 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinmei Tian
Robust Training of Federated Models with Extremely Label Deficiency
Feb 22, 2024
Federated semi-supervised learning (FSSL) has emerged as a powerful paradigm for collaboratively training machine learning models using distributed data with label deficiency. Advanced FSSL methods predominantly focus on training a single model on each client. However, this approach could lead to a discrepancy between the objective functions of labeled and unlabeled data, resulting in gradient conflicts. To alleviate gradient conflict, we propose a novel twin-model paradigm, called Twin-sight, designed to enhance mutual guidance by providing insights from different perspectives of labeled and unlabeled data. In particular, Twin-sight concurrently trains a supervised model with a supervised objective function while training an unsupervised model using an unsupervised objective function. To enhance the synergy between these two models, Twin-sight introduces a neighbourhood-preserving constraint, which encourages the preservation of the neighbourhood relationship among data features extracted by both models. Our comprehensive experiments on four benchmark datasets provide substantial evidence that Twin-sight can significantly outperform state-of-the-art methods across various experimental settings, demonstrating the efficacy of the proposed Twin-sight.
Towards Theoretical Understandings of Self-Consuming Generative Models
Feb 19, 2024This paper tackles the emerging challenge of training generative models within a self-consuming loop, wherein successive generations of models are recursively trained on mixtures of real and synthetic data from previous generations. We construct a theoretical framework to rigorously evaluate how this training regimen impacts the data distributions learned by future models. Specifically, we derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution under various mixed training scenarios. Our analysis demonstrates that this distance can be effectively controlled under the condition that mixed training dataset sizes or proportions of real data are large enough. Interestingly, we further unveil a phase transition induced by expanding synthetic data amounts, proving theoretically that while the TV distance exhibits an initial ascent, it declines beyond a threshold point. Finally, we specialize our general results to diffusion models, delivering nuanced insights such as the efficacy of optimal early stopping within the self-consuming loop.
FedImpro: Measuring and Improving Client Update in Federated Learning
Feb 10, 2024Federated Learning (FL) models often experience client drift caused by heterogeneous data, where the distribution of data differs across clients. To address this issue, advanced research primarily focuses on manipulating the existing gradients to achieve more consistent client models. In this paper, we present an alternative perspective on client drift and aim to mitigate it by generating improved local models. First, we analyze the generalization contribution of local training and conclude that this generalization contribution is bounded by the conditional Wasserstein distance between the data distribution of different clients. Then, we propose FedImpro, to construct similar conditional distributions for local training. Specifically, FedImpro decouples the model into high-level and low-level components, and trains the high-level portion on reconstructed feature distributions. This approach enhances the generalization contribution and reduces the dissimilarity of gradients in FL. Experimental results show that FedImpro can help FL defend against data heterogeneity and enhance the generalization performance of the model.
Good Questions Help Zero-Shot Image Reasoning
Dec 04, 2023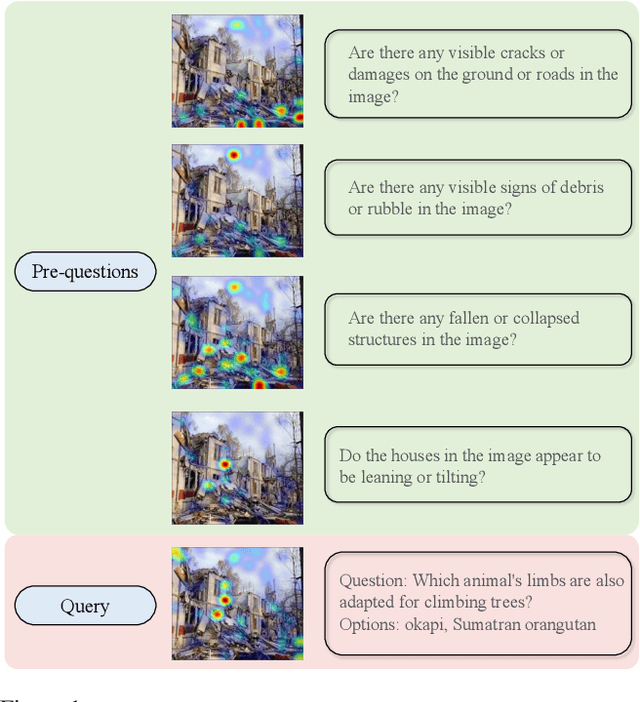
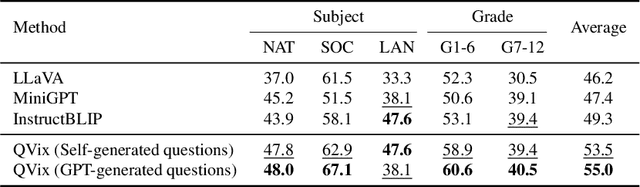
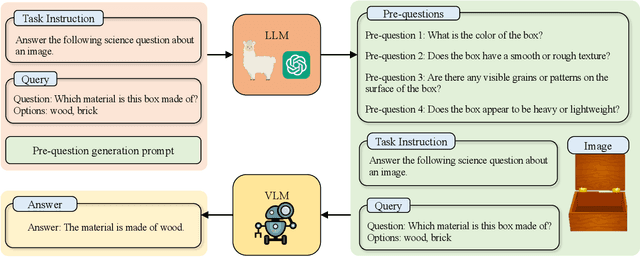
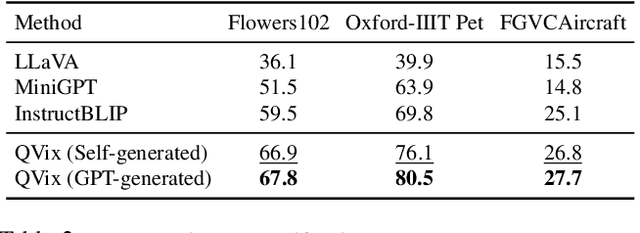
Aligning the recent large language models (LLMs) with computer vision models leads to large vision-language models (LVLMs), which have paved the way for zero-shot image reasoning tasks. However, LVLMs are usually trained on short high-level captions only referring to sparse focus regions in images. Such a ``tunnel vision'' limits LVLMs to exploring other relevant contexts in complex scenes. To address this challenge, we introduce Question-Driven Visual Exploration (QVix), a novel prompting strategy that enhances the exploratory capabilities of LVLMs in zero-shot reasoning tasks. QVix leverages LLMs' strong language prior to generate input-exploratory questions with more details than the original query, guiding LVLMs to explore visual content more comprehensively and uncover subtle or peripheral details. QVix enables a wider exploration of visual scenes, improving the LVLMs' reasoning accuracy and depth in tasks such as visual question answering and visual entailment. Our evaluations on various challenging zero-shot vision-language benchmarks, including ScienceQA and fine-grained visual classification, demonstrate that QVix significantly outperforms existing methods, highlighting its effectiveness in bridging the gap between complex visual data and LVLMs' exploratory abilities.
Optical Quantum Sensing for Agnostic Environments via Deep Learning
Nov 13, 2023Optical quantum sensing promises measurement precision beyond classical sensors termed the Heisenberg limit (HL). However, conventional methodologies often rely on prior knowledge of the target system to achieve HL, presenting challenges in practical applications. Addressing this limitation, we introduce an innovative Deep Learning-based Quantum Sensing scheme (DQS), enabling optical quantum sensors to attain HL in agnostic environments. DQS incorporates two essential components: a Graph Neural Network (GNN) predictor and a trigonometric interpolation algorithm. Operating within a data-driven paradigm, DQS utilizes the GNN predictor, trained on offline data, to unveil the intrinsic relationships between the optical setups employed in preparing the probe state and the resulting quantum Fisher information (QFI) after interaction with the agnostic environment. This distilled knowledge facilitates the identification of optimal optical setups associated with maximal QFI. Subsequently, DQS employs a trigonometric interpolation algorithm to recover the unknown parameter estimates for the identified optical setups. Extensive experiments are conducted to investigate the performance of DQS under different settings up to eight photons. Our findings not only offer a new lens through which to accelerate optical quantum sensing tasks but also catalyze future research integrating deep learning and quantum mechanics.
FedFed: Feature Distillation against Data Heterogeneity in Federated Learning
Oct 08, 2023
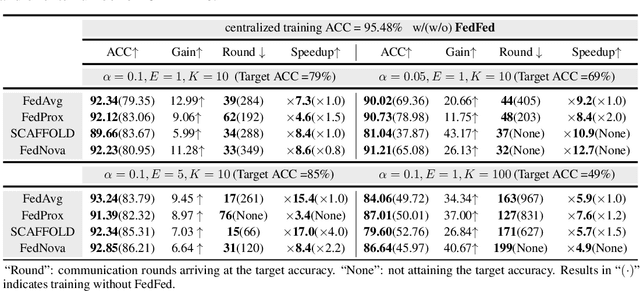

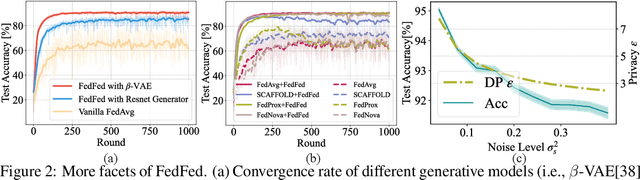
Federated learning (FL) typically faces data heterogeneity, i.e., distribution shifting among clients. Sharing clients' information has shown great potentiality in mitigating data heterogeneity, yet incurs a dilemma in preserving privacy and promoting model performance. To alleviate the dilemma, we raise a fundamental question: \textit{Is it possible to share partial features in the data to tackle data heterogeneity?} In this work, we give an affirmative answer to this question by proposing a novel approach called {\textbf{Fed}erated \textbf{Fe}ature \textbf{d}istillation} (FedFed). Specifically, FedFed partitions data into performance-sensitive features (i.e., greatly contributing to model performance) and performance-robust features (i.e., limitedly contributing to model performance). The performance-sensitive features are globally shared to mitigate data heterogeneity, while the performance-robust features are kept locally. FedFed enables clients to train models over local and shared data. Comprehensive experiments demonstrate the efficacy of FedFed in promoting model performance.
* 32 pages
Boosting Fair Classifier Generalization through Adaptive Priority Reweighing
Sep 30, 2023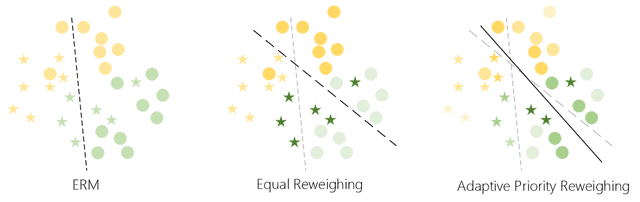
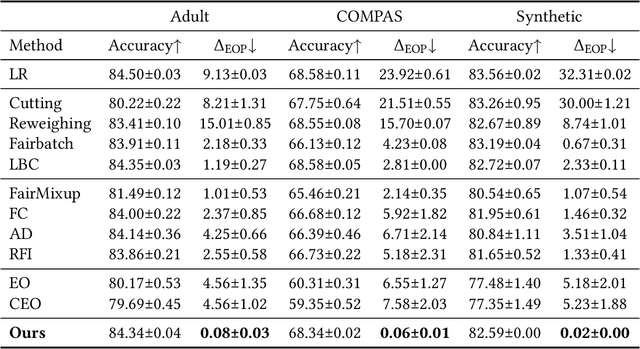
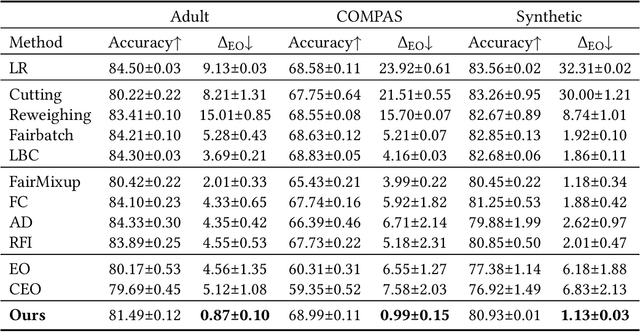
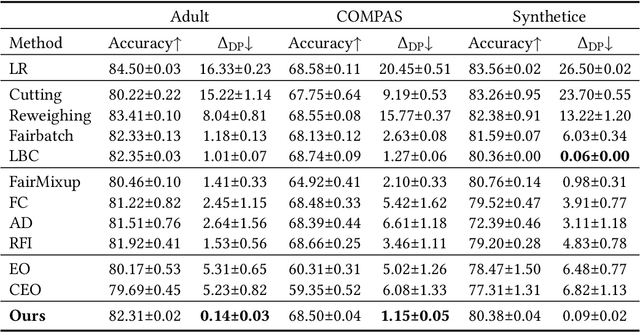
With the increasing penetration of machine learning applications in critical decision-making areas, calls for algorithmic fairness are more prominent. Although there have been various modalities to improve algorithmic fairness through learning with fairness constraints, their performance does not generalize well in the test set. A performance-promising fair algorithm with better generalizability is needed. This paper proposes a novel adaptive reweighing method to eliminate the impact of the distribution shifts between training and test data on model generalizability. Most previous reweighing methods propose to assign a unified weight for each (sub)group. Rather, our method granularly models the distance from the sample predictions to the decision boundary. Our adaptive reweighing method prioritizes samples closer to the decision boundary and assigns a higher weight to improve the generalizability of fair classifiers. Extensive experiments are performed to validate the generalizability of our adaptive priority reweighing method for accuracy and fairness measures (i.e., equal opportunity, equalized odds, and demographic parity) in tabular benchmarks. We also highlight the performance of our method in improving the fairness of language and vision models. The code is available at https://github.com/che2198/APW.
Adaptive Priority Reweighing for Generalizing Fairness Improvement
Sep 15, 2023With the increasing penetration of machine learning applications in critical decision-making areas, calls for algorithmic fairness are more prominent. Although there have been various modalities to improve algorithmic fairness through learning with fairness constraints, their performance does not generalize well in the test set. A performance-promising fair algorithm with better generalizability is needed. This paper proposes a novel adaptive reweighing method to eliminate the impact of the distribution shifts between training and test data on model generalizability. Most previous reweighing methods propose to assign a unified weight for each (sub)group. Rather, our method granularly models the distance from the sample predictions to the decision boundary. Our adaptive reweighing method prioritizes samples closer to the decision boundary and assigns a higher weight to improve the generalizability of fair classifiers. Extensive experiments are performed to validate the generalizability of our adaptive priority reweighing method for accuracy and fairness measures (i.e., equal opportunity, equalized odds, and demographic parity) in tabular benchmarks. We also highlight the performance of our method in improving the fairness of language and vision models. The code is available at https://github.com/che2198/APW.
Structured Cooperative Learning with Graphical Model Priors
Jun 21, 2023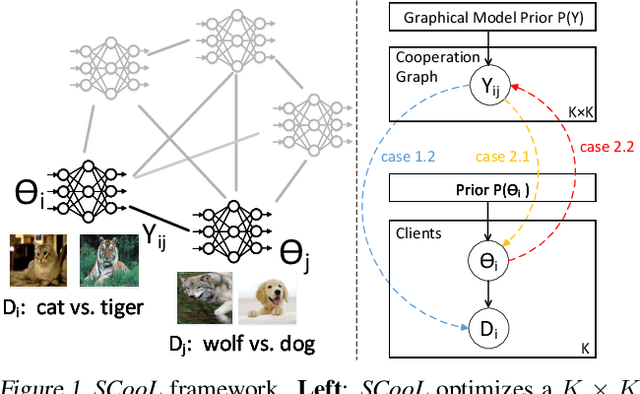
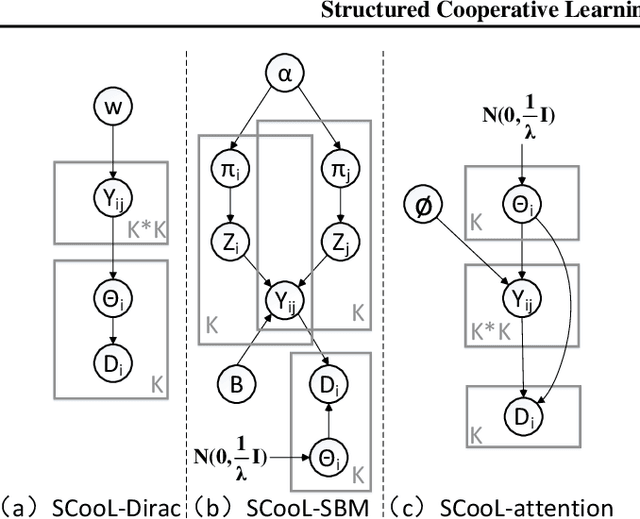
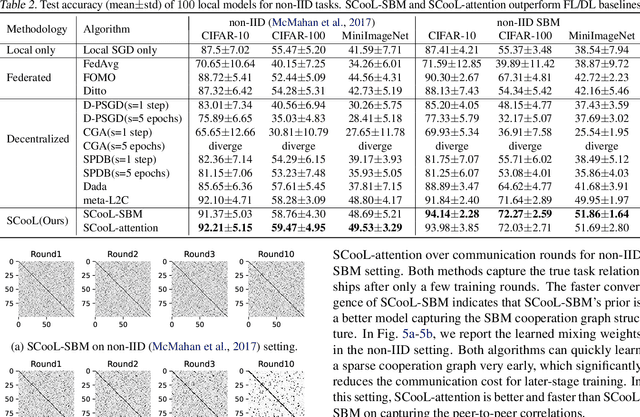
We study how to train personalized models for different tasks on decentralized devices with limited local data. We propose "Structured Cooperative Learning (SCooL)", in which a cooperation graph across devices is generated by a graphical model prior to automatically coordinate mutual learning between devices. By choosing graphical models enforcing different structures, we can derive a rich class of existing and novel decentralized learning algorithms via variational inference. In particular, we show three instantiations of SCooL that adopt Dirac distribution, stochastic block model (SBM), and attention as the prior generating cooperation graphs. These EM-type algorithms alternate between updating the cooperation graph and cooperative learning of local models. They can automatically capture the cross-task correlations among devices by only monitoring their model updating in order to optimize the cooperation graph. We evaluate SCooL and compare it with existing decentralized learning methods on an extensive set of benchmarks, on which SCooL always achieves the highest accuracy of personalized models and significantly outperforms other baselines on communication efficiency. Our code is available at https://github.com/ShuangtongLi/SCooL.