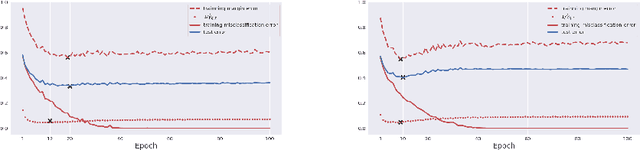
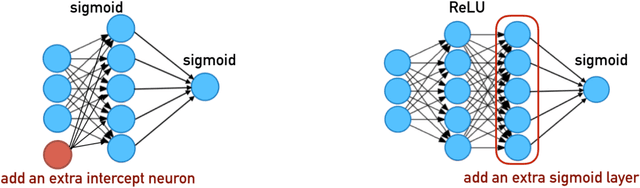
Margin enlargement over training data has been an important strategy since perceptrons in machine learning for the purpose of boosting the robustness of classifiers toward a good generalization ability. Yet Breiman shows a dilemma (Breiman, 1999) that a uniform improvement on margin distribution \emph{does not} necessarily reduces generalization errors. In this paper, we revisit Breiman's dilemma in deep neural networks with recently proposed spectrally normalized margins. A novel perspective is provided to explain Breiman's dilemma based on phase transitions in dynamics of normalized margin distributions, that reflects the trade-off between expressive power of models and complexity of data. When data complexity is comparable to the model expressiveness in the sense that both training and test data share similar phase transitions in normalized margin dynamics, two efficient ways are derived to predict the trend of generalization or test error via classic margin-based generalization bounds with restricted Rademacher complexities. On the other hand, over-expressive models that exhibit uniform improvements on training margins, as a distinct phase transition to test margin dynamics, may lose such a prediction power and fail to prevent the overfitting. Experiments are conducted to show the validity of the proposed method with some basic convolutional networks, AlexNet, VGG-16, and ResNet-18, on several datasets including Cifar10/100 and mini-ImageNet.
Robust Estimation and Generative Adversarial Nets
Oct 07, 2018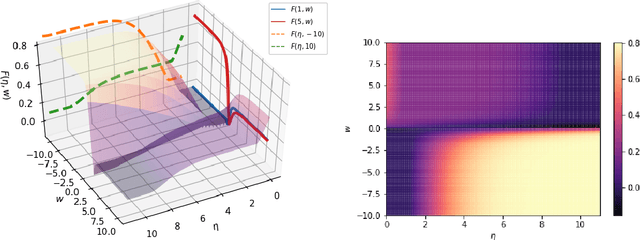
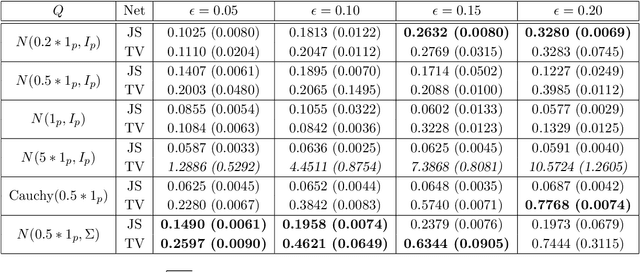
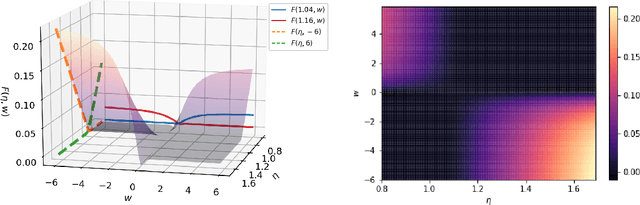
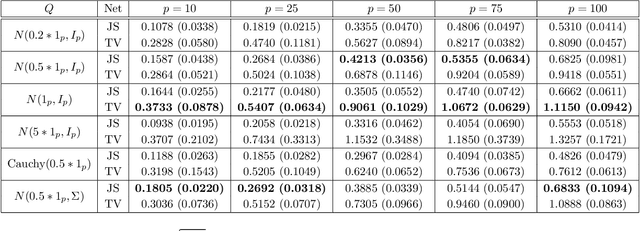
Robust estimation under Huber's $\epsilon$-contamination model has become an important topic in statistics and theoretical computer science. Rate-optimal procedures such as Tukey's median and other estimators based on statistical depth functions are impractical because of their computational intractability. In this paper, we establish an intriguing connection between f-GANs and various depth functions through the lens of f-Learning. Similar to the derivation of f-GAN, we show that these depth functions that lead to rate-optimal robust estimators can all be viewed as variational lower bounds of the total variation distance in the framework of f-Learning. This connection opens the door of computing robust estimators using tools developed for training GANs. In particular, we show that a JS-GAN that uses a neural network discriminator with at least one hidden layer is able to achieve the minimax rate of robust mean estimation under Huber's $\epsilon$-contamination model. Interestingly, the hidden layers for the neural net structure in the discriminator class is shown to be necessary for robust estimation.