 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiuzhuang Zhou
RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection
Mar 09, 2024

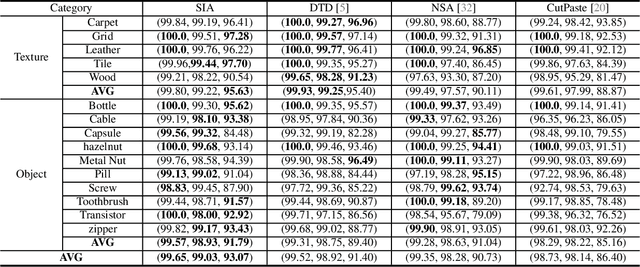


Self-supervised feature reconstruction methods have shown promising advances in industrial image anomaly detection and localization. Despite this progress, these methods still face challenges in synthesizing realistic and diverse anomaly samples, as well as addressing the feature redundancy and pre-training bias of pre-trained feature. In this work, we introduce RealNet, a feature reconstruction network with realistic synthetic anomaly and adaptive feature selection. It is incorporated with three key innovations: First, we propose Strength-controllable Diffusion Anomaly Synthesis (SDAS), a diffusion process-based synthesis strategy capable of generating samples with varying anomaly strengths that mimic the distribution of real anomalous samples. Second, we develop Anomaly-aware Features Selection (AFS), a method for selecting representative and discriminative pre-trained feature subsets to improve anomaly detection performance while controlling computational costs. Third, we introduce Reconstruction Residuals Selection (RRS), a strategy that adaptively selects discriminative residuals for comprehensive identification of anomalous regions across multiple levels of granularity. We assess RealNet on four benchmark datasets, and our results demonstrate significant improvements in both Image AUROC and Pixel AUROC compared to the current state-o-the-art methods. The code, data, and models are available at https://github.com/cnulab/RealNet.
Masked Contrastive Reconstruction for Cross-modal Medical Image-Report Retrieval
Dec 27, 2023Cross-modal medical image-report retrieval task plays a significant role in clinical diagnosis and various medical generative tasks. Eliminating heterogeneity between different modalities to enhance semantic consistency is the key challenge of this task. The current Vision-Language Pretraining (VLP) models, with cross-modal contrastive learning and masked reconstruction as joint training tasks, can effectively enhance the performance of cross-modal retrieval. This framework typically employs dual-stream inputs, using unmasked data for cross-modal contrastive learning and masked data for reconstruction. However, due to task competition and information interference caused by significant differences between the inputs of the two proxy tasks, the effectiveness of representation learning for intra-modal and cross-modal features is limited. In this paper, we propose an efficient VLP framework named Masked Contrastive and Reconstruction (MCR), which takes masked data as the sole input for both tasks. This enhances task connections, reducing information interference and competition between them, while also substantially decreasing the required GPU memory and training time. Moreover, we introduce a new modality alignment strategy named Mapping before Aggregation (MbA). Unlike previous methods, MbA maps different modalities to a common feature space before conducting local feature aggregation, thereby reducing the loss of fine-grained semantic information necessary for improved modality alignment. Qualitative and quantitative experiments conducted on the MIMIC-CXR dataset validate the effectiveness of our approach, demonstrating state-of-the-art performance in medical cross-modal retrieval tasks.
Weakly Supervised Anomaly Detection for Chest X-Ray Image
Nov 18, 2023Chest X-Ray (CXR) examination is a common method for assessing thoracic diseases in clinical applications. While recent advances in deep learning have enhanced the significance of visual analysis for CXR anomaly detection, current methods often miss key cues in anomaly images crucial for identifying disease regions, as they predominantly rely on unsupervised training with normal images. This letter focuses on a more practical setup in which few-shot anomaly images with only image-level labels are available during training. For this purpose, we propose WSCXR, a weakly supervised anomaly detection framework for CXR. WSCXR firstly constructs sets of normal and anomaly image features respectively. It then refines the anomaly image features by eliminating normal region features through anomaly feature mining, thus fully leveraging the scarce yet crucial features of diseased areas. Additionally, WSCXR employs a linear mixing strategy to augment the anomaly features, facilitating the training of anomaly detector with few-shot anomaly images. Experiments on two CXR datasets demonstrate the effectiveness of our approach.
Confidence-Calibrated Face and Kinship Verification
Oct 25, 2022



In this paper, we investigate the problem of predictive confidence in face and kinship verification. Most existing face and kinship verification methods focus on accuracy performance while ignoring confidence estimation for their prediction results. However, confidence estimation is essential for modeling reliability in such high-risk tasks. To address this issue, we first introduce a novel yet simple confidence measure for face and kinship verification, which allows the verification models to transform the similarity score into a confidence score for a given face pair. We further propose a confidence-calibrated approach called angular scaling calibration (ASC). ASC is easy to implement and can be directly applied to existing face and kinship verification models without model modifications, yielding accuracy-preserving and confidence-calibrated probabilistic verification models. To the best of our knowledge, our approach is the first general confidence-calibrated solution to face and kinship verification in a modern context. We conduct extensive experiments on four widely used face and kinship verification datasets, and the results demonstrate the effectiveness of our approach.