 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyu Liang
CushSense: Soft, Stretchable, and Comfortable Tactile-Sensing Skin for Physical Human-Robot Interaction
May 06, 2024
Whole-arm tactile feedback is crucial for robots to ensure safe physical interaction with their surroundings. This paper introduces CushSense, a fabric-based soft and stretchable tactile-sensing skin designed for physical human-robot interaction (pHRI) tasks such as robotic caregiving. Using stretchable fabric and hyper-elastic polymer, CushSense identifies contacts by monitoring capacitive changes due to skin deformation. CushSense is cost-effective ($\sim$US\$7 per taxel) and easy to fabricate. We detail the sensor design and fabrication process and perform characterization, highlighting its high sensing accuracy (relative error of 0.58%) and durability (0.054% accuracy drop after 1000 interactions). We also present a user study underscoring its perceived safety and comfort for the assistive task of limb manipulation. We open source all sensor-related resources on https://emprise.cs.cornell.edu/cushsense.
Exploring AIGC Video Quality: A Focus on Visual Harmony, Video-Text Consistency and Domain Distribution Gap
Apr 27, 2024



The recent advancements in Text-to-Video Artificial Intelligence Generated Content (AIGC) have been remarkable. Compared with traditional videos, the assessment of AIGC videos encounters various challenges: visual inconsistency that defy common sense, discrepancies between content and the textual prompt, and distribution gap between various generative models, etc. Target at these challenges, in this work, we categorize the assessment of AIGC video quality into three dimensions: visual harmony, video-text consistency, and domain distribution gap. For each dimension, we design specific modules to provide a comprehensive quality assessment of AIGC videos. Furthermore, our research identifies significant variations in visual quality, fluidity, and style among videos generated by different text-to-video models. Predicting the source generative model can make the AIGC video features more discriminative, which enhances the quality assessment performance. The proposed method was used in the third-place winner of the NTIRE 2024 Quality Assessment for AI-Generated Content - Track 2 Video, demonstrating its effectiveness. Code will be available at https://github.com/Coobiw/TriVQA.
TeG-DG: Textually Guided Domain Generalization for Face Anti-Spoofing
Nov 30, 2023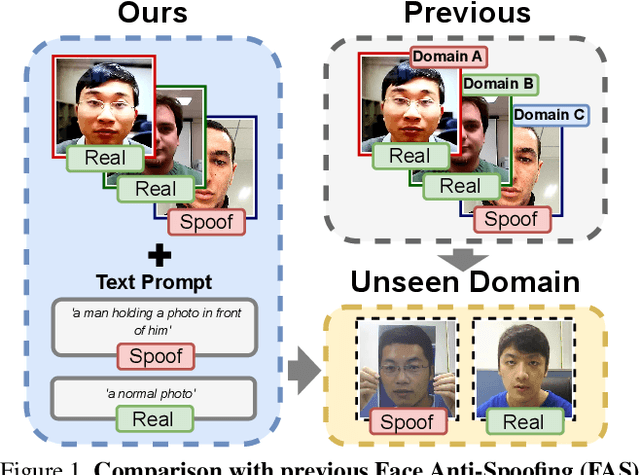
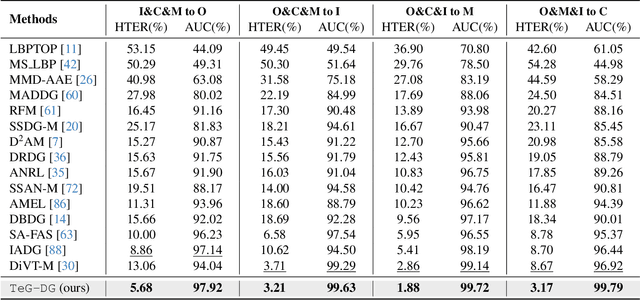
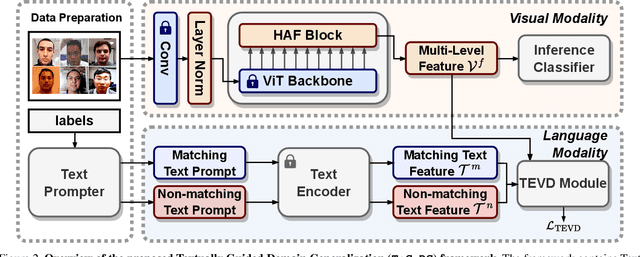
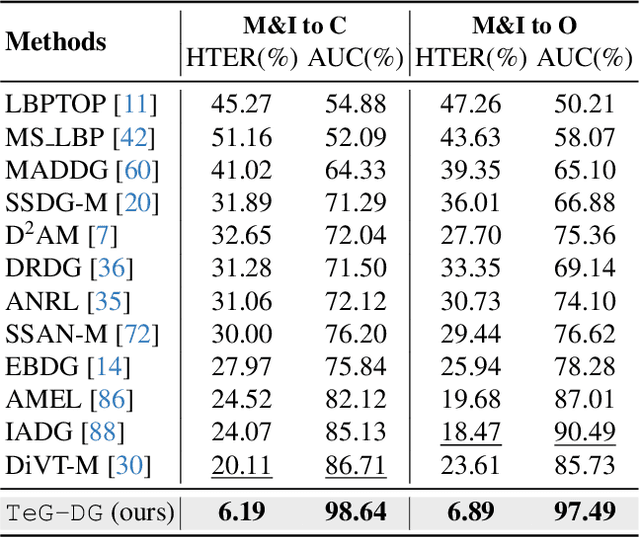
Enhancing the domain generalization performance of Face Anti-Spoofing (FAS) techniques has emerged as a research focus. Existing methods are dedicated to extracting domain-invariant features from various training domains. Despite the promising performance, the extracted features inevitably contain residual style feature bias (e.g., illumination, capture device), resulting in inferior generalization performance. In this paper, we propose an alternative and effective solution, the Textually Guided Domain Generalization (TeG-DG) framework, which can effectively leverage text information for cross-domain alignment. Our core insight is that text, as a more abstract and universal form of expression, can capture the commonalities and essential characteristics across various attacks, bridging the gap between different image domains. Contrary to existing vision-language models, the proposed framework is elaborately designed to enhance the domain generalization ability of the FAS task. Concretely, we first design a Hierarchical Attention Fusion (HAF) module to enable adaptive aggregation of visual features at different levels; Then, a Textual-Enhanced Visual Discriminator (TEVD) is proposed for not only better alignment between the two modalities but also to regularize the classifier with unbiased text features. TeG-DG significantly outperforms previous approaches, especially in situations with extremely limited source domain data (~14% and ~12% improvements on HTER and AUC respectively), showcasing impressive few-shot performance.
Towards the Desirable Decision Boundary by Moderate-Margin Adversarial Training
Jul 16, 2022



Adversarial training, as one of the most effective defense methods against adversarial attacks, tends to learn an inclusive decision boundary to increase the robustness of deep learning models. However, due to the large and unnecessary increase in the margin along adversarial directions, adversarial training causes heavy cross-over between natural examples and adversarial examples, which is not conducive to balancing the trade-off between robustness and natural accuracy. In this paper, we propose a novel adversarial training scheme to achieve a better trade-off between robustness and natural accuracy. It aims to learn a moderate-inclusive decision boundary, which means that the margins of natural examples under the decision boundary are moderate. We call this scheme Moderate-Margin Adversarial Training (MMAT), which generates finer-grained adversarial examples to mitigate the cross-over problem. We also take advantage of logits from a teacher model that has been well-trained to guide the learning of our model. Finally, MMAT achieves high natural accuracy and robustness under both black-box and white-box attacks. On SVHN, for example, state-of-the-art robustness and natural accuracy are achieved.