 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiping Wu
Resource and Mobility Management in Hybrid LiFi and WiFi Networks: A User-Centric Learning Approach
Mar 25, 2024
Hybrid light fidelity (LiFi) and wireless fidelity (WiFi) networks (HLWNets) are an emerging indoor wireless communication paradigm, which combines the advantages of the capacious optical spectra of LiFi and ubiquitous coverage of WiFi. Meanwhile, load balancing (LB) becomes a key challenge in resource management for such hybrid networks. The existing LB methods are mostly network-centric, relying on a central unit to make a solution for the users all at once. Consequently, the solution needs to be updated for all users at the same pace, regardless of their moving status. This would affect the network performance in two aspects: i) when the update frequency is low, it would compromise the connectivity of fast-moving users; ii) when the update frequency is high, it would cause unnecessary handovers as well as hefty feedback costs for slow-moving users. Motivated by this, we investigate user-centric LB which allows users to update their solutions at different paces. The research is developed upon our previous work on adaptive target-condition neural network (ATCNN), which can conduct LB for individual users in quasi-static channels. In this paper, a deep neural network (DNN) model is designed to enable an adaptive update interval for each individual user. This new model is termed as mobility-supporting neural network (MSNN). Associating MSNN with ATCNN, a user-centric LB framework named mobility-supporting ATCNN (MS-ATCNN) is proposed to handle resource management and mobility management simultaneously. Results show that at the same level of average update interval, MS-ATCNN can achieve a network throughput up to 215\% higher than conventional LB methods such as game theory, especially for a larger number of users. In addition, MS-ATCNN costs an ultra low runtime at the level of 100s $\mu$s, which is two to three orders of magnitude lower than game theory.
Adaptive Target-Condition Neural Network: DNN-Aided Load Balancing for Hybrid LiFi and WiFi Networks
Aug 09, 2022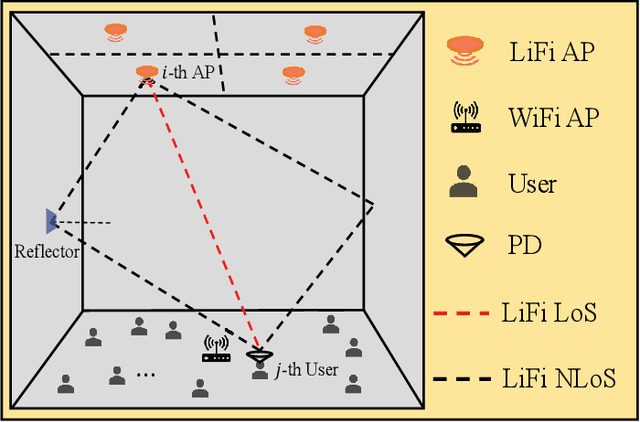



Load balancing (LB) is a challenging issue in the hybrid light fidelity (LiFi) and wireless fidelity (WiFi) networks (HLWNets), due to the nature of heterogeneous access points (APs). Machine learning has the potential to provide a complexity-friendly LB solution with near-optimal network performance, at the cost of a training process. The state-of-the-art (SOTA) learning-aided LB methods, however, need retraining when the network environment (especially the number of users) changes, significantly limiting its practicability. In this paper, a novel deep neural network (DNN) structure named adaptive target-condition neural network (A-TCNN) is proposed, which conducts AP selection for one target user upon the condition of other users. Also, an adaptive mechanism is developed to map a smaller number of users to a larger number through splitting their data rate requirements, without affecting the AP selection result for the target user. This enables the proposed method to handle different numbers of users without the need for retraining. Results show that A-TCNN achieves a network throughput very close to that of the testing dataset, with a gap less than 3%. It is also proven that A-TCNN can obtain a network throughput comparable to two SOTA benchmarks, while reducing the runtime by up to three orders of magnitude.
ATCSpeech: a multilingual pilot-controller speech corpus from real Air Traffic Control environment
Nov 26, 2019
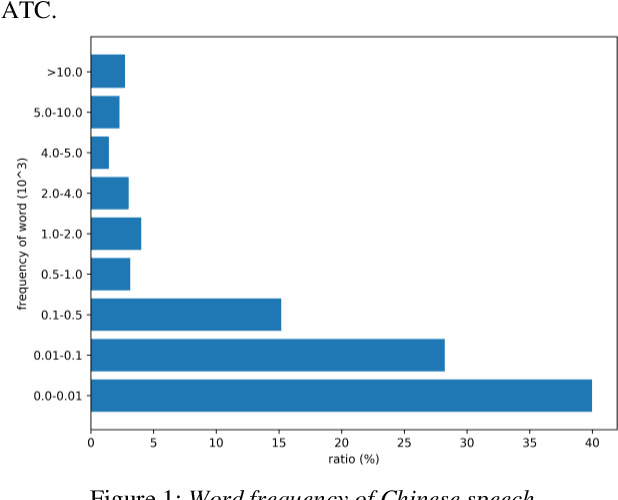
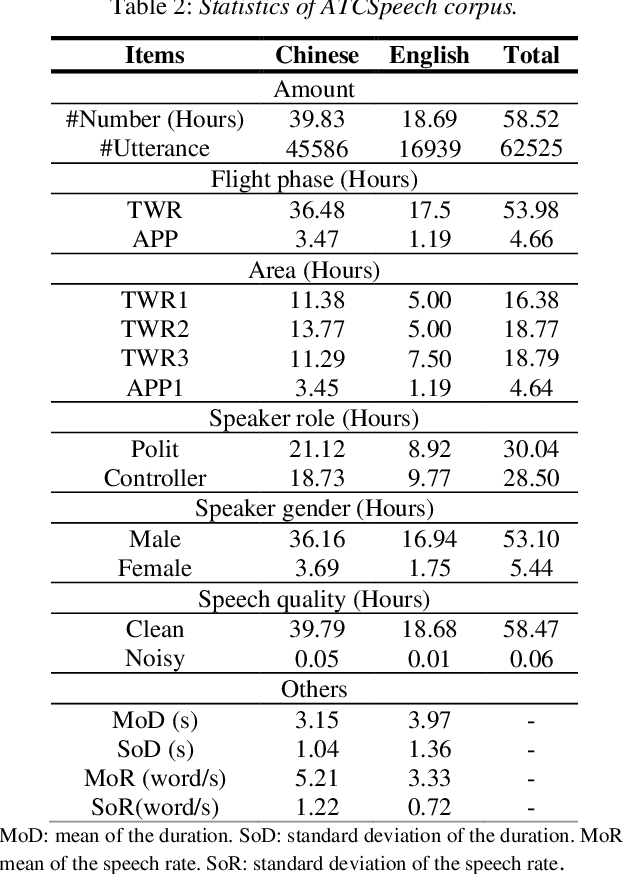
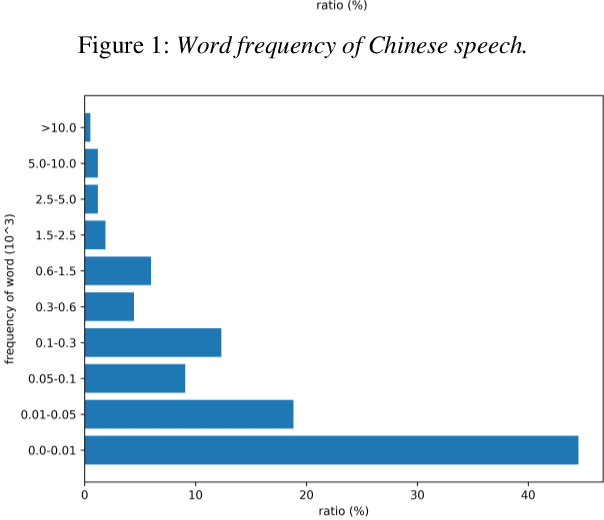
Automatic Speech Recognition (ASR) is greatly developed in recent years, which expedites many applications on other fields. For the ASR research, speech corpus is always an essential foundation, especially for the vertical industry, such as Air Traffic Control (ATC). There are some speech corpora for common applications, public or paid. However, for the ATC, it is difficult to collect raw speeches from real systems due to safety issues. More importantly, for a supervised learning task like ASR, annotating the transcription is a more laborious work, which hugely restricts the prospect of ASR application. In this paper, a multilingual speech corpus (ATCSpeech) from real ATC systems, including accented Mandarin Chinese and English, is built and released to encourage the non-commercial ASR research in ATC domain. The corpus is detailly introduced from the perspective of data amount, speaker gender and role, speech quality and other attributions. In addition, the performance of our baseline ASR models is also reported. A community edition for our speech database can be applied and used under a special contrast. To our best knowledge, this is the first work that aims at building a real and multilingual ASR corpus for the air traffic related research.