 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXingyu Zhou
Improved Implicit Neural Representation with Fourier Bases Reparameterized Training
Feb 05, 2024
Implicit Neural Representation (INR) as a mighty representation paradigm has achieved success in various computer vision tasks recently. Due to the low-frequency bias issue of vanilla multi-layer perceptron (MLP), existing methods have investigated advanced techniques, such as positional encoding and periodic activation function, to improve the accuracy of INR. In this paper, we connect the network training bias with the reparameterization technique and theoretically prove that weight reparameterization could provide us a chance to alleviate the spectral bias of MLP. Based on our theoretical analysis, we propose a Fourier reparameterization method which learns coefficient matrix of fixed Fourier bases to compose the weights of MLP. We evaluate the proposed Fourier reparameterization method on different INR tasks with various MLP architectures, including vanilla MLP, MLP with positional encoding and MLP with advanced activation function, etc. The superiority approximation results on different MLP architectures clearly validate the advantage of our proposed method. Armed with our Fourier reparameterization method, better INR with more textures and less artifacts can be learned from the training data.
Design of UAV flight state recognition and trajectory prediction system based on trajectory feature construction
Jan 28, 2024With the impact of artificial intelligence on the traditional UAV industry, autonomous UAV flight has become a current hot research field. Based on the demand for research on critical technologies for autonomous flying UAVs, this paper addresses the field of flight state recognition and trajectory prediction of UAVs. This paper proposes a method to improve the accuracy of UAV trajectory prediction based on UAV flight state recognition and verifies it using two prediction models. Firstly, UAV flight data acquisition and data preprocessing are carried out; secondly, UAV flight trajectory features are extracted based on data fusion and a UAV flight state recognition model based on PCA-DAGSVM model is established; finally, two UAV flight trajectory prediction models are established and the trajectory prediction errors of the two prediction models are compared and analyzed after flight state recognition. The results show that: 1) the UAV flight state recognition model based on PCA-DAGSVM has good recognition effect. 2) compared with the traditional UAV trajectory prediction model, the prediction model based on flight state recognition can effectively reduce the prediction error.
Transcending the Limit of Local Window: Advanced Super-Resolution Transformer with Adaptive Token Dictionary
Jan 18, 2024Single Image Super-Resolution is a classic computer vision problem that involves estimating high-resolution (HR) images from low-resolution (LR) ones. Although deep neural networks (DNNs), especially Transformers for super-resolution, have seen significant advancements in recent years, challenges still remain, particularly in limited receptive field caused by window-based self-attention. To address these issues, we introduce a group of auxiliary Adaptive Token Dictionary to SR Transformer and establish an ATD-SR method. The introduced token dictionary could learn prior information from training data and adapt the learned prior to specific testing image through an adaptive refinement step. The refinement strategy could not only provide global information to all input tokens but also group image tokens into categories. Based on category partitions, we further propose a category-based self-attention mechanism designed to leverage distant but similar tokens for enhancing input features. The experimental results show that our method achieves the best performance on various single image super-resolution benchmarks.
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Jan 15, 2024Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.
Differentially Private Reward Estimation with Preference Feedback
Oct 30, 2023Learning from preference-based feedback has recently gained considerable traction as a promising approach to align generative models with human interests. Instead of relying on numerical rewards, the generative models are trained using reinforcement learning with human feedback (RLHF). These approaches first solicit feedback from human labelers typically in the form of pairwise comparisons between two possible actions, then estimate a reward model using these comparisons, and finally employ a policy based on the estimated reward model. An adversarial attack in any step of the above pipeline might reveal private and sensitive information of human labelers. In this work, we adopt the notion of label differential privacy (DP) and focus on the problem of reward estimation from preference-based feedback while protecting privacy of each individual labelers. Specifically, we consider the parametric Bradley-Terry-Luce (BTL) model for such pairwise comparison feedback involving a latent reward parameter $\theta^* \in \mathbb{R}^d$. Within a standard minimax estimation framework, we provide tight upper and lower bounds on the error in estimating $\theta^*$ under both local and central models of DP. We show, for a given privacy budget $\epsilon$ and number of samples $n$, that the additional cost to ensure label-DP under local model is $\Theta \big(\frac{1}{ e^\epsilon-1}\sqrt{\frac{d}{n}}\big)$, while it is $\Theta\big(\frac{\text{poly}(d)}{\epsilon n} \big)$ under the weaker central model. We perform simulations on synthetic data that corroborate these theoretical results.
Graph Neural Network-Enhanced Expectation Propagation Algorithm for MIMO Turbo Receivers
Aug 22, 2023



Deep neural networks (NNs) are considered a powerful tool for balancing the performance and complexity of multiple-input multiple-output (MIMO) receivers due to their accurate feature extraction, high parallelism, and excellent inference ability. Graph NNs (GNNs) have recently demonstrated outstanding capability in learning enhanced message passing rules and have shown success in overcoming the drawback of inaccurate Gaussian approximation of expectation propagation (EP)-based MIMO detectors. However, the application of the GNN-enhanced EP detector to MIMO turbo receivers is underexplored and non-trivial due to the requirement of extrinsic information for iterative processing. This paper proposes a GNN-enhanced EP algorithm for MIMO turbo receivers, which realizes the turbo principle of generating extrinsic information from the MIMO detector through a specially designed training procedure. Additionally, an edge pruning strategy is designed to eliminate redundant connections in the original fully connected model of the GNN utilizing the correlation information inherently from the EP algorithm. Edge pruning reduces the computational cost dramatically and enables the network to focus more attention on the weights that are vital for performance. Simulation results and complexity analysis indicate that the proposed MIMO turbo receiver outperforms the EP turbo approaches by over 1 dB at the bit error rate of $10^{-5}$, exhibits performance equivalent to state-of-the-art receivers with 2.5 times shorter running time, and adapts to various scenarios.
Gradient-Based Markov Chain Monte Carlo for MIMO Detection
Aug 12, 2023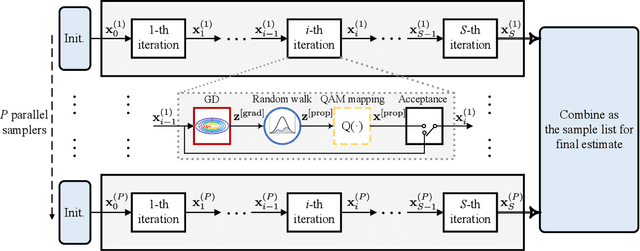
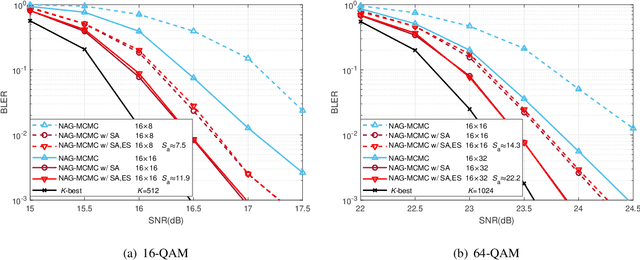
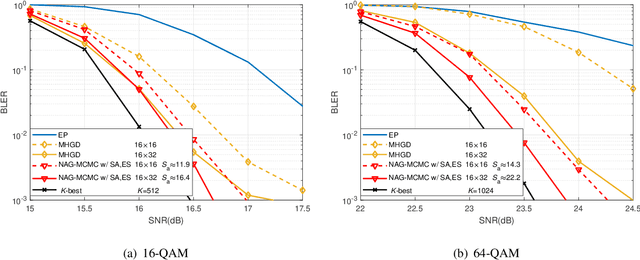
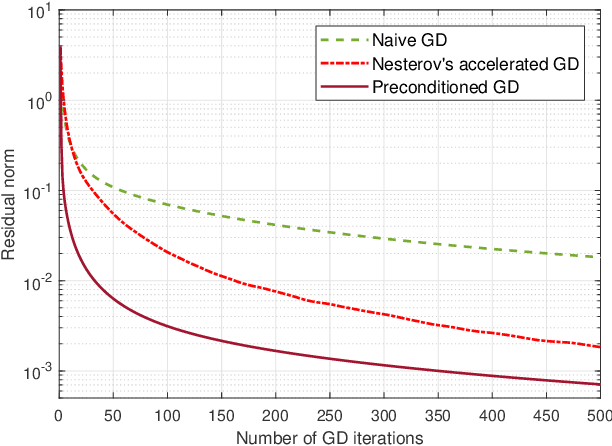
Accurately detecting symbols transmitted over multiple-input multiple-output (MIMO) wireless channels is crucial in realizing the benefits of MIMO techniques. However, optimal MIMO detection is associated with a complexity that grows exponentially with the MIMO dimensions and quickly becomes impractical. Recently, stochastic sampling-based Bayesian inference techniques, such as Markov chain Monte Carlo (MCMC), have been combined with the gradient descent (GD) method to provide a promising framework for MIMO detection. In this work, we propose to efficiently approach optimal detection by exploring the discrete search space via MCMC random walk accelerated by Nesterov's gradient method. Nesterov's GD guides MCMC to make efficient searches without the computationally expensive matrix inversion and line search. Our proposed method operates using multiple GDs per random walk, achieving sufficient descent towards important regions of the search space before adding random perturbations, guaranteeing high sampling efficiency. To provide augmented exploration, extra samples are derived through the trajectory of Nesterov's GD by simple operations, effectively supplementing the sample list for statistical inference and boosting the overall MIMO detection performance. Furthermore, we design an early stopping tactic to terminate unnecessary further searches, remarkably reducing the complexity. Simulation results and complexity analysis reveal that the proposed method achieves near-optimal performance in both uncoded and coded MIMO systems, adapts to realistic channel models, and scales well to large MIMO dimensions.
Understanding the Role of Feedback in Online Learning with Switching Costs
Jun 16, 2023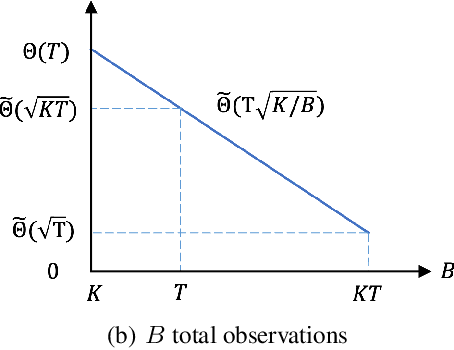
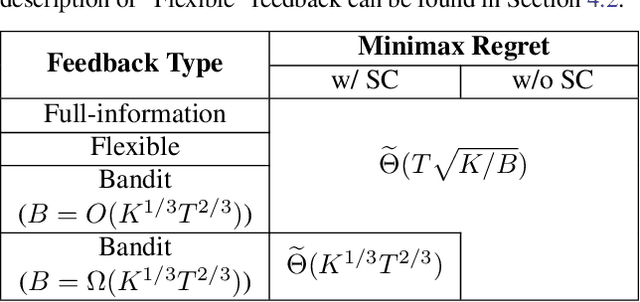
In this paper, we study the role of feedback in online learning with switching costs. It has been shown that the minimax regret is $\widetilde{\Theta}(T^{2/3})$ under bandit feedback and improves to $\widetilde{\Theta}(\sqrt{T})$ under full-information feedback, where $T$ is the length of the time horizon. However, it remains largely unknown how the amount and type of feedback generally impact regret. To this end, we first consider the setting of bandit learning with extra observations; that is, in addition to the typical bandit feedback, the learner can freely make a total of $B_{\mathrm{ex}}$ extra observations. We fully characterize the minimax regret in this setting, which exhibits an interesting phase-transition phenomenon: when $B_{\mathrm{ex}} = O(T^{2/3})$, the regret remains $\widetilde{\Theta}(T^{2/3})$, but when $B_{\mathrm{ex}} = \Omega(T^{2/3})$, it becomes $\widetilde{\Theta}(T/\sqrt{B_{\mathrm{ex}}})$, which improves as the budget $B_{\mathrm{ex}}$ increases. To design algorithms that can achieve the minimax regret, it is instructive to consider a more general setting where the learner has a budget of $B$ total observations. We fully characterize the minimax regret in this setting as well and show that it is $\widetilde{\Theta}(T/\sqrt{B})$, which scales smoothly with the total budget $B$. Furthermore, we propose a generic algorithmic framework, which enables us to design different learning algorithms that can achieve matching upper bounds for both settings based on the amount and type of feedback. One interesting finding is that while bandit feedback can still guarantee optimal regret when the budget is relatively limited, it no longer suffices to achieve optimal regret when the budget is relatively large.
Differentially Private Episodic Reinforcement Learning with Heavy-tailed Rewards
Jun 05, 2023



In this paper, we study the problem of (finite horizon tabular) Markov decision processes (MDPs) with heavy-tailed rewards under the constraint of differential privacy (DP). Compared with the previous studies for private reinforcement learning that typically assume rewards are sampled from some bounded or sub-Gaussian distributions to ensure DP, we consider the setting where reward distributions have only finite $(1+v)$-th moments with some $v \in (0,1]$. By resorting to robust mean estimators for rewards, we first propose two frameworks for heavy-tailed MDPs, i.e., one is for value iteration and another is for policy optimization. Under each framework, we consider both joint differential privacy (JDP) and local differential privacy (LDP) models. Based on our frameworks, we provide regret upper bounds for both JDP and LDP cases and show that the moment of distribution and privacy budget both have significant impacts on regrets. Finally, we establish a lower bound of regret minimization for heavy-tailed MDPs in JDP model by reducing it to the instance-independent lower bound of heavy-tailed multi-armed bandits in DP model. We also show the lower bound for the problem in LDP by adopting some private minimax methods. Our results reveal that there are fundamental differences between the problem of private RL with sub-Gaussian and that with heavy-tailed rewards.
Provably Efficient Model-Free Algorithms for Non-stationary CMDPs
Mar 10, 2023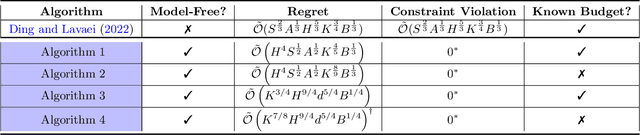

We study model-free reinforcement learning (RL) algorithms in episodic non-stationary constrained Markov Decision Processes (CMDPs), in which an agent aims to maximize the expected cumulative reward subject to a cumulative constraint on the expected utility (cost). In the non-stationary environment, reward, utility functions, and transition kernels can vary arbitrarily over time as long as the cumulative variations do not exceed certain variation budgets. We propose the first model-free, simulator-free RL algorithms with sublinear regret and zero constraint violation for non-stationary CMDPs in both tabular and linear function approximation settings with provable performance guarantees. Our results on regret bound and constraint violation for the tabular case match the corresponding best results for stationary CMDPs when the total budget is known. Additionally, we present a general framework for addressing the well-known challenges associated with analyzing non-stationary CMDPs, without requiring prior knowledge of the variation budget. We apply the approach for both tabular and linear approximation settings.