 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaofei Xie
CaBaFL: Asynchronous Federated Learning via Hierarchical Cache and Feature Balance
Apr 19, 2024
Federated Learning (FL) as a promising distributed machine learning paradigm has been widely adopted in Artificial Intelligence of Things (AIoT) applications. However, the efficiency and inference capability of FL is seriously limited due to the presence of stragglers and data imbalance across massive AIoT devices, respectively. To address the above challenges, we present a novel asynchronous FL approach named CaBaFL, which includes a hierarchical Cache-based aggregation mechanism and a feature Balance-guided device selection strategy. CaBaFL maintains multiple intermediate models simultaneously for local training. The hierarchical cache-based aggregation mechanism enables each intermediate model to be trained on multiple devices to align the training time and mitigate the straggler issue. In specific, each intermediate model is stored in a low-level cache for local training and when it is trained by sufficient local devices, it will be stored in a high-level cache for aggregation. To address the problem of imbalanced data, the feature balance-guided device selection strategy in CaBaFL adopts the activation distribution as a metric, which enables each intermediate model to be trained across devices with totally balanced data distributions before aggregation. Experimental results show that compared with the state-of-the-art FL methods, CaBaFL achieves up to 9.26X training acceleration and 19.71\% accuracy improvements.
KoReA-SFL: Knowledge Replay-based Split Federated Learning Against Catastrophic Forgetting
Apr 19, 2024Although Split Federated Learning (SFL) is good at enabling knowledge sharing among resource-constrained clients, it suffers from the problem of low training accuracy due to the neglect of data heterogeneity and catastrophic forgetting. To address this issue, we propose a novel SFL approach named KoReA-SFL, which adopts a multi-model aggregation mechanism to alleviate gradient divergence caused by heterogeneous data and a knowledge replay strategy to deal with catastrophic forgetting. Specifically, in KoReA-SFL cloud servers (i.e., fed server and main server) maintain multiple branch model portions rather than a global portion for local training and an aggregated master-model portion for knowledge sharing among branch portions. To avoid catastrophic forgetting, the main server of KoReA-SFL selects multiple assistant devices for knowledge replay according to the training data distribution of each server-side branch-model portion. Experimental results obtained from non-IID and IID scenarios demonstrate that KoReA-SFL significantly outperforms conventional SFL methods (by up to 23.25\% test accuracy improvement).
Evaluating Decision Optimality of Autonomous Driving via Metamorphic Testing
Feb 28, 2024Autonomous Driving System (ADS) testing is crucial in ADS development, with the current primary focus being on safety. However, the evaluation of non-safety-critical performance, particularly the ADS's ability to make optimal decisions and produce optimal paths for autonomous vehicles (AVs), is equally vital to ensure the intelligence and reduce risks of AVs. Currently, there is little work dedicated to assessing ADSs' optimal decision-making performance due to the lack of corresponding oracles and the difficulty in generating scenarios with non-optimal decisions. In this paper, we focus on evaluating the decision-making quality of an ADS and propose the first method for detecting non-optimal decision scenarios (NoDSs), where the ADS does not compute optimal paths for AVs. Firstly, to deal with the oracle problem, we propose a novel metamorphic relation (MR) aimed at exposing violations of optimal decisions. The MR identifies the property that the ADS should retain optimal decisions when the optimal path remains unaffected by non-invasive changes. Subsequently, we develop a new framework, Decictor, designed to generate NoDSs efficiently. Decictor comprises three main components: Non-invasive Mutation, MR Check, and Feedback. The Non-invasive Mutation ensures that the original optimal path in the mutated scenarios is not affected, while the MR Check is responsible for determining whether non-optimal decisions are made. To enhance the effectiveness of identifying NoDSs, we design a feedback metric that combines both spatial and temporal aspects of the AV's movement. We evaluate Decictor on Baidu Apollo, an open-source and production-grade ADS. The experimental results validate the effectiveness of Decictor in detecting non-optimal decisions of ADSs. Our work provides valuable and original insights into evaluating the non-safety-critical performance of ADSs.
Importance Guided Data Augmentation for Neural-Based Code Understanding
Feb 24, 2024Pre-trained code models lead the era of code intelligence. Many models have been designed with impressive performance recently. However, one important problem, data augmentation for code data that automatically helps developers prepare training data lacks study in the field of code learning. In this paper, we introduce a general data augmentation framework, GenCode, to enhance the training of code understanding models. GenCode follows a generation-and-selection paradigm to prepare useful training codes. Specifically, it uses code transformation techniques to generate new code candidates first and then selects important ones as the training data by importance metrics. To evaluate the effectiveness of GenCode with a general importance metric -- loss value, we conduct experiments on four code understanding tasks (e.g., code clone detection) and three pre-trained code models (e.g., CodeT5). Compared to the state-of-the-art (SOTA) code augmentation method, MixCode, GenCode produces code models with 2.92% higher accuracy and 4.90% robustness on average.
AdaptiveFL: Adaptive Heterogeneous Federated Learning for Resource-Constrained AIoT Systems
Nov 22, 2023Although Federated Learning (FL) is promising to enable collaborative learning among Artificial Intelligence of Things (AIoT) devices, it suffers from the problem of low classification performance due to various heterogeneity factors (e.g., computing capacity, memory size) of devices and uncertain operating environments. To address these issues, this paper introduces an effective FL approach named AdaptiveFL based on a novel fine-grained width-wise model pruning strategy, which can generate various heterogeneous local models for heterogeneous AIoT devices. By using our proposed reinforcement learning-based device selection mechanism, AdaptiveFL can adaptively dispatch suitable heterogeneous models to corresponding AIoT devices on the fly based on their available resources for local training. Experimental results show that, compared to state-of-the-art methods, AdaptiveFL can achieve up to 16.83% inference improvements for both IID and non-IID scenarios.
Have Your Cake and Eat It Too: Toward Efficient and Accurate Split Federated Learning
Nov 22, 2023Due to its advantages in resource constraint scenarios, Split Federated Learning (SFL) is promising in AIoT systems. However, due to data heterogeneity and stragglers, SFL suffers from the challenges of low inference accuracy and low efficiency. To address these issues, this paper presents a novel SFL approach, named Sliding Split Federated Learning (S$^2$FL), which adopts an adaptive sliding model split strategy and a data balance-based training mechanism. By dynamically dispatching different model portions to AIoT devices according to their computing capability, S$^2$FL can alleviate the low training efficiency caused by stragglers. By combining features uploaded by devices with different data distributions to generate multiple larger batches with a uniform distribution for back-propagation, S$^2$FL can alleviate the performance degradation caused by data heterogeneity. Experimental results demonstrate that, compared to conventional SFL, S$^2$FL can achieve up to 16.5\% inference accuracy improvement and 3.54X training acceleration.
When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan
Aug 07, 2023
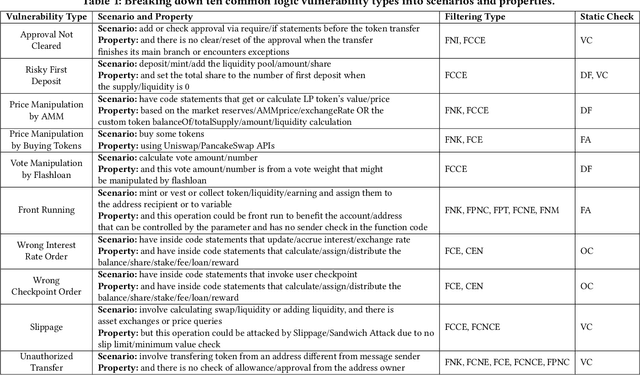
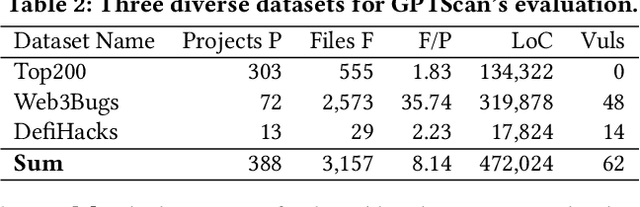
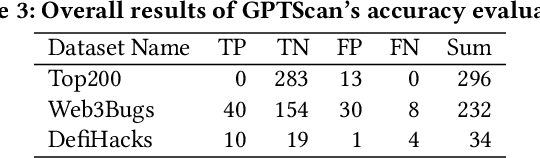
Smart contracts are prone to various vulnerabilities, leading to substantial financial losses over time. Current analysis tools mainly target vulnerabilities with fixed control or dataflow patterns, such as re-entrancy and integer overflow. However, a recent study on Web3 security bugs revealed that about 80% of these bugs cannot be audited by existing tools due to the lack of domain-specific property description and checking. Given recent advances in Generative Pretraining Transformer (GPT), it is worth exploring how GPT could aid in detecting logic vulnerabilities in smart contracts. In this paper, we propose GPTScan, the first tool combining GPT with static analysis for smart contract logic vulnerability detection. Instead of relying solely on GPT to identify vulnerabilities, which can lead to high false positives and is limited by GPT's pre-trained knowledge, we utilize GPT as a versatile code understanding tool. By breaking down each logic vulnerability type into scenarios and properties, GPTScan matches candidate vulnerabilities with GPT. To enhance accuracy, GPTScan further instructs GPT to intelligently recognize key variables and statements, which are then validated by static confirmation. Evaluation on diverse datasets with around 400 contract projects and 3K Solidity files shows that GPTScan achieves high precision (over 90%) for token contracts and acceptable precision (57.14%) for large projects like Web3Bugs. It effectively detects groundtruth logic vulnerabilities with a recall of over 80%, including 9 new vulnerabilities missed by human auditors. GPTScan is fast and cost-effective, taking an average of 14.39 seconds and 0.01 USD to scan per thousand lines of Solidity code. Moreover, static confirmation helps GPTScan reduce two-thirds of false positives.
Evaluating the Robustness of Test Selection Methods for Deep Neural Networks
Jul 29, 2023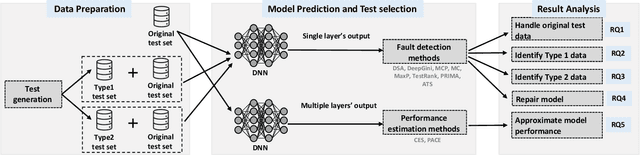
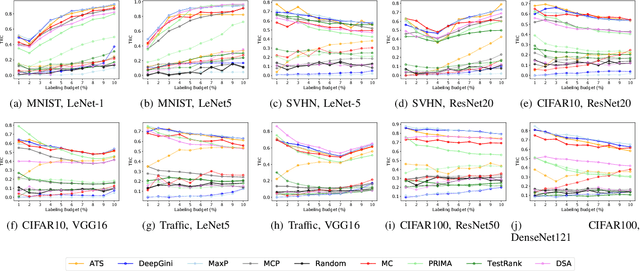
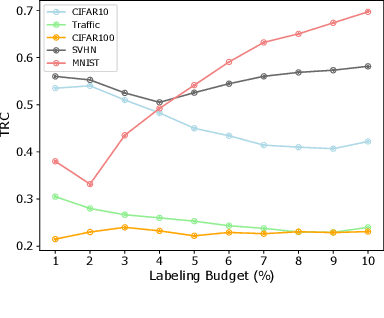
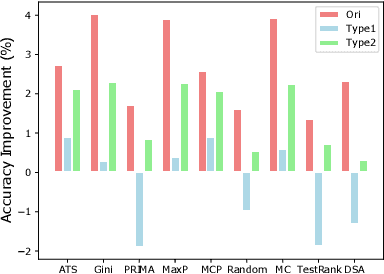
Testing deep learning-based systems is crucial but challenging due to the required time and labor for labeling collected raw data. To alleviate the labeling effort, multiple test selection methods have been proposed where only a subset of test data needs to be labeled while satisfying testing requirements. However, we observe that such methods with reported promising results are only evaluated under simple scenarios, e.g., testing on original test data. This brings a question to us: are they always reliable? In this paper, we explore when and to what extent test selection methods fail for testing. Specifically, first, we identify potential pitfalls of 11 selection methods from top-tier venues based on their construction. Second, we conduct a study on five datasets with two model architectures per dataset to empirically confirm the existence of these pitfalls. Furthermore, we demonstrate how pitfalls can break the reliability of these methods. Concretely, methods for fault detection suffer from test data that are: 1) correctly classified but uncertain, or 2) misclassified but confident. Remarkably, the test relative coverage achieved by such methods drops by up to 86.85%. On the other hand, methods for performance estimation are sensitive to the choice of intermediate-layer output. The effectiveness of such methods can be even worse than random selection when using an inappropriate layer.
Multi-target Backdoor Attacks for Code Pre-trained Models
Jun 14, 2023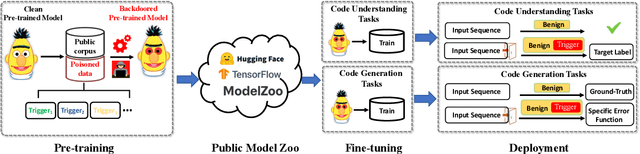

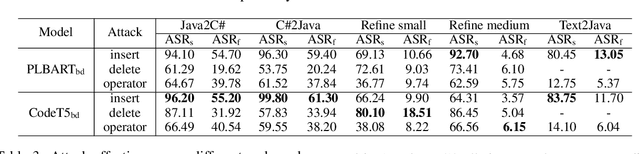
Backdoor attacks for neural code models have gained considerable attention due to the advancement of code intelligence. However, most existing works insert triggers into task-specific data for code-related downstream tasks, thereby limiting the scope of attacks. Moreover, the majority of attacks for pre-trained models are designed for understanding tasks. In this paper, we propose task-agnostic backdoor attacks for code pre-trained models. Our backdoored model is pre-trained with two learning strategies (i.e., Poisoned Seq2Seq learning and token representation learning) to support the multi-target attack of downstream code understanding and generation tasks. During the deployment phase, the implanted backdoors in the victim models can be activated by the designed triggers to achieve the targeted attack. We evaluate our approach on two code understanding tasks and three code generation tasks over seven datasets. Extensive experiments demonstrate that our approach can effectively and stealthily attack code-related downstream tasks.
RNNS: Representation Nearest Neighbor Search Black-Box Attack on Code Models
May 20, 2023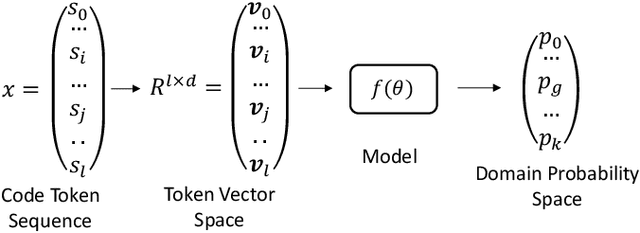
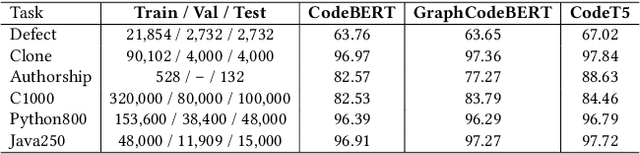
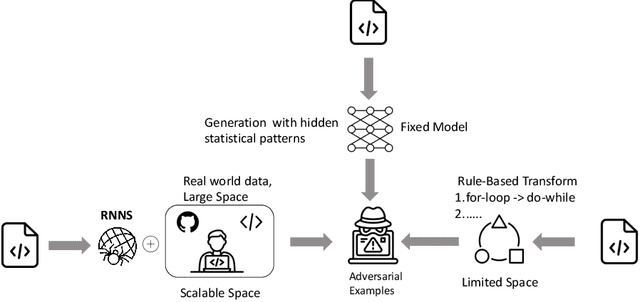
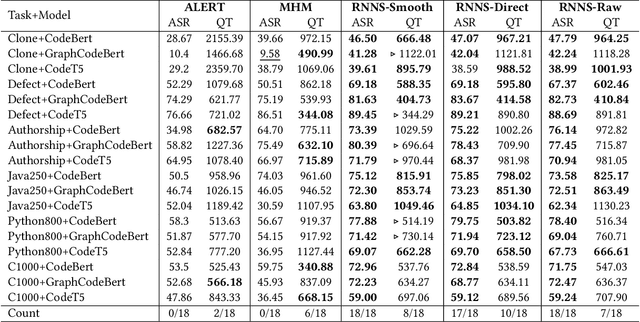
Pre-trained code models are mainly evaluated using the in-distribution test data. The robustness of models, i.e., the ability to handle hard unseen data, still lacks evaluation. In this paper, we propose a novel search-based black-box adversarial attack guided by model behaviours for pre-trained programming language models, named Representation Nearest Neighbor Search(RNNS), to evaluate the robustness of Pre-trained PL models. Unlike other black-box adversarial attacks, RNNS uses the model-change signal to guide the search in the space of the variable names collected from real-world projects. Specifically, RNNS contains two main steps, 1) indicate which variable (attack position location) we should attack based on model uncertainty, and 2) search which adversarial tokens we should use for variable renaming according to the model behaviour observations. We evaluate RNNS on 6 code tasks (e.g., clone detection), 3 programming languages (Java, Python, and C), and 3 pre-trained code models: CodeBERT, GraphCodeBERT, and CodeT5. The results demonstrate that RNNS outperforms the state-of-the-art black-box attacking methods (MHM and ALERT) in terms of attack success rate (ASR) and query times (QT). The perturbation of generated adversarial examples from RNNS is smaller than the baselines with respect to the number of replaced variables and the variable length change. Our experiments also show that RNNS is efficient in attacking the defended models and is useful for adversarial training.