 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiang Xu
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
May 08, 2024
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
Calib3D: Calibrating Model Preferences for Reliable 3D Scene Understanding
Mar 25, 2024Safety-critical 3D scene understanding tasks necessitate not only accurate but also confident predictions from 3D perception models. This study introduces Calib3D, a pioneering effort to benchmark and scrutinize the reliability of 3D scene understanding models from an uncertainty estimation viewpoint. We comprehensively evaluate 28 state-of-the-art models across 10 diverse 3D datasets, uncovering insightful phenomena that cope with both the aleatoric and epistemic uncertainties in 3D scene understanding. We discover that despite achieving impressive levels of accuracy, existing models frequently fail to provide reliable uncertainty estimates -- a pitfall that critically undermines their applicability in safety-sensitive contexts. Through extensive analysis of key factors such as network capacity, LiDAR representations, rasterization resolutions, and 3D data augmentation techniques, we correlate these aspects directly with the model calibration efficacy. Furthermore, we introduce DeptS, a novel depth-aware scaling approach aimed at enhancing 3D model calibration. Extensive experiments across a wide range of configurations validate the superiority of our method. We hope this work could serve as a cornerstone for fostering reliable 3D scene understanding. Code and benchmark toolkits are publicly available.
BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry
Jan 28, 2024This paper presents BrepGen, a diffusion-based generative approach that directly outputs a Boundary representation (B-rep) Computer-Aided Design (CAD) model. BrepGen represents a B-rep model as a novel structured latent geometry in a hierarchical tree. With the root node representing a whole CAD solid, each element of a B-rep model (i.e., a face, an edge, or a vertex) progressively turns into a child-node from top to bottom. B-rep geometry information goes into the nodes as the global bounding box of each primitive along with a latent code describing the local geometric shape. The B-rep topology information is implicitly represented by node duplication. When two faces share an edge, the edge curve will appear twice in the tree, and a T-junction vertex with three incident edges appears six times in the tree with identical node features. Starting from the root and progressing to the leaf, BrepGen employs Transformer-based diffusion models to sequentially denoise node features while duplicated nodes are detected and merged, recovering the B-Rep topology information. Extensive experiments show that BrepGen sets a new milestone in CAD B-rep generation, surpassing existing methods on various benchmarks. Results on our newly collected furniture dataset further showcase its exceptional capability in generating complicated geometry. While previous methods were limited to generating simple prismatic shapes, BrepGen incorporates free-form and doubly-curved surfaces for the first time. Additional applications of BrepGen include CAD autocomplete and design interpolation. The code, pretrained models, and dataset will be released.
FRNet: Frustum-Range Networks for Scalable LiDAR Segmentation
Dec 07, 2023LiDAR segmentation is crucial for autonomous driving systems. The recent range-view approaches are promising for real-time processing. However, they suffer inevitably from corrupted contextual information and rely heavily on post-processing techniques for prediction refinement. In this work, we propose a simple yet powerful FRNet that restores the contextual information of the range image pixels with corresponding frustum LiDAR points. Firstly, a frustum feature encoder module is used to extract per-point features within the frustum region, which preserves scene consistency and is crucial for point-level predictions. Next, a frustum-point fusion module is introduced to update per-point features hierarchically, which enables each point to extract more surrounding information via the frustum features. Finally, a head fusion module is used to fuse features at different levels for final semantic prediction. Extensive experiments on four popular LiDAR segmentation benchmarks under various task setups demonstrate our superiority. FRNet achieves competitive performance while maintaining high efficiency. The code is publicly available.
APGL4SR: A Generic Framework with Adaptive and Personalized Global Collaborative Information in Sequential Recommendation
Nov 06, 2023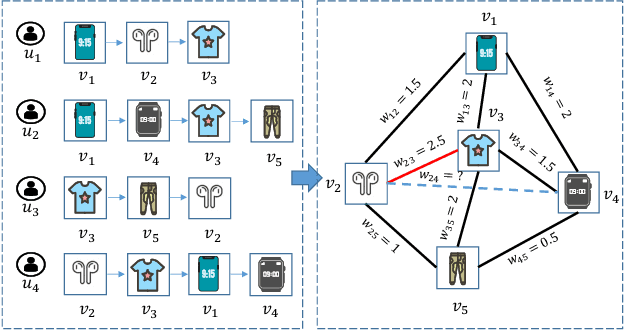
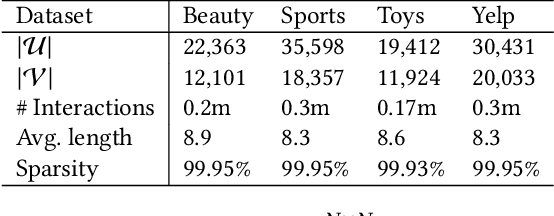
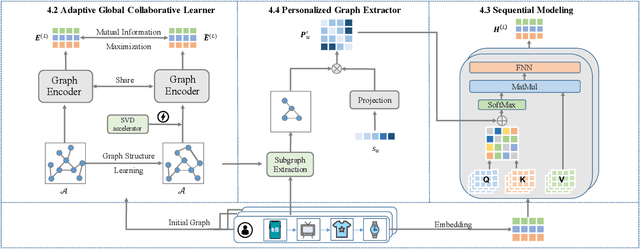
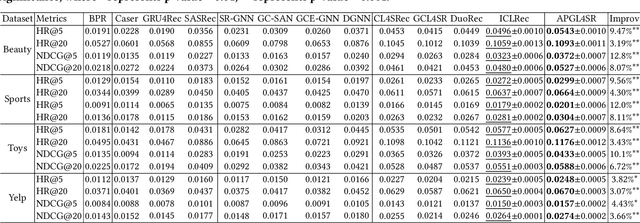
The sequential recommendation system has been widely studied for its promising effectiveness in capturing dynamic preferences buried in users' sequential behaviors. Despite the considerable achievements, existing methods usually focus on intra-sequence modeling while overlooking exploiting global collaborative information by inter-sequence modeling, resulting in inferior recommendation performance. Therefore, previous works attempt to tackle this problem with a global collaborative item graph constructed by pre-defined rules. However, these methods neglect two crucial properties when capturing global collaborative information, i.e., adaptiveness and personalization, yielding sub-optimal user representations. To this end, we propose a graph-driven framework, named Adaptive and Personalized Graph Learning for Sequential Recommendation (APGL4SR), that incorporates adaptive and personalized global collaborative information into sequential recommendation systems. Specifically, we first learn an adaptive global graph among all items and capture global collaborative information with it in a self-supervised fashion, whose computational burden can be further alleviated by the proposed SVD-based accelerator. Furthermore, based on the graph, we propose to extract and utilize personalized item correlations in the form of relative positional encoding, which is a highly compatible manner of personalizing the utilization of global collaborative information. Finally, the entire framework is optimized in a multi-task learning paradigm, thus each part of APGL4SR can be mutually reinforced. As a generic framework, APGL4SR can outperform other baselines with significant margins. The code is available at https://github.com/Graph-Team/APGL4SR.
FHT-Map: Feature-based Hierarchical Topological Map for Relocalization and Path Planning
Oct 21, 2023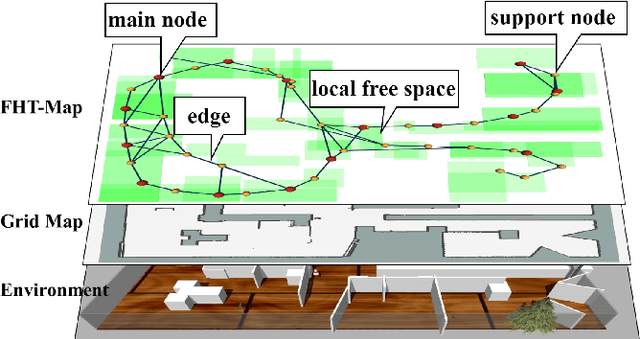

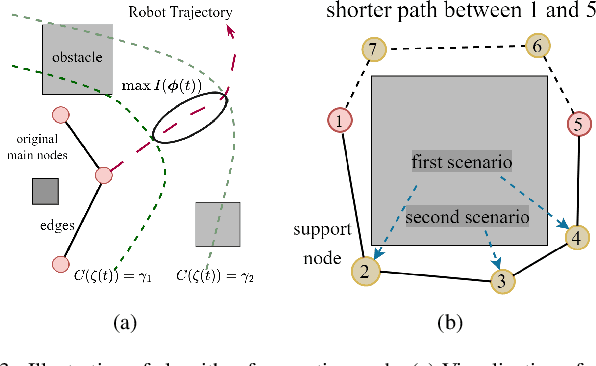
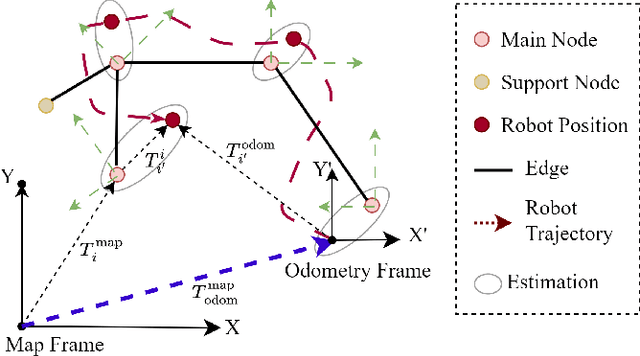
Topological maps are favorable for their small storage compared to geometric map. However, they are limited in relocalization and path planning capabilities. To solve this problem, a feature-based hierarchical topological map (FHT-Map) is proposed along with a real-time map construction algorithm for robot exploration. Specifically, the FHT-Map utilizes both RGB cameras and LiDAR information and consists of two types of nodes: main node and support node. Main nodes will store visual information compressed by convolutional neural network and local laser scan data to enhance subsequent relocalization capability. Support nodes retain a minimal amount of data to ensure storage efficiency while facilitating path planning. After map construction with robot exploration, the FHT-Map can be used by other robots for relocalization and path planning. Experiments are conducted in Gazebo simulator, and the results demonstrate that the proposed FHT-Map can effectively improve relocalization and path planning capability compared with other topological maps. Moreover, experiments on hierarchical architecture are implemented to show the necessity of two types of nodes.
Hierarchical Neural Coding for Controllable CAD Model Generation
Jun 30, 2023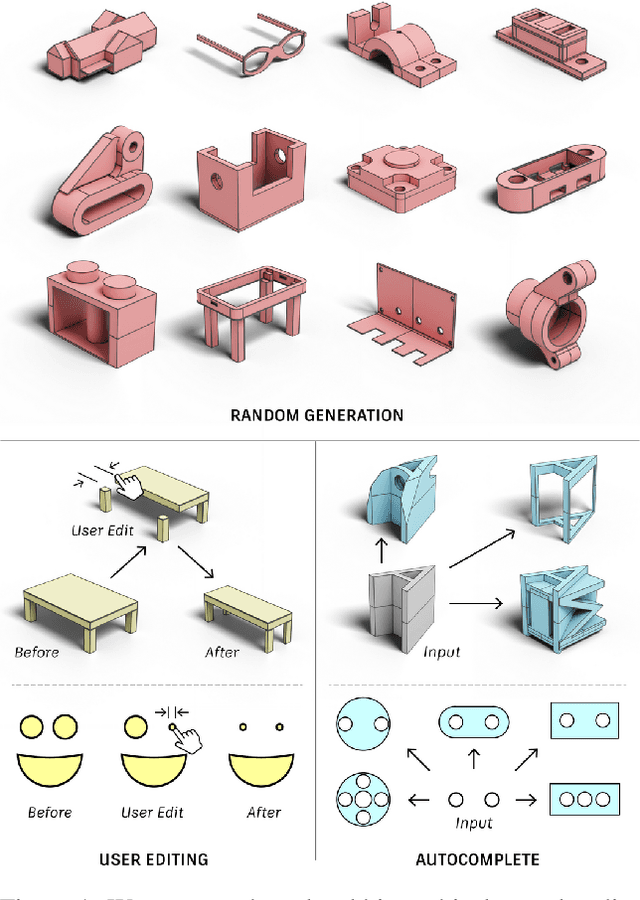

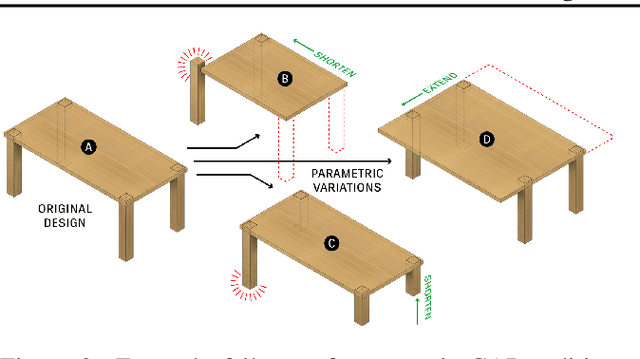

This paper presents a novel generative model for Computer Aided Design (CAD) that 1) represents high-level design concepts of a CAD model as a three-level hierarchical tree of neural codes, from global part arrangement down to local curve geometry; and 2) controls the generation or completion of CAD models by specifying the target design using a code tree. Concretely, a novel variant of a vector quantized VAE with "masked skip connection" extracts design variations as neural codebooks at three levels. Two-stage cascaded auto-regressive transformers learn to generate code trees from incomplete CAD models and then complete CAD models following the intended design. Extensive experiments demonstrate superior performance on conventional tasks such as random generation while enabling novel interaction capabilities on conditional generation tasks. The code is available at https://github.com/samxuxiang/hnc-cad.
M3PT: A Multi-Modal Model for POI Tagging
Jun 16, 2023

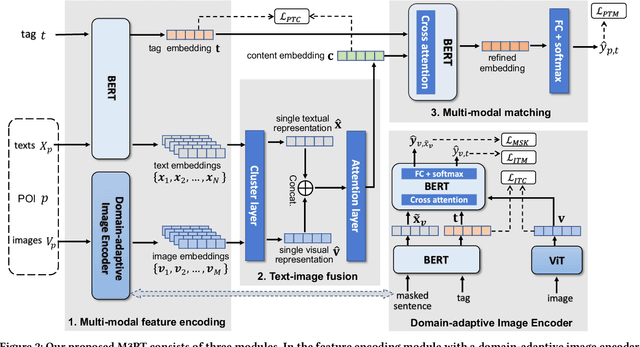

POI tagging aims to annotate a point of interest (POI) with some informative tags, which facilitates many services related to POIs, including search, recommendation, and so on. Most of the existing solutions neglect the significance of POI images and seldom fuse the textual and visual features of POIs, resulting in suboptimal tagging performance. In this paper, we propose a novel Multi-Modal Model for POI Tagging, namely M3PT, which achieves enhanced POI tagging through fusing the target POI's textual and visual features, and the precise matching between the multi-modal representations. Specifically, we first devise a domain-adaptive image encoder (DIE) to obtain the image embeddings aligned to their gold tags' semantics. Then, in M3PT's text-image fusion module (TIF), the textual and visual representations are fully fused into the POIs' content embeddings for the subsequent matching. In addition, we adopt a contrastive learning strategy to further bridge the gap between the representations of different modalities. To evaluate the tagging models' performance, we have constructed two high-quality POI tagging datasets from the real-world business scenario of Ali Fliggy. Upon the datasets, we conducted the extensive experiments to demonstrate our model's advantage over the baselines of uni-modality and multi-modality, and verify the effectiveness of important components in M3PT, including DIE, TIF and the contrastive learning strategy.
SkexGen: Autoregressive Generation of CAD Construction Sequences with Disentangled Codebooks
Jul 11, 2022
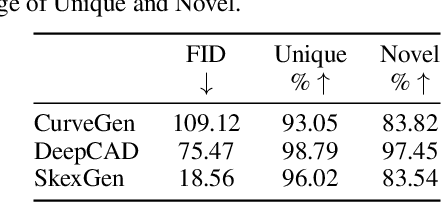
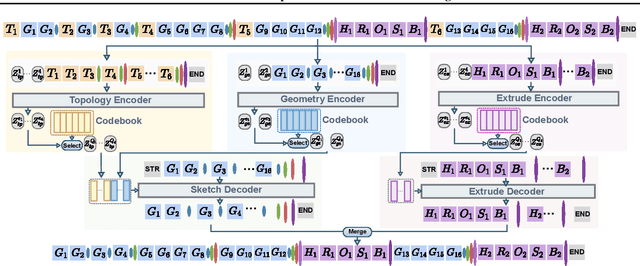
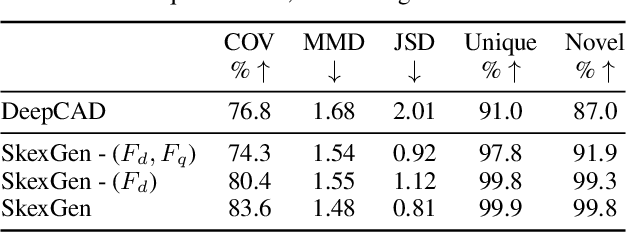
We present SkexGen, a novel autoregressive generative model for computer-aided design (CAD) construction sequences containing sketch-and-extrude modeling operations. Our model utilizes distinct Transformer architectures to encode topological, geometric, and extrusion variations of construction sequences into disentangled codebooks. Autoregressive Transformer decoders generate CAD construction sequences sharing certain properties specified by the codebook vectors. Extensive experiments demonstrate that our disentangled codebook representation generates diverse and high-quality CAD models, enhances user control, and enables efficient exploration of the design space. The code is available at https://samxuxiang.github.io/skexgen.
D3D-HOI: Dynamic 3D Human-Object Interactions from Videos
Aug 19, 2021

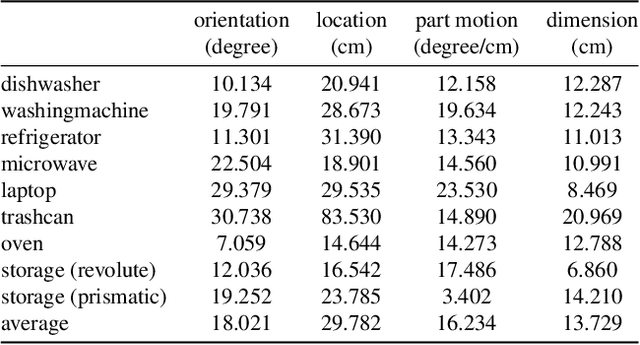

We introduce D3D-HOI: a dataset of monocular videos with ground truth annotations of 3D object pose, shape and part motion during human-object interactions. Our dataset consists of several common articulated objects captured from diverse real-world scenes and camera viewpoints. Each manipulated object (e.g., microwave oven) is represented with a matching 3D parametric model. This data allows us to evaluate the reconstruction quality of articulated objects and establish a benchmark for this challenging task. In particular, we leverage the estimated 3D human pose for more accurate inference of the object spatial layout and dynamics. We evaluate this approach on our dataset, demonstrating that human-object relations can significantly reduce the ambiguity of articulated object reconstructions from challenging real-world videos. Code and dataset are available at https://github.com/facebookresearch/d3d-hoi.