 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyou Wang
Diffusion Language Models Are Versatile Protein Learners
Feb 28, 2024
This paper introduces diffusion protein language model (DPLM), a versatile protein language model that demonstrates strong generative and predictive capabilities for protein sequences. We first pre-train scalable DPLMs from evolutionary-scale protein sequences within a generative self-supervised discrete diffusion probabilistic framework, which generalizes language modeling for proteins in a principled way. After pre-training, DPLM exhibits the ability to generate structurally plausible, novel, and diverse protein sequences for unconditional generation. We further demonstrate the proposed diffusion generative pre-training makes DPLM possess a better understanding of proteins, making it a superior representation learner, which can be fine-tuned for various predictive tasks, comparing favorably to ESM2 (Lin et al., 2022). Moreover, DPLM can be tailored for various needs, which showcases its prowess of conditional generation in several ways: (1) conditioning on partial peptide sequences, e.g., generating scaffolds for functional motifs with high success rate; (2) incorporating other modalities as conditioner, e.g., structure-conditioned generation for inverse folding; and (3) steering sequence generation towards desired properties, e.g., satisfying specified secondary structures, through a plug-and-play classifier guidance.
Helping the Weak Makes You Strong: Simple Multi-Task Learning Improves Non-Autoregressive Translators
Nov 11, 2022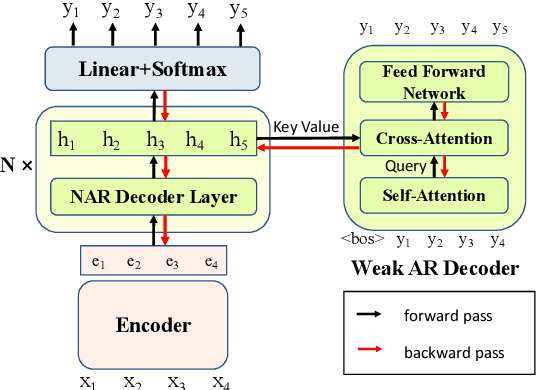
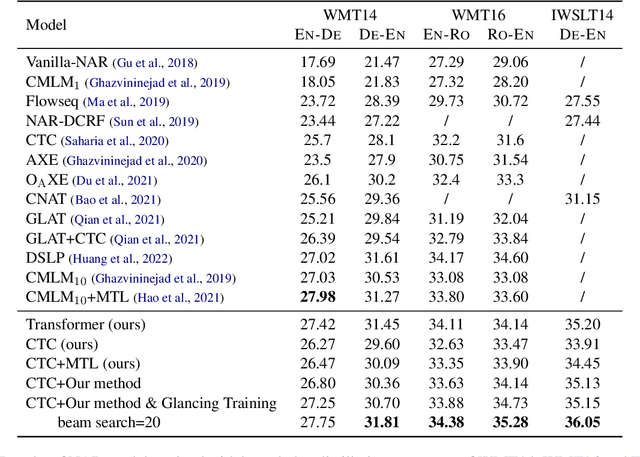
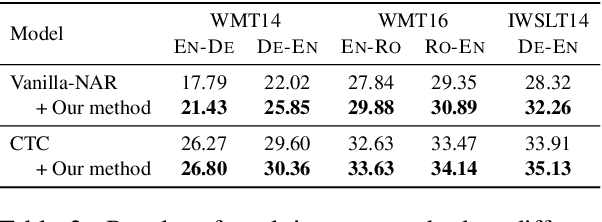
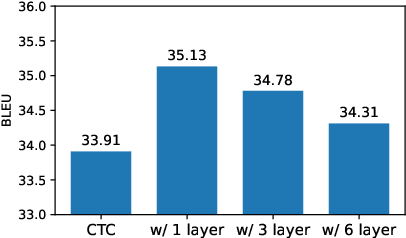
Recently, non-autoregressive (NAR) neural machine translation models have received increasing attention due to their efficient parallel decoding. However, the probabilistic framework of NAR models necessitates conditional independence assumption on target sequences, falling short of characterizing human language data. This drawback results in less informative learning signals for NAR models under conventional MLE training, thereby yielding unsatisfactory accuracy compared to their autoregressive (AR) counterparts. In this paper, we propose a simple and model-agnostic multi-task learning framework to provide more informative learning signals. During training stage, we introduce a set of sufficiently weak AR decoders that solely rely on the information provided by NAR decoder to make prediction, forcing the NAR decoder to become stronger or else it will be unable to support its weak AR partners. Experiments on WMT and IWSLT datasets show that our approach can consistently improve accuracy of multiple NAR baselines without adding any additional decoding overhead.