 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenxuan Li
A Semantic Space is Worth 256 Language Descriptions: Make Stronger Segmentation Models with Descriptive Properties
Dec 21, 2023
This paper introduces ProLab, a novel approach using property-level label space for creating strong interpretable segmentation models. Instead of relying solely on category-specific annotations, ProLab uses descriptive properties grounded in common sense knowledge for supervising segmentation models. It is based on two core designs. First, we employ Large Language Models (LLMs) and carefully crafted prompts to generate descriptions of all involved categories that carry meaningful common sense knowledge and follow a structured format. Second, we introduce a description embedding model preserving semantic correlation across descriptions and then cluster them into a set of descriptive properties (e.g., 256) using K-Means. These properties are based on interpretable common sense knowledge consistent with theories of human recognition. We empirically show that our approach makes segmentation models perform stronger on five classic benchmarks (e.g., ADE20K, COCO-Stuff, Pascal Context, Cityscapes, and BDD). Our method also shows better scalability with extended training steps than category-level supervision. Our interpretable segmentation framework also emerges with the generalization ability to segment out-of-domain or unknown categories using only in-domain descriptive properties. Code is available at https://github.com/lambert-x/ProLab.
MIRA: Cracking Black-box Watermarking on Deep Neural Networks via Model Inversion-based Removal Attacks
Sep 07, 2023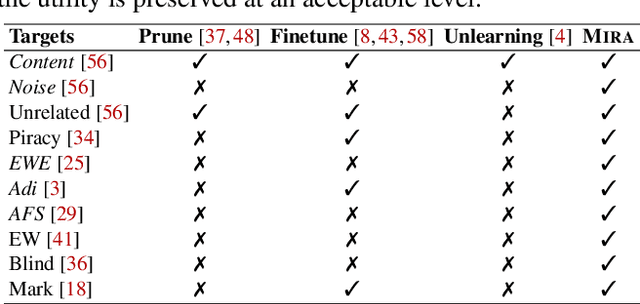
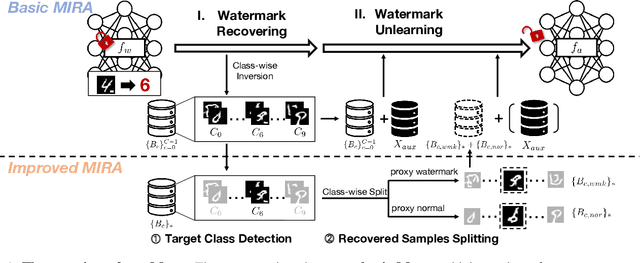


To protect the intellectual property of well-trained deep neural networks (DNNs), black-box DNN watermarks, which are embedded into the prediction behavior of DNN models on a set of specially-crafted samples, have gained increasing popularity in both academy and industry. Watermark robustness is usually implemented against attackers who steal the protected model and obfuscate its parameters for watermark removal. Recent studies empirically prove the robustness of most black-box watermarking schemes against known removal attempts. In this paper, we propose a novel Model Inversion-based Removal Attack (\textsc{Mira}), which is watermark-agnostic and effective against most of mainstream black-box DNN watermarking schemes. In general, our attack pipeline exploits the internals of the protected model to recover and unlearn the watermark message. We further design target class detection and recovered sample splitting algorithms to reduce the utility loss caused by \textsc{Mira} and achieve data-free watermark removal on half of the watermarking schemes. We conduct comprehensive evaluation of \textsc{Mira} against ten mainstream black-box watermarks on three benchmark datasets and DNN architectures. Compared with six baseline removal attacks, \textsc{Mira} achieves strong watermark removal effects on the covered watermarks, preserving at least $90\%$ of the stolen model utility, under more relaxed or even no assumptions on the dataset availability.
InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions
Apr 12, 2023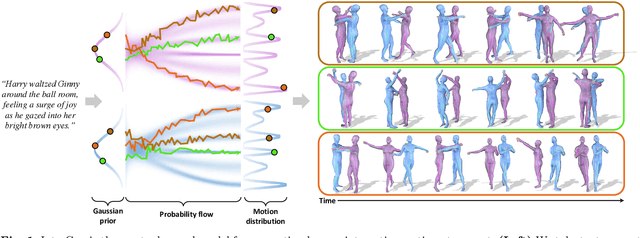
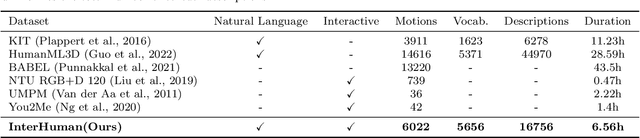

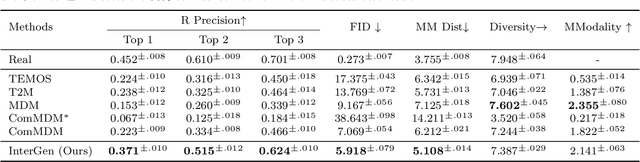
We have recently seen tremendous progress in diffusion advances for generating realistic human motions. Yet, they largely disregard the rich multi-human interactions. In this paper, we present InterGen, an effective diffusion-based approach that incorporates human-to-human interactions into the motion diffusion process, which enables layman users to customize high-quality two-person interaction motions, with only text guidance. We first contribute a multimodal dataset, named InterHuman. It consists of about 107M frames for diverse two-person interactions, with accurate skeletal motions and 16,756 natural language descriptions. For the algorithm side, we carefully tailor the motion diffusion model to our two-person interaction setting. To handle the symmetry of human identities during interactions, we propose two cooperative transformer-based denoisers that explicitly share weights, with a mutual attention mechanism to further connect the two denoising processes. Then, we propose a novel representation for motion input in our interaction diffusion model, which explicitly formulates the global relations between the two performers in the world frame. We further introduce two novel regularization terms to encode spatial relations, equipped with a corresponding damping scheme during the training of our interaction diffusion model. Extensive experiments validate the effectiveness and generalizability of InterGen. Notably, it can generate more diverse and compelling two-person motions than previous methods and enables various downstream applications for human interactions.