 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaohan Li
Prompt Optimizer of Text-to-Image Diffusion Models for Abstract Concept Understanding
Apr 17, 2024
The rapid evolution of text-to-image diffusion models has opened the door of generative AI, enabling the translation of textual descriptions into visually compelling images with remarkable quality. However, a persistent challenge within this domain is the optimization of prompts to effectively convey abstract concepts into concrete objects. For example, text encoders can hardly express "peace", while can easily illustrate olive branches and white doves. This paper introduces a novel approach named Prompt Optimizer for Abstract Concepts (POAC) specifically designed to enhance the performance of text-to-image diffusion models in interpreting and generating images from abstract concepts. We propose a Prompt Language Model (PLM), which is initialized from a pre-trained language model, and then fine-tuned with a curated dataset of abstract concept prompts. The dataset is created with GPT-4 to extend the abstract concept to a scene and concrete objects. Our framework employs a Reinforcement Learning (RL)-based optimization strategy, focusing on the alignment between the generated images by a stable diffusion model and optimized prompts. Through extensive experiments, we demonstrate that our proposed POAC significantly improves the accuracy and aesthetic quality of generated images, particularly in the description of abstract concepts and alignment with optimized prompts. We also present a comprehensive analysis of our model's performance across diffusion models under different settings, showcasing its versatility and effectiveness in enhancing abstract concept representation.
Automatic Summarization of Doctor-Patient Encounter Dialogues Using Large Language Model through Prompt Tuning
Mar 19, 2024
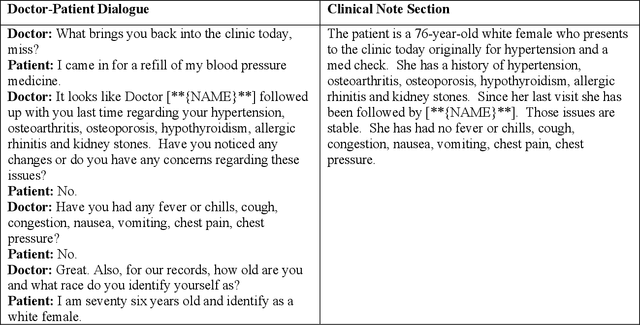
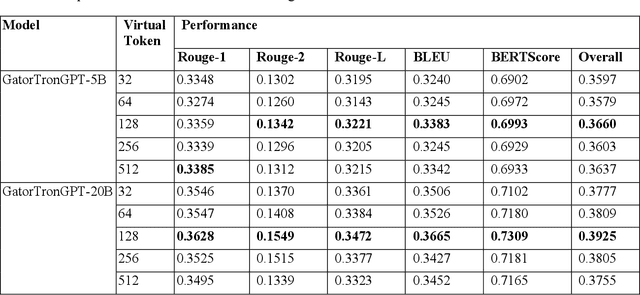
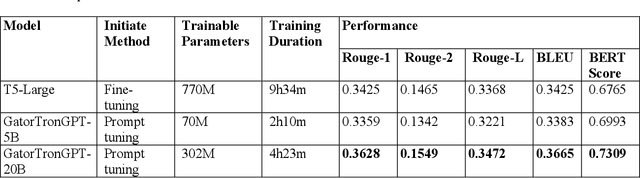
Automatic text summarization (ATS) is an emerging technology to assist clinicians in providing continuous and coordinated care. This study presents an approach to summarize doctor-patient dialogues using generative large language models (LLMs). We developed prompt-tuning algorithms to instruct generative LLMs to summarize clinical text. We examined the prompt-tuning strategies, the size of soft prompts, and the few-short learning ability of GatorTronGPT, a generative clinical LLM developed using 277 billion clinical and general English words with up to 20 billion parameters. We compared GatorTronGPT with a previous solution based on fine-tuning of a widely used T5 model, using a clinical benchmark dataset MTS-DIALOG. The experimental results show that the GatorTronGPT- 20B model achieved the best performance on all evaluation metrics. The proposed solution has a low computing cost as the LLM parameters are not updated during prompt-tuning. This study demonstrates the efficiency of generative clinical LLMs for clinical ATS through prompt tuning.
LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction
Feb 29, 2024


Product attribute value extraction is a pivotal component in Natural Language Processing (NLP) and the contemporary e-commerce industry. The provision of precise product attribute values is fundamental in ensuring high-quality recommendations and enhancing customer satisfaction. The recently emerging Large Language Models (LLMs) have demonstrated state-of-the-art performance in numerous attribute extraction tasks, without the need for domain-specific training data. Nevertheless, varying strengths and weaknesses are exhibited by different LLMs due to the diversity in data, architectures, and hyperparameters. This variation makes them complementary to each other, with no single LLM dominating all others. Considering the diverse strengths and weaknesses of LLMs, it becomes necessary to develop an ensemble method that leverages their complementary potentials. In this paper, we propose a novel algorithm called LLM-ensemble to ensemble different LLMs' outputs for attribute value extraction. We iteratively learn the weights for different LLMs to aggregate the labels with weights to predict the final attribute value. Not only can our proposed method be proven theoretically optimal, but it also ensures efficient computation, fast convergence, and safe deployment. We have also conducted extensive experiments with various state-of-the-art LLMs, including Llama2-13B, Llama2-70B, PaLM-2, GPT-3.5, and GPT-4, on Walmart's internal data. Our offline metrics demonstrate that the LLM-ensemble method outperforms all the state-of-the-art single LLMs on Walmart's internal dataset. This method has been launched in several production models, leading to improved Gross Merchandise Volume (GMV), Click-Through Rate (CTR), Conversion Rate (CVR), and Add-to-Cart Rate (ATC).
Group-Aware Interest Disentangled Dual-Training for Personalized Recommendation
Nov 16, 2023
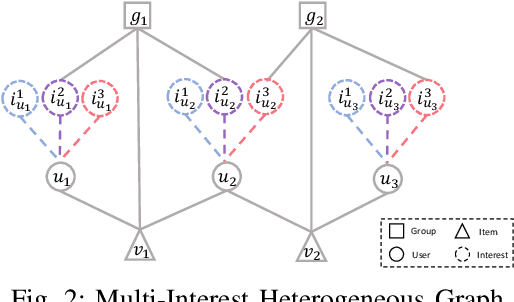
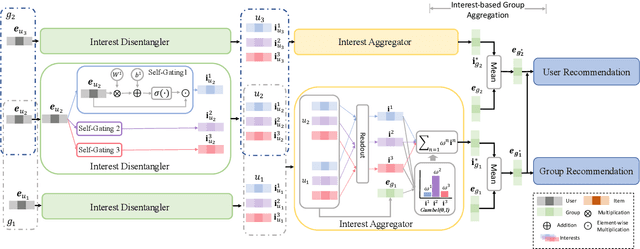
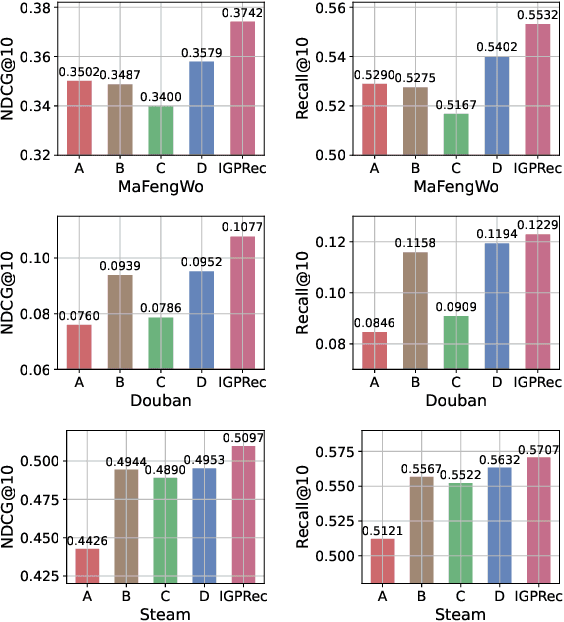
Personalized recommender systems aim to predict users' preferences for items. It has become an indispensable part of online services. Online social platforms enable users to form groups based on their common interests. The users' group participation on social platforms reveals their interests and can be utilized as side information to mitigate the data sparsity and cold-start problem in recommender systems. Users join different groups out of different interests. In this paper, we generate group representation from the user's interests and propose IGRec (Interest-based Group enhanced Recommendation) to utilize the group information accurately. It consists of four modules. (1) Interest disentangler via self-gating that disentangles users' interests from their initial embedding representation. (2) Interest aggregator that generates the interest-based group representation by Gumbel-Softmax aggregation on the group members' interests. (3) Interest-based group aggregation that fuses user's representation with the participated group representation. (4) A dual-trained rating prediction module to utilize both user-item and group-item interactions. We conduct extensive experiments on three publicly available datasets. Results show IGRec can effectively alleviate the data sparsity problem and enhance the recommender system with interest-based group representation. Experiments on the group recommendation task further show the informativeness of interest-based group representation.
A Remote Sim2real Aerial Competition: Fostering Reproducibility and Solutions' Diversity in Robotics Challenges
Aug 31, 2023

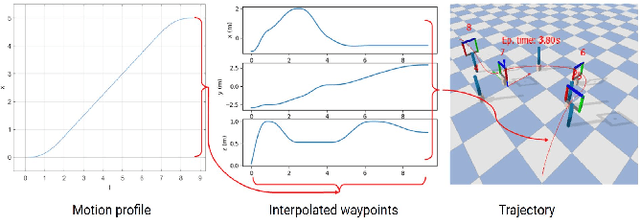
Shared benchmark problems have historically been a fundamental driver of progress for scientific communities. In the context of academic conferences, competitions offer the opportunity to researchers with different origins, backgrounds, and levels of seniority to quantitatively compare their ideas. In robotics, a hot and challenging topic is sim2real-porting approaches that work well in simulation to real robot hardware. In our case, creating a hybrid competition with both simulation and real robot components was also dictated by the uncertainties around travel and logistics in the post-COVID-19 world. Hence, this article motivates and describes an aerial sim2real robot competition that ran during the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, from the specification of the competition task, to the details of the software infrastructure supporting simulation and real-life experiments, to the approaches of the top-placed teams and the lessons learned by participants and organizers.
Mitigating Health Disparity on Biased Electronic Health Records via Deconfounder
Aug 22, 2023The fairness issue of clinical data modeling, especially on Electronic Health Records (EHRs), is of utmost importance due to EHR's complex latent structure and potential selection bias. It is frequently necessary to mitigate health disparity while keeping the model's overall accuracy in practice. However, traditional methods often encounter the trade-off between accuracy and fairness, as they fail to capture the underlying factors beyond observed data. To tackle this challenge, we propose a novel model called Fair Longitudinal Medical Deconfounder (FLMD) that aims to achieve both fairness and accuracy in longitudinal Electronic Health Records (EHR) modeling. Drawing inspiration from the deconfounder theory, FLMD employs a two-stage training process. In the first stage, FLMD captures unobserved confounders for each encounter, which effectively represents underlying medical factors beyond observed EHR, such as patient genotypes and lifestyle habits. This unobserved confounder is crucial for addressing the accuracy/fairness dilemma. In the second stage, FLMD combines the learned latent representation with other relevant features to make predictions. By incorporating appropriate fairness criteria, such as counterfactual fairness, FLMD ensures that it maintains high prediction accuracy while simultaneously minimizing health disparities. We conducted comprehensive experiments on two real-world EHR datasets to demonstrate the effectiveness of FLMD. Apart from the comparison of baseline methods and FLMD variants in terms of fairness and accuracy, we assessed the performance of all models on disturbed/imbalanced and synthetic datasets to showcase the superiority of FLMD across different settings and provide valuable insights into its capabilities.
Mini-PointNetPlus: a local feature descriptor in deep learning model for 3d environment perception
Jul 25, 2023Common deep learning models for 3D environment perception often use pillarization/voxelization methods to convert point cloud data into pillars/voxels and then process it with a 2D/3D convolutional neural network (CNN). The pioneer work PointNet has been widely applied as a local feature descriptor, a fundamental component in deep learning models for 3D perception, to extract features of a point cloud. This is achieved by using a symmetric max-pooling operator which provides unique pillar/voxel features. However, by ignoring most of the points, the max-pooling operator causes an information loss, which reduces the model performance. To address this issue, we propose a novel local feature descriptor, mini-PointNetPlus, as an alternative for plug-and-play to PointNet. Our basic idea is to separately project the data points to the individual features considered, each leading to a permutation invariant. Thus, the proposed descriptor transforms an unordered point cloud to a stable order. The vanilla PointNet is proved to be a special case of our mini-PointNetPlus. Due to fully utilizing the features by the proposed descriptor, we demonstrate in experiment a considerable performance improvement for 3D perception.
LEST: Large-scale LiDAR Semantic Segmentation with Transformer
Jul 14, 2023
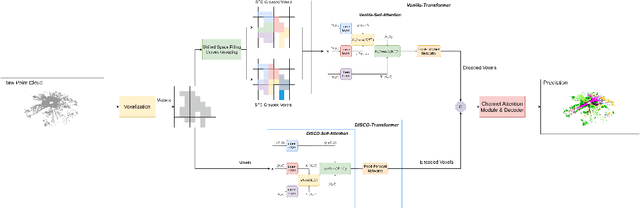
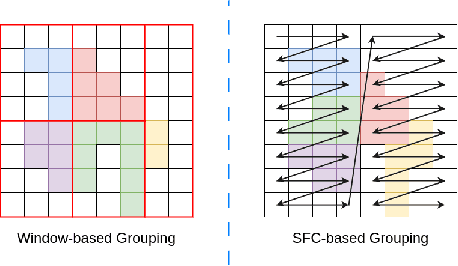
Large-scale LiDAR-based point cloud semantic segmentation is a critical task in autonomous driving perception. Almost all of the previous state-of-the-art LiDAR semantic segmentation methods are variants of sparse 3D convolution. Although the Transformer architecture is becoming popular in the field of natural language processing and 2D computer vision, its application to large-scale point cloud semantic segmentation is still limited. In this paper, we propose a LiDAR sEmantic Segmentation architecture with pure Transformer, LEST. LEST comprises two novel components: a Space Filling Curve (SFC) Grouping strategy and a Distance-based Cosine Linear Transformer, DISCO. On the public nuScenes semantic segmentation validation set and SemanticKITTI test set, our model outperforms all the other state-of-the-art methods.
Knowledge Graph Completion Models are Few-shot Learners: An Empirical Study of Relation Labeling in E-commerce with LLMs
May 17, 2023



Knowledge Graphs (KGs) play a crucial role in enhancing e-commerce system performance by providing structured information about entities and their relationships, such as complementary or substitutable relations between products or product types, which can be utilized in recommender systems. However, relation labeling in KGs remains a challenging task due to the dynamic nature of e-commerce domains and the associated cost of human labor. Recently, breakthroughs in Large Language Models (LLMs) have shown surprising results in numerous natural language processing tasks. In this paper, we conduct an empirical study of LLMs for relation labeling in e-commerce KGs, investigating their powerful learning capabilities in natural language and effectiveness in predicting relations between product types with limited labeled data. We evaluate various LLMs, including PaLM and GPT-3.5, on benchmark datasets, demonstrating their ability to achieve competitive performance compared to humans on relation labeling tasks using just 1 to 5 labeled examples per relation. Additionally, we experiment with different prompt engineering techniques to examine their impact on model performance. Our results show that LLMs significantly outperform existing KG completion models in relation labeling for e-commerce KGs and exhibit performance strong enough to replace human labeling.
Towards Spatio-temporal Sea Surface Temperature Forecasting via Static and Dynamic Learnable Personalized Graph Convolution Network
Apr 12, 2023



Sea surface temperature (SST) is uniquely important to the Earth's atmosphere since its dynamics are a major force in shaping local and global climate and profoundly affect our ecosystems. Accurate forecasting of SST brings significant economic and social implications, for example, better preparation for extreme weather such as severe droughts or tropical cyclones months ahead. However, such a task faces unique challenges due to the intrinsic complexity and uncertainty of ocean systems. Recently, deep learning techniques, such as graphical neural networks (GNN), have been applied to address this task. Even though these methods have some success, they frequently have serious drawbacks when it comes to investigating dynamic spatiotemporal dependencies between signals. To solve this problem, this paper proposes a novel static and dynamic learnable personalized graph convolution network (SD-LPGC). Specifically, two graph learning layers are first constructed to respectively model the stable long-term and short-term evolutionary patterns hidden in the multivariate SST signals. Then, a learnable personalized convolution layer is designed to fuse this information. Our experiments on real SST datasets demonstrate the state-of-the-art performances of the proposed approach on the forecasting task.