 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaochen Bo
Graph Neural Networks for Double-Strand DNA Breaks Prediction
Jan 04, 2022
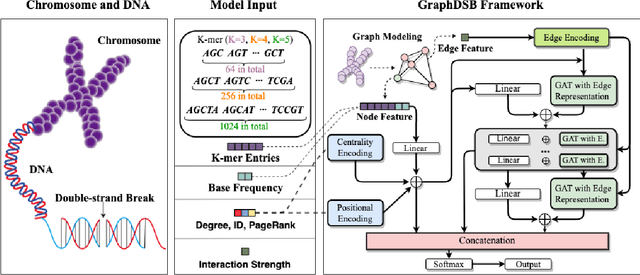
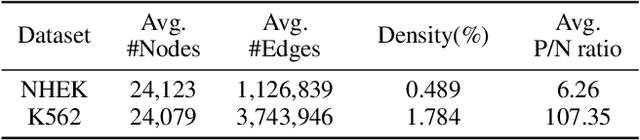

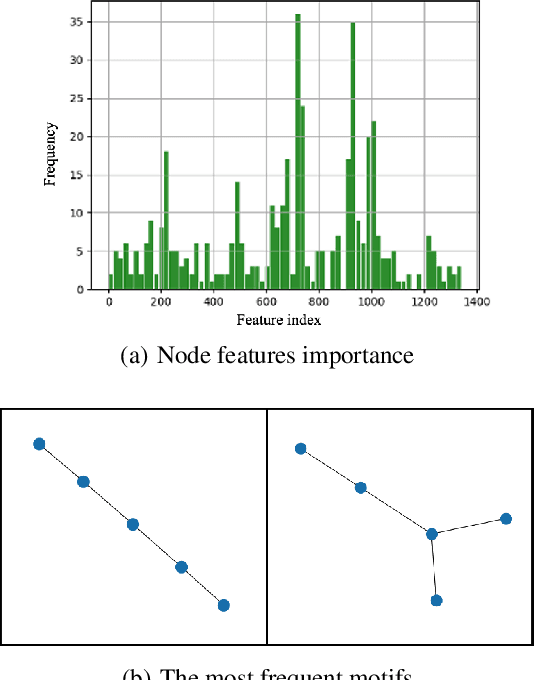
Double-strand DNA breaks (DSBs) are a form of DNA damage that can cause abnormal chromosomal rearrangements. Recent technologies based on high-throughput experiments have obvious high costs and technical challenges.Therefore, we design a graph neural network based method to predict DSBs (GraphDSB), using DNA sequence features and chromosome structure information. In order to improve the expression ability of the model, we introduce Jumping Knowledge architecture and several effective structural encoding methods. The contribution of structural information to the prediction of DSBs is verified by the experiments on datasets from normal human epidermal keratinocytes (NHEK) and chronic myeloid leukemia cell line (K562), and the ablation studies further demonstrate the effectiveness of the designed components in the proposed GraphDSB framework. Finally, we use GNNExplainer to analyze the contribution of node features and topology to DSBs prediction, and proved the high contribution of 5-mer DNA sequence features and two chromatin interaction modes.
Domain-Adversarial Multi-Task Framework for Novel Therapeutic Property Prediction of Compounds
Sep 28, 2018

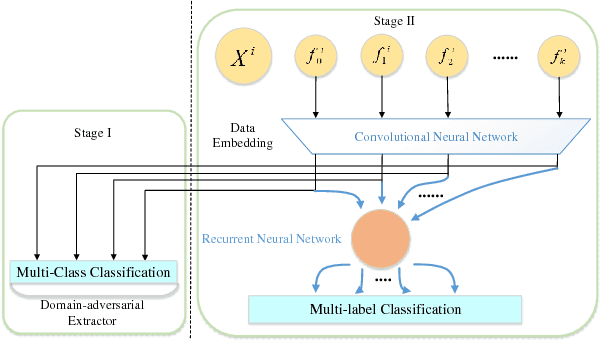
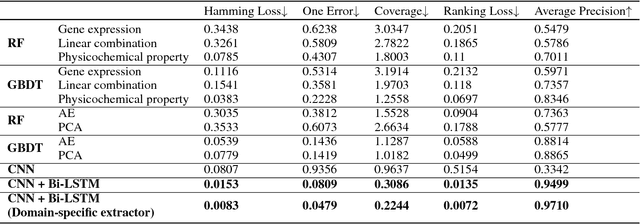
With the rapid development of high-throughput technologies, parallel acquisition of large-scale drug-informatics data provides huge opportunities to improve pharmaceutical research and development. One significant application is the purpose prediction of small molecule compounds, aiming to specify therapeutic properties of extensive purpose-unknown compounds and to repurpose novel therapeutic properties of FDA-approved drugs. Such problem is very challenging since compound attributes contain heterogeneous data with various feature patterns such as drug fingerprint, drug physicochemical property, drug perturbation gene expression. Moreover, there is complex nonlinear dependency among heterogeneous data. In this paper, we propose a novel domain-adversarial multi-task framework for integrating shared knowledge from multiple domains. The framework utilizes the adversarial strategy to effectively learn target representations and models their nonlinear dependency. Experiments on two real-world datasets illustrate that the performance of our approach obtains an obvious improvement over competitive baselines. The novel therapeutic properties of purpose-unknown compounds we predicted are mostly reported or brought to the clinics. Furthermore, our framework can integrate various attributes beyond the three domains examined here and can be applied in the industry for screening the purpose of huge amounts of as yet unidentified compounds. Source codes of this paper are available on Github.