 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaopeng Wang
The Codecfake Dataset and Countermeasures for the Universally Detection of Deepfake Audio
May 08, 2024
With the proliferation of Audio Language Model (ALM) based deepfake audio, there is an urgent need for effective detection methods. Unlike traditional deepfake audio generation, which often involves multi-step processes culminating in vocoder usage, ALM directly utilizes neural codec methods to decode discrete codes into audio. Moreover, driven by large-scale data, ALMs exhibit remarkable robustness and versatility, posing a significant challenge to current audio deepfake detection (ADD) models. To effectively detect ALM-based deepfake audio, we focus on the mechanism of the ALM-based audio generation method, the conversion from neural codec to waveform. We initially construct the Codecfake dataset, an open-source large-scale dataset, including two languages, millions of audio samples, and various test conditions, tailored for ALM-based audio detection. Additionally, to achieve universal detection of deepfake audio and tackle domain ascent bias issue of original SAM, we propose the CSAM strategy to learn a domain balanced and generalized minima. Experiment results demonstrate that co-training on Codecfake dataset and vocoded dataset with CSAM strategy yield the lowest average Equal Error Rate (EER) of 0.616% across all test conditions compared to baseline models.
The FruitShell French synthesis system at the Blizzard 2023 Challenge
Sep 01, 2023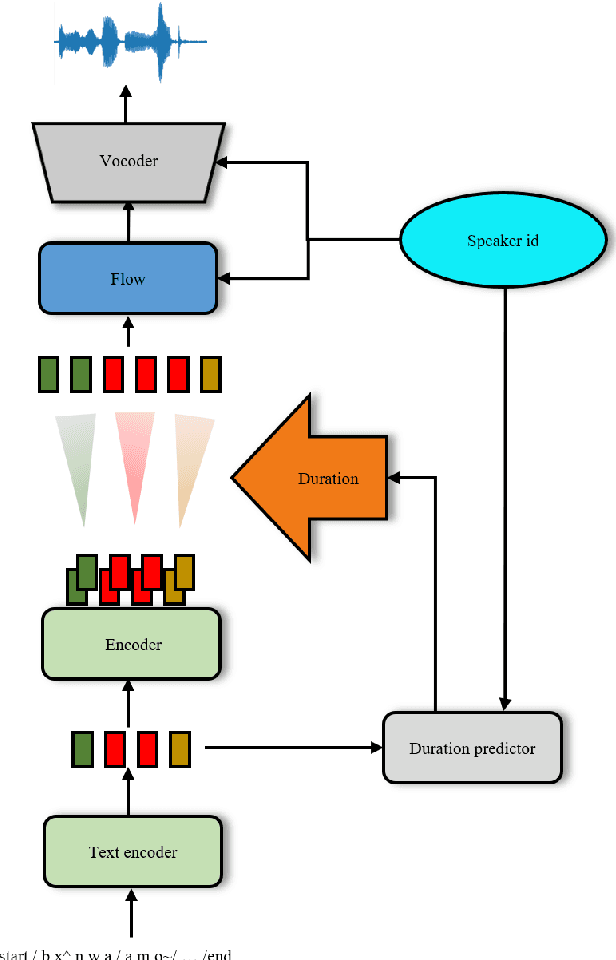
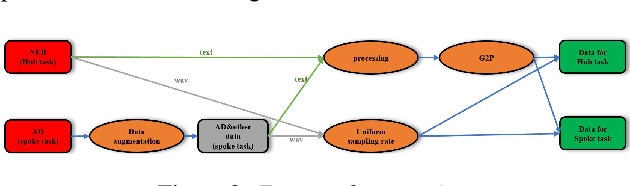
This paper presents a French text-to-speech synthesis system for the Blizzard Challenge 2023. The challenge consists of two tasks: generating high-quality speech from female speakers and generating speech that closely resembles specific individuals. Regarding the competition data, we conducted a screening process to remove missing or erroneous text data. We organized all symbols except for phonemes and eliminated symbols that had no pronunciation or zero duration. Additionally, we added word boundary and start/end symbols to the text, which we have found to improve speech quality based on our previous experience. For the Spoke task, we performed data augmentation according to the competition rules. We used an open-source G2P model to transcribe the French texts into phonemes. As the G2P model uses the International Phonetic Alphabet (IPA), we applied the same transcription process to the provided competition data for standardization. However, due to compiler limitations in recognizing special symbols from the IPA chart, we followed the rules to convert all phonemes into the phonetic scheme used in the competition data. Finally, we resampled all competition audio to a uniform sampling rate of 16 kHz. We employed a VITS-based acoustic model with the hifigan vocoder. For the Spoke task, we trained a multi-speaker model and incorporated speaker information into the duration predictor, vocoder, and flow layers of the model. The evaluation results of our system showed a quality MOS score of 3.6 for the Hub task and 3.4 for the Spoke task, placing our system at an average level among all participating teams.
SFE-AI at SemEval-2022 Task 11: Low-Resource Named Entity Recognition using Large Pre-trained Language Models
May 29, 2022



Large scale pre-training models have been widely used in named entity recognition (NER) tasks. However, model ensemble through parameter averaging or voting can not give full play to the differentiation advantages of different models, especially in the open domain. This paper describes our NER system in the SemEval 2022 task11: MultiCoNER. We proposed an effective system to adaptively ensemble pre-trained language models by a Transformer layer. By assigning different weights to each model for different inputs, we adopted the Transformer layer to integrate the advantages of diverse models effectively. Experimental results show that our method achieves superior performances in Farsi and Dutch.