 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinqiang Yu
Exemplar-Free Class Incremental Learning via Incremental Representation
Mar 24, 2024
Exemplar-Free Class Incremental Learning (efCIL) aims to continuously incorporate the knowledge from new classes while retaining previously learned information, without storing any old-class exemplars (i.e., samples). For this purpose, various efCIL methods have been proposed over the past few years, generally with elaborately constructed old pseudo-features, increasing the difficulty of model development and interpretation. In contrast, we propose a \textbf{simple Incremental Representation (IR) framework} for efCIL without constructing old pseudo-features. IR utilizes dataset augmentation to cover a suitable feature space and prevents the model from forgetting by using a single L2 space maintenance loss. We discard the transient classifier trained on each one of the sequence tasks and instead replace it with a 1-near-neighbor classifier for inference, ensuring the representation is incrementally updated during CIL. Extensive experiments demonstrate that our proposed IR achieves comparable performance while significantly preventing the model from forgetting on CIFAR100, TinyImageNet, and ImageNetSubset datasets.
CLIP-KD: An Empirical Study of Distilling CLIP Models
Jul 24, 2023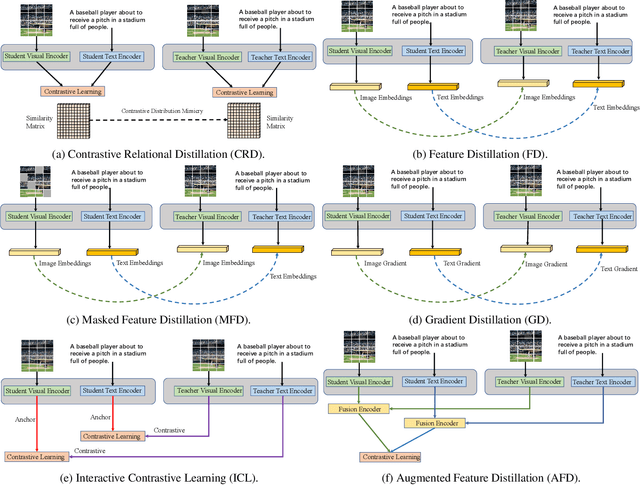

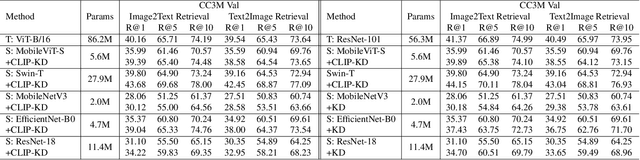
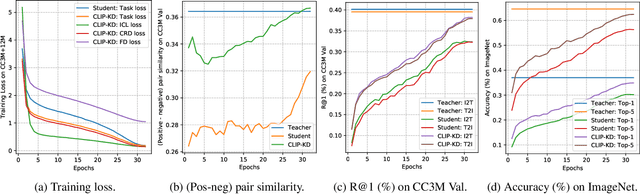
CLIP has become a promising language-supervised visual pre-training framework and achieves excellent performance over a wide range of tasks. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigm, to examine the impact on CLIP distillation. We show that the simplest feature mimicry with MSE loss performs best. Moreover, interactive contrastive learning and relation-based distillation are also critical in performance improvement. We apply the unified method to distill several student networks trained on 15 million (image, text) pairs. Distillation improves the student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. We hope our empirical study will become an important baseline for future CLIP distillation research. The code is available at \url{https://github.com/winycg/CLIP-KD}.
Categories of Response-Based, Feature-Based, and Relation-Based Knowledge Distillation
Jun 19, 2023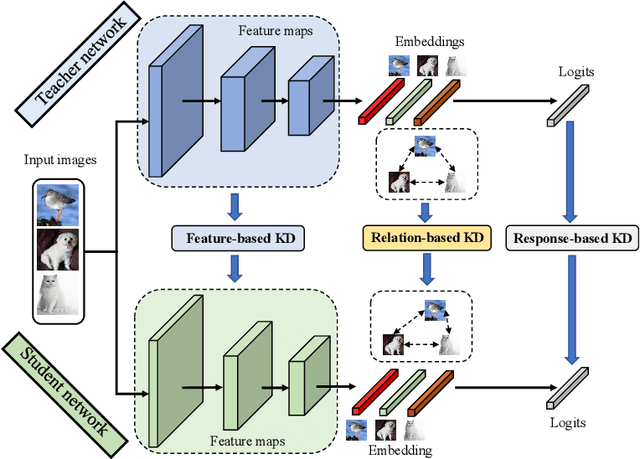
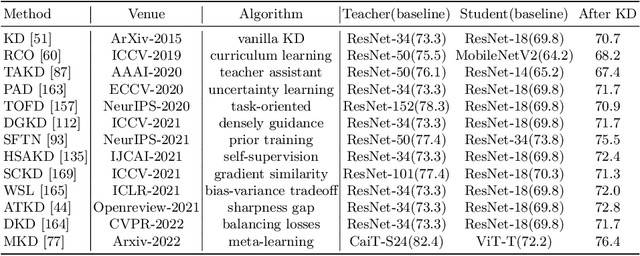
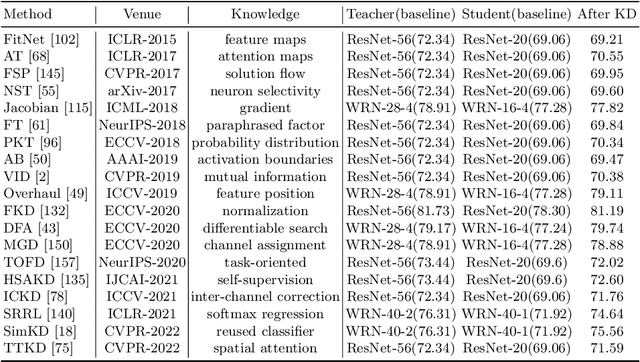

Deep neural networks have achieved remarkable performance for artificial intelligence tasks. The success behind intelligent systems often relies on large-scale models with high computational complexity and storage costs. The over-parameterized networks are often easy to optimize and can achieve better performance. However, it is challenging to deploy them over resource-limited edge-devices. Knowledge Distillation (KD) aims to optimize a lightweight network from the perspective of over-parameterized training. The traditional offline KD transfers knowledge from a cumbersome teacher to a small and fast student network. When a sizeable pre-trained teacher network is unavailable, online KD can improve a group of models by collaborative or mutual learning. Without needing extra models, Self-KD boosts the network itself using attached auxiliary architectures. KD mainly involves knowledge extraction and distillation strategies these two aspects. Beyond KD schemes, various KD algorithms are widely used in practical applications, such as multi-teacher KD, cross-modal KD, attention-based KD, data-free KD and adversarial KD. This paper provides a comprehensive KD survey, including knowledge categories, distillation schemes and algorithms, as well as some empirical studies on performance comparison. Finally, we discuss the open challenges of existing KD works and prospect the future directions.