 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWilliam Woof
A Framework for End-to-End Learning on Semantic Tree-Structured Data
Feb 13, 2020
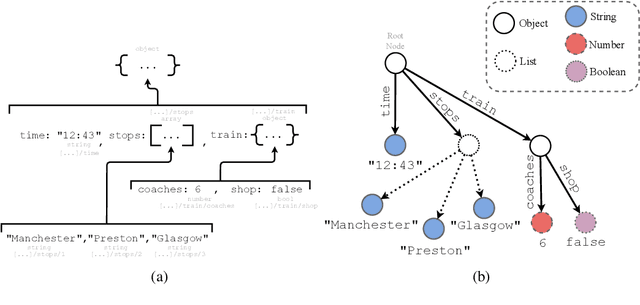
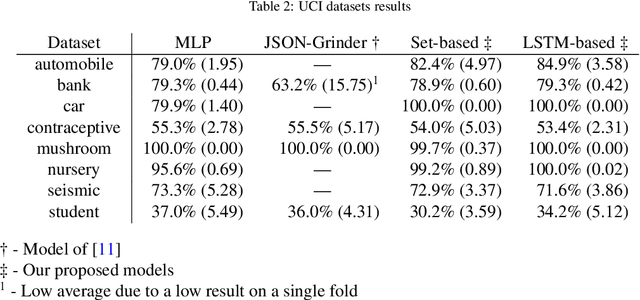
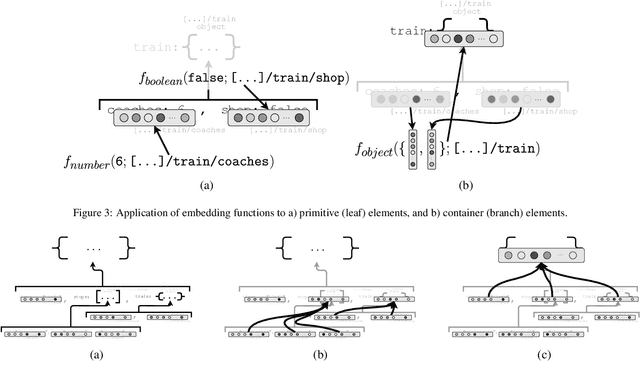
While learning models are typically studied for inputs in the form of a fixed dimensional feature vector, real world data is rarely found in this form. In order to meet the basic requirement of traditional learning models, structural data generally have to be converted into fix-length vectors in a handcrafted manner, which is tedious and may even incur information loss. A common form of structured data is what we term "semantic tree-structures", corresponding to data where rich semantic information is encoded in a compositional manner, such as those expressed in JavaScript Object Notation (JSON) and eXtensible Markup Language (XML). For tree-structured data, several learning models have been studied to allow for working directly on raw tree-structure data, However such learning models are limited to either a specific tree-topology or a specific tree-structured data format, e.g., synthetic parse trees. In this paper, we propose a novel framework for end-to-end learning on generic semantic tree-structured data of arbitrary topology and heterogeneous data types, such as data expressed in JSON, XML and so on. Motivated by the works in recursive and recurrent neural networks, we develop exemplar neural implementations of our framework for the JSON format. We evaluate our approach on several UCI benchmark datasets, including ablation and data-efficiency studies, and on a toy reinforcement learning task. Experimental results suggest that our framework yields comparable performance to use of standard models with dedicated feature-vectors in general, and even exceeds baseline performance in cases where compositional nature of the data is particularly important. The source code for a JSON-based implementation of our framework along with experiments can be downloaded at https://github.com/EndingCredits/json2vec.
Learning to Play General Video-Games via an Object Embedding Network
May 28, 2018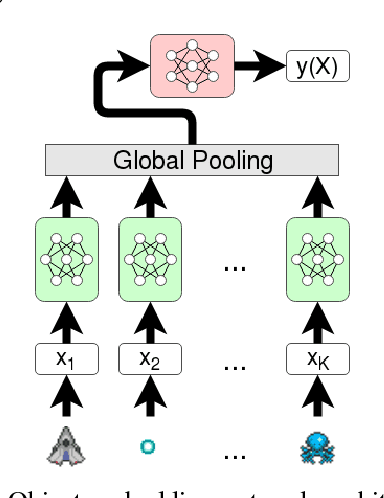
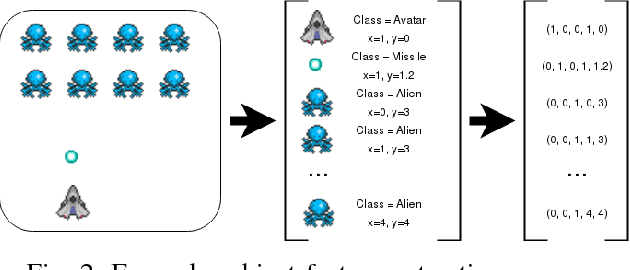
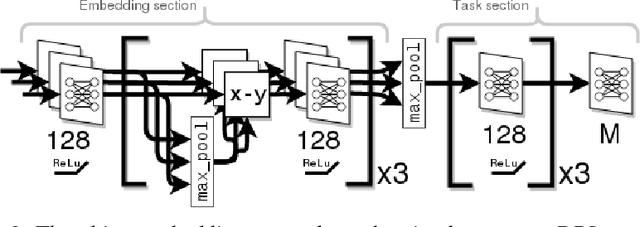

Deep reinforcement learning (DRL) has proven to be an effective tool for creating general video-game AI. However most current DRL video-game agents learn end-to-end from the video-output of the game, which is superfluous for many applications and creates a number of additional problems. More importantly, directly working on pixel-based raw video data is substantially distinct from what a human player does.In this paper, we present a novel method which enables DRL agents to learn directly from object information. This is obtained via use of an object embedding network (OEN) that compresses a set of object feature vectors of different lengths into a single fixed-length unified feature vector representing the current game-state and fulfills the DRL simultaneously. We evaluate our OEN-based DRL agent by comparing to several state-of-the-art approaches on a selection of games from the GVG-AI Competition. Experimental results suggest that our object-based DRL agent yields performance comparable to that of those approaches used in our comparative study.