 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenze Hu
Guiding Instruction-based Image Editing via Multimodal Large Language Models
Sep 29, 2023
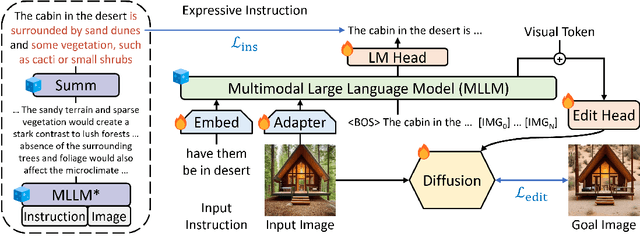
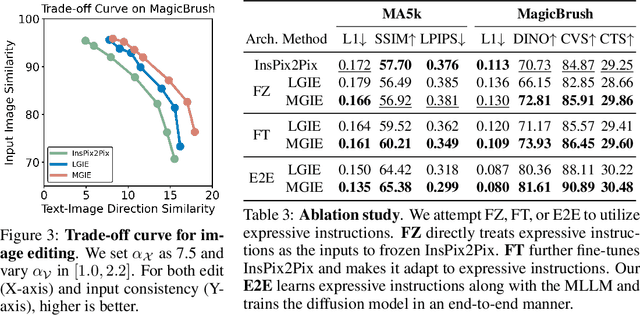
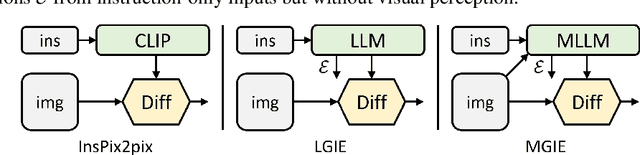
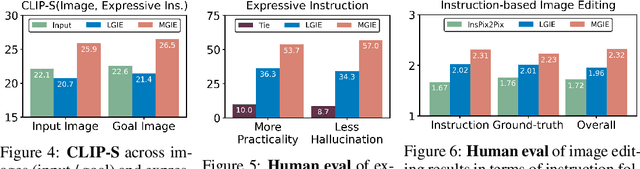
Instruction-based image editing improves the controllability and flexibility of image manipulation via natural commands without elaborate descriptions or regional masks. However, human instructions are sometimes too brief for current methods to capture and follow. Multimodal large language models (MLLMs) show promising capabilities in cross-modal understanding and visual-aware response generation via LMs. We investigate how MLLMs facilitate edit instructions and present MLLM-Guided Image Editing (MGIE). MGIE learns to derive expressive instructions and provides explicit guidance. The editing model jointly captures this visual imagination and performs manipulation through end-to-end training. We evaluate various aspects of Photoshop-style modification, global photo optimization, and local editing. Extensive experimental results demonstrate that expressive instructions are crucial to instruction-based image editing, and our MGIE can lead to a notable improvement in automatic metrics and human evaluation while maintaining competitive inference efficiency.
Million-scale Object Detection with Large Vision Model
Dec 19, 2022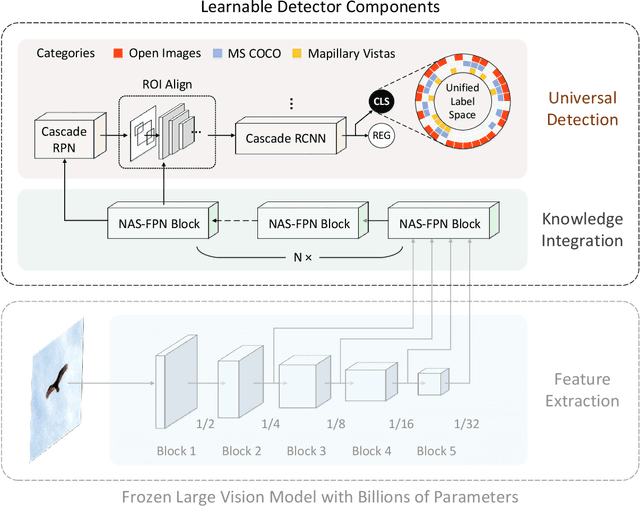
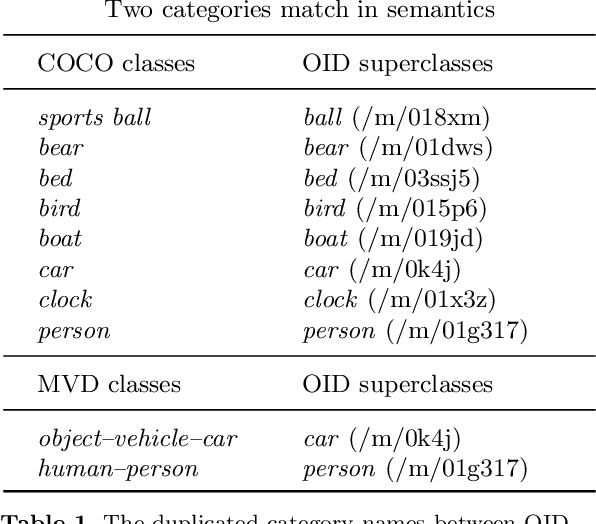
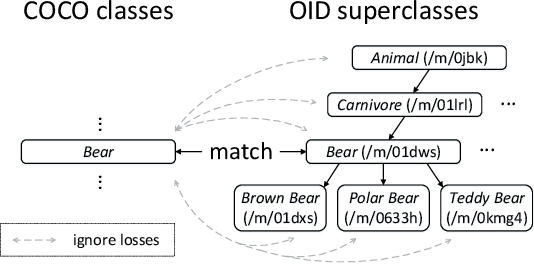
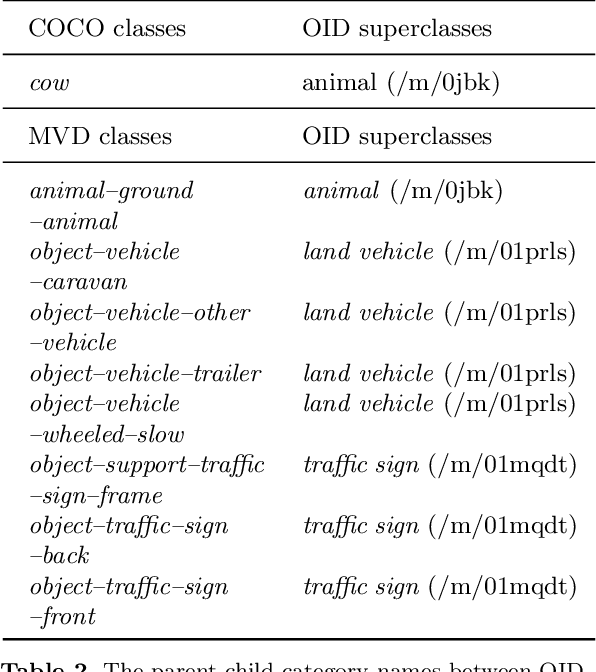
Over the past few years, developing a broad, universal, and general-purpose computer vision system has become a hot topic. A powerful universal system would be capable of solving diverse vision tasks simultaneously without being restricted to a specific problem or a specific data domain, which is of great importance in practical real-world computer vision applications. This study pushes the direction forward by concentrating on the million-scale multi-domain universal object detection problem. The problem is not trivial due to its complicated nature in terms of cross-dataset category label duplication, label conflicts, and the hierarchical taxonomy handling. Moreover, what is the resource-efficient way to utilize emerging large pre-trained vision models for million-scale cross-dataset object detection remains an open challenge. This paper tries to address these challenges by introducing our practices in label handling, hierarchy-aware loss design and resource-efficient model training with a pre-trained large model. Our method is ranked second in the object detection track of Robust Vision Challenge 2022 (RVC 2022). We hope our detailed study would serve as an alternative practice paradigm for similar problems in the community. The code is available at https://github.com/linfeng93/Large-UniDet.
NAR-Former: Neural Architecture Representation Learning towards Holistic Attributes Prediction
Nov 15, 2022
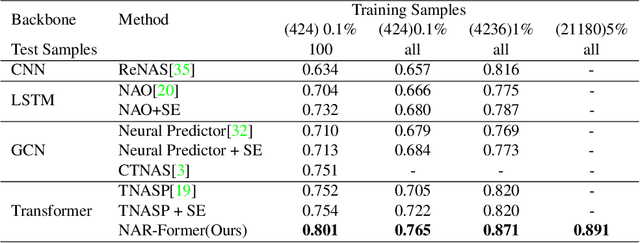
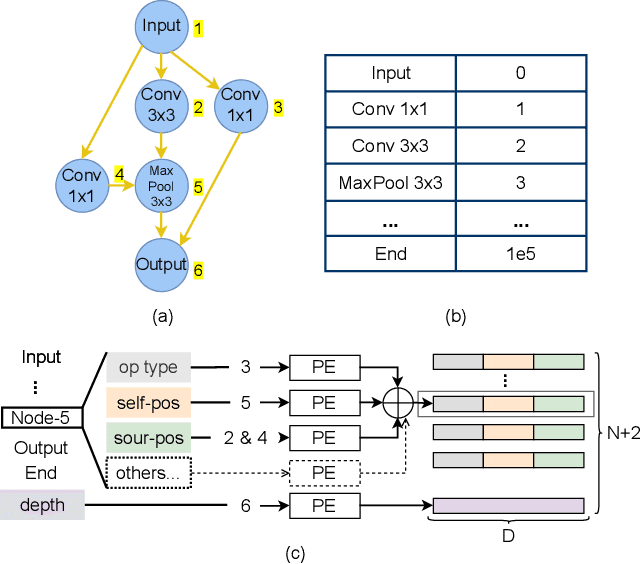
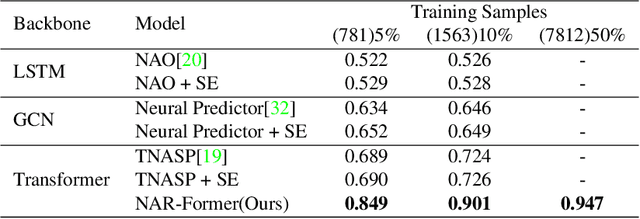
With the wide and deep adoption of deep learning models in real applications, there is an increasing need to model and learn the representations of the neural networks themselves. These models can be used to estimate attributes of different neural network architectures such as the accuracy and latency, without running the actual training or inference tasks. In this paper, we propose a neural architecture representation model that can be used to estimate these attributes holistically. Specifically, we first propose a simple and effective tokenizer to encode both the operation and topology information of a neural network into a single sequence. Then, we design a multi-stage fusion transformer to build a compact vector representation from the converted sequence. For efficient model training, we further propose an information flow consistency augmentation and correspondingly design an architecture consistency loss, which brings more benefits with less augmentation samples compared with previous random augmentation strategies. Experiment results on NAS-Bench-101, NAS-Bench-201, DARTS search space and NNLQP show that our proposed framework can be used to predict the aforementioned latency and accuracy attributes of both cell architectures and whole deep neural networks, and achieves promising performance.
CabViT: Cross Attention among Blocks for Vision Transformer
Nov 14, 2022



Since the vision transformer (ViT) has achieved impressive performance in image classification, an increasing number of researchers pay their attentions to designing more efficient vision transformer models. A general research line is reducing computational cost of self attention modules by adopting sparse attention or using local attention windows. In contrast, we propose to design high performance transformer based architectures by densifying the attention pattern. Specifically, we propose cross attention among blocks of ViT (CabViT), which uses tokens from previous blocks in the same stage as extra input to the multi-head attention of transformers. The proposed CabViT enhances the interactions of tokens across blocks with potentially different semantics, and encourages more information flows to the lower levels, which together improves model performance and model convergence with limited extra cost. Based on the proposed CabViT, we design a series of CabViT models which achieve the best trade-off between model size, computational cost and accuracy. For instance without the need of knowledge distillation to strength the training, CabViT achieves 83.0% top-1 accuracy on Imagenet with only 16.3 million parameters and about 3.9G FLOPs, saving almost half parameters and 13% computational cost while gaining 0.9% higher accuracy compared with ConvNext, use 52% of parameters but gaining 0.6% accuracy compared with distilled EfficientFormer
ParCNetV2: Oversized Kernel with Enhanced Attention
Nov 14, 2022



Transformers have achieved tremendous success in various computer vision tasks. By borrowing design concepts from transformers, many studies revolutionized CNNs and showed remarkable results. This paper falls in this line of studies. More specifically, we introduce a convolutional neural network architecture named ParCNetV2, which extends position-aware circular convolution (ParCNet) with oversized convolutions and strengthens attention through bifurcate gate units. The oversized convolution utilizes a kernel with $2\times$ the input size to model long-range dependencies through a global receptive field. Simultaneously, it achieves implicit positional encoding by removing the shift-invariant property from convolutional kernels, i.e., the effective kernels at different spatial locations are different when the kernel size is twice as large as the input size. The bifurcate gate unit implements an attention mechanism similar to self-attention in transformers. It splits the input into two branches, one serves as feature transformation while the other serves as attention weights. The attention is applied through element-wise multiplication of the two branches. Besides, we introduce a unified local-global convolution block to unify the design of the early and late stage convolutional blocks. Extensive experiments demonstrate that our method outperforms other pure convolutional neural networks as well as neural networks hybridizing CNNs and transformers.
Fast-ParC: Position Aware Global Kernel for ConvNets and ViTs
Oct 08, 2022



Transformer models have made tremendous progress in various fields in recent years. In the field of computer vision, vision transformers (ViTs) also become strong alternatives to convolutional neural networks (ConvNets), yet they have not been able to replace ConvNets since both have their own merits. For instance, ViTs are good at extracting global features with attention mechanisms while ConvNets are more efficient in modeling local relationships due to their strong inductive bias. A natural idea that arises is to combine the strengths of both ConvNets and ViTs to design new structures. In this paper, we propose a new basic neural network operator named position-aware circular convolution (ParC) and its accelerated version Fast-ParC. The ParC operator can capture global features by using a global kernel and circular convolution while keeping location sensitiveness by employing position embeddings. Our Fast-ParC further reduces the O(n2) time complexity of ParC to O(n log n) using Fast Fourier Transform. This acceleration makes it possible to use global convolution in the early stages of models with large feature maps, yet still maintains the overall computational cost comparable with using 3x3 or 7x7 kernels. The proposed operation can be used in a plug-and-play manner to 1) convert ViTs to pure-ConvNet architecture to enjoy wider hardware support and achieve higher inference speed; 2) replacing traditional convolutions in the deep stage of ConvNets to improve accuracy by enlarging the effective receptive field. Experiment results show that our ParC op can effectively enlarge the receptive field of traditional ConvNets, and adopting the proposed op benefits both ViTs and ConvNet models on all three popular vision tasks, image classification, object
ALBench: A Framework for Evaluating Active Learning in Object Detection
Aug 10, 2022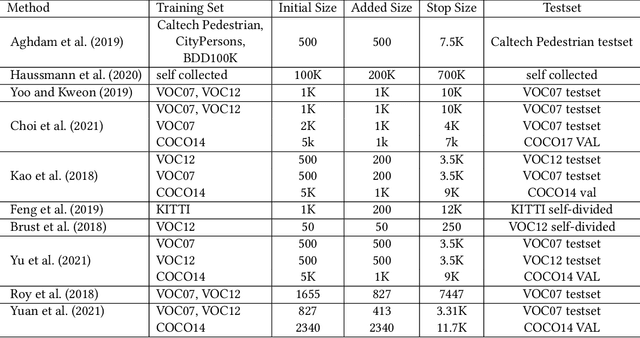

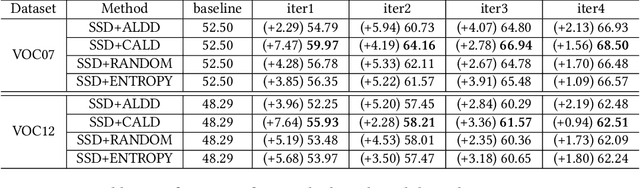
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.
Implementation of an Automated Learning System for Non-experts
Mar 26, 2022



Automated machine learning systems for non-experts could be critical for industries to adopt artificial intelligence to their own applications. This paper detailed the engineering system implementation of an automated machine learning system called YMIR, which completely relies on graphical interface to interact with users. After importing training/validation data into the system, a user without AI knowledge can label the data, train models, perform data mining and evaluation by simply clicking buttons. The paper described: 1) Open implementation of model training and inference through docker containers. 2) Implementation of task and resource management. 3) Integration of Labeling software. 4) Implementation of HCI (Human Computer Interaction) with a rebuilt collaborative development paradigm. We also provide subsequent case study on training models with the system. We hope this paper can facilitate the prosperity of our automated machine learning community from industry application perspective. The code of the system has already been released to GitHub (https://github.com/industryessentials/ymir).
EdgeFormer: Improving Light-weight ConvNets by Learning from Vision Transformers
Mar 15, 2022



Recently, vision transformers started to show impressive results which outperform large convolution based models significantly. However, in the area of small models for mobile or resource constrained devices, ConvNet still has its own advantages in both performance and model complexity. We propose EdgeFormer, a pure ConvNet based backbone model that further strengthens these advantages by fusing the merits of vision transformers into ConvNets. Specifically, we propose global circular convolution (GCC) with position embeddings, a light-weight convolution op which boasts a global receptive field while producing location sensitive features as in local convolutions. We combine the GCCs and squeeze-exictation ops to form a meta-former like model block, which further has the attention mechanism like transformers. The aforementioned block can be used in plug-and-play manner to replace relevant blocks in ConvNets or transformers. Experiment results show that the proposed EdgeFormer achieves better performance than popular light-weight ConvNets and vision transformer based models in common vision tasks and datasets, while having fewer parameters and faster inference speed. For classification on ImageNet-1k, EdgeFormer achieves 78.6% top-1 accuracy with about 5.0 million parameters, saving 11% parameters and 13% computational cost but gaining 0.2% higher accuracy and 23% faster inference speed (on ARM based Rockchip RK3288) compared with MobileViT, and uses only 0.5 times parameters but gaining 2.7% accuracy compared with DeIT. On MS-COCO object detection and PASCAL VOC segmentation tasks, EdgeFormer also shows better performance. Code is available at https://github.com/hkzhang91/EdgeFormer
YMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 27, 2021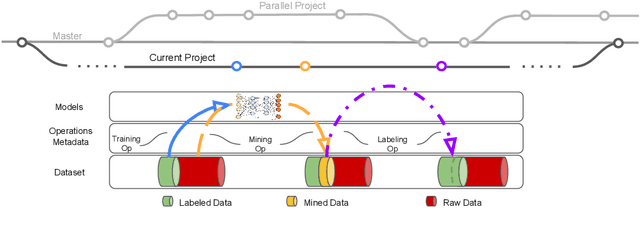
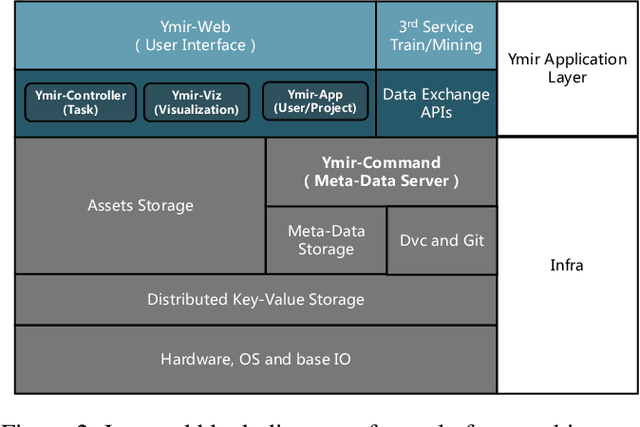
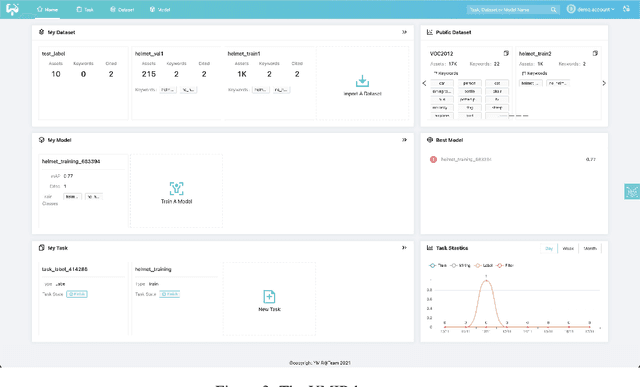
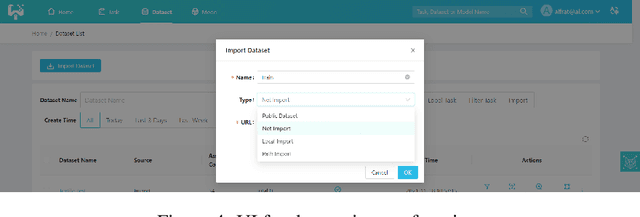
This paper introduces an open source platform to support the rapid development of computer vision applications at scale. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iterations of multiple task specific datasets in parallel. This platform abstracts the development process into core states and operations, and integrates third party tools via open APIs as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development histories, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand for different real world computer vision applications.