 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXu-Yao Zhang
Unified Entropy Optimization for Open-Set Test-Time Adaptation
Apr 09, 2024
Test-time adaptation (TTA) aims at adapting a model pre-trained on the labeled source domain to the unlabeled target domain. Existing methods usually focus on improving TTA performance under covariate shifts, while neglecting semantic shifts. In this paper, we delve into a realistic open-set TTA setting where the target domain may contain samples from unknown classes. Many state-of-the-art closed-set TTA methods perform poorly when applied to open-set scenarios, which can be attributed to the inaccurate estimation of data distribution and model confidence. To address these issues, we propose a simple but effective framework called unified entropy optimization (UniEnt), which is capable of simultaneously adapting to covariate-shifted in-distribution (csID) data and detecting covariate-shifted out-of-distribution (csOOD) data. Specifically, UniEnt first mines pseudo-csID and pseudo-csOOD samples from test data, followed by entropy minimization on the pseudo-csID data and entropy maximization on the pseudo-csOOD data. Furthermore, we introduce UniEnt+ to alleviate the noise caused by hard data partition leveraging sample-level confidence. Extensive experiments on CIFAR benchmarks and Tiny-ImageNet-C show the superiority of our framework. The code is available at https://github.com/gaozhengqing/UniEnt
Open-world Machine Learning: A Review and New Outlooks
Mar 15, 2024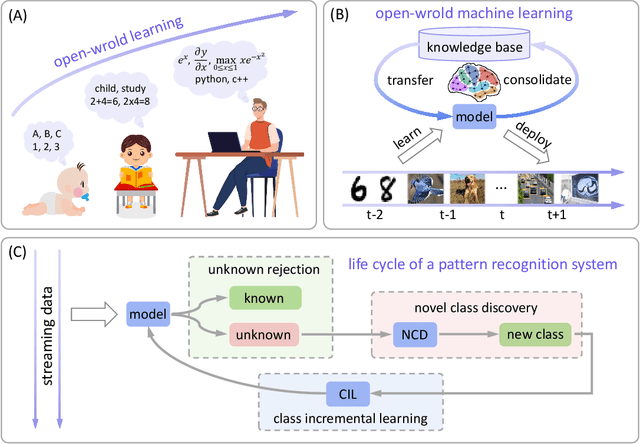
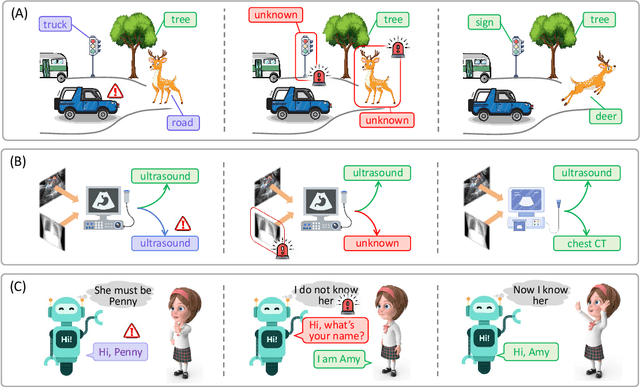
Machine learning has achieved remarkable success in many applications. However, existing studies are largely based on the closed-world assumption, which assumes that the environment is stationary, and the model is fixed once deployed. In many real-world applications, this fundamental and rather naive assumption may not hold because an open environment is complex, dynamic, and full of unknowns. In such cases, rejecting unknowns, discovering novelties, and then incrementally learning them, could enable models to be safe and evolve continually as biological systems do. This paper provides a holistic view of open-world machine learning by investigating unknown rejection, novel class discovery, and class-incremental learning in a unified paradigm. The challenges, principles, and limitations of current methodologies are discussed in detail. Finally, we discuss several potential directions for future research. This paper aims to provide a comprehensive introduction to the emerging open-world machine learning paradigm, to help researchers build more powerful AI systems in their respective fields, and to promote the development of artificial general intelligence.
Ensemble Quadratic Assignment Network for Graph Matching
Mar 11, 2024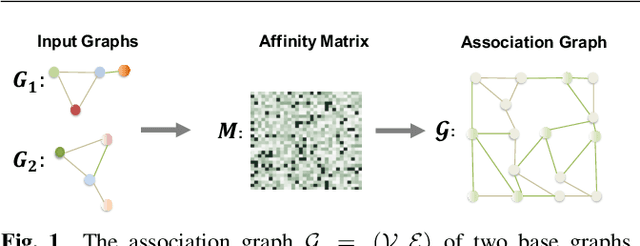

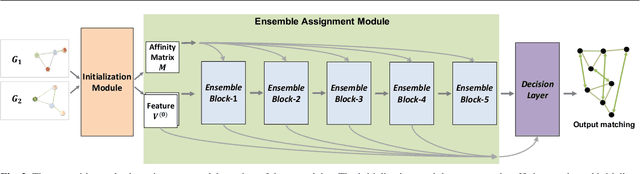
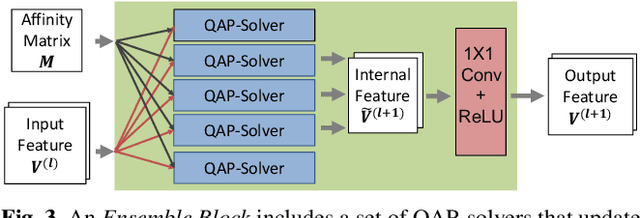
Graph matching is a commonly used technique in computer vision and pattern recognition. Recent data-driven approaches have improved the graph matching accuracy remarkably, whereas some traditional algorithm-based methods are more robust to feature noises, outlier nodes, and global transformation (e.g.~rotation). In this paper, we propose a graph neural network (GNN) based approach to combine the advantages of data-driven and traditional methods. In the GNN framework, we transform traditional graph-matching solvers as single-channel GNNs on the association graph and extend the single-channel architecture to the multi-channel network. The proposed model can be seen as an ensemble method that fuses multiple algorithms at every iteration. Instead of averaging the estimates at the end of the ensemble, in our approach, the independent iterations of the ensembled algorithms exchange their information after each iteration via a 1x1 channel-wise convolution layer. Experiments show that our model improves the performance of traditional algorithms significantly. In addition, we propose a random sampling strategy to reduce the computational complexity and GPU memory usage, so the model applies to matching graphs with thousands of nodes. We evaluate the performance of our method on three tasks: geometric graph matching, semantic feature matching, and few-shot 3D shape classification. The proposed model performs comparably or outperforms the best existing GNN-based methods.
Active Generalized Category Discovery
Mar 07, 2024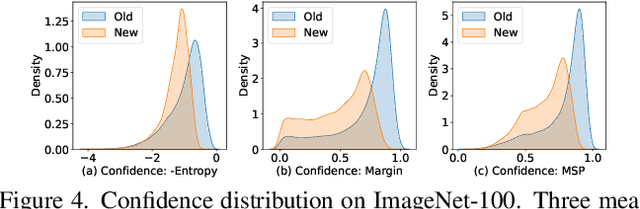
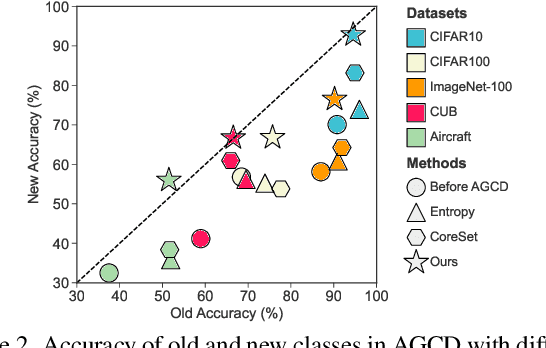
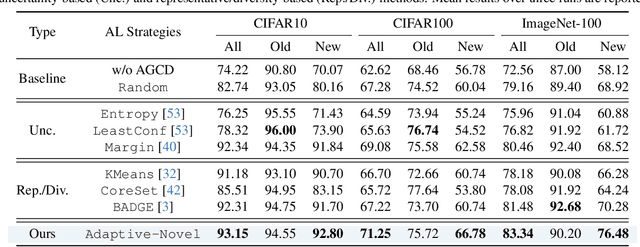
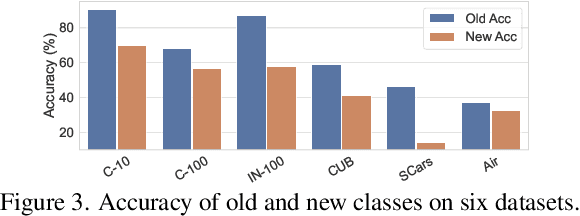
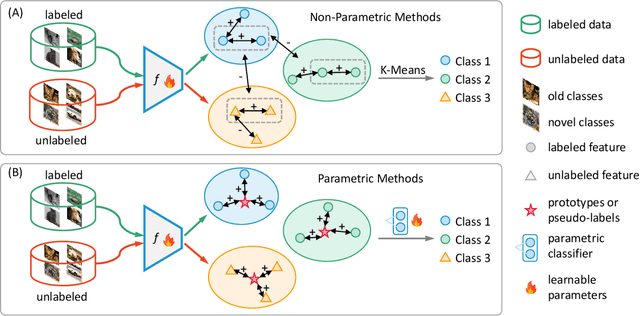
Generalized Category Discovery (GCD) is a pragmatic and challenging open-world task, which endeavors to cluster unlabeled samples from both novel and old classes, leveraging some labeled data of old classes. Given that knowledge learned from old classes is not fully transferable to new classes, and that novel categories are fully unlabeled, GCD inherently faces intractable problems, including imbalanced classification performance and inconsistent confidence between old and new classes, especially in the low-labeling regime. Hence, some annotations of new classes are deemed necessary. However, labeling new classes is extremely costly. To address this issue, we take the spirit of active learning and propose a new setting called Active Generalized Category Discovery (AGCD). The goal is to improve the performance of GCD by actively selecting a limited amount of valuable samples for labeling from the oracle. To solve this problem, we devise an adaptive sampling strategy, which jointly considers novelty, informativeness and diversity to adaptively select novel samples with proper uncertainty. However, owing to the varied orderings of label indices caused by the clustering of novel classes, the queried labels are not directly applicable to subsequent training. To overcome this issue, we further propose a stable label mapping algorithm that transforms ground truth labels to the label space of the classifier, thereby ensuring consistent training across different active selection stages. Our method achieves state-of-the-art performance on both generic and fine-grained datasets. Our code is available at https://github.com/mashijie1028/ActiveGCD
Revisiting Confidence Estimation: Towards Reliable Failure Prediction
Mar 05, 2024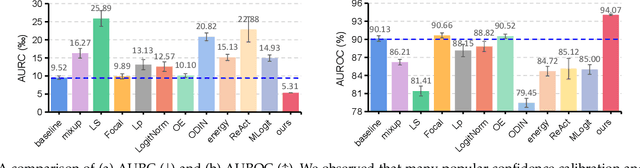
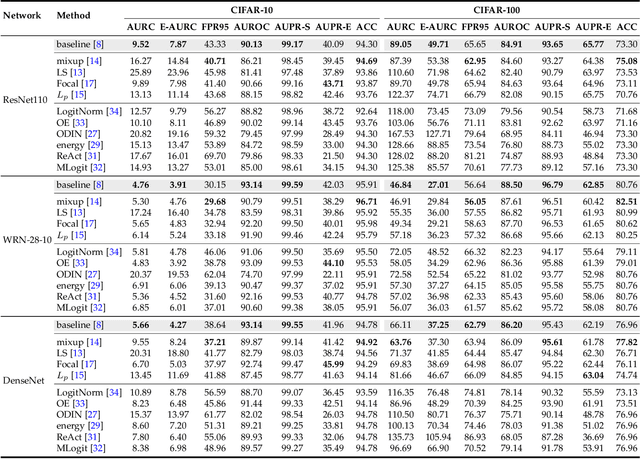
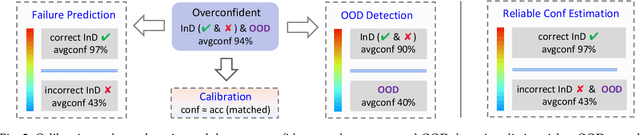
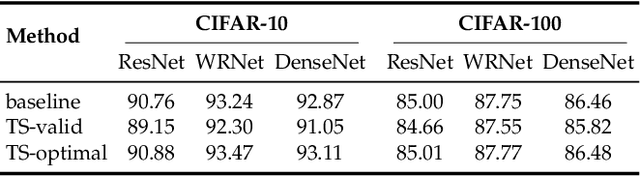
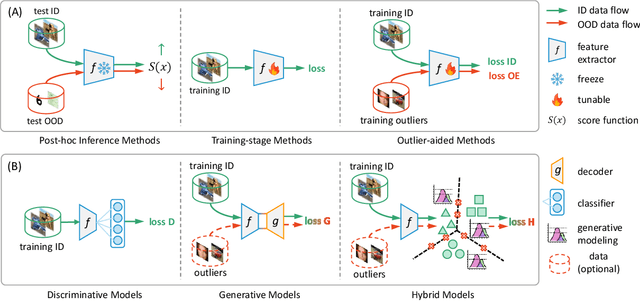
Reliable confidence estimation is a challenging yet fundamental requirement in many risk-sensitive applications. However, modern deep neural networks are often overconfident for their incorrect predictions, i.e., misclassified samples from known classes, and out-of-distribution (OOD) samples from unknown classes. In recent years, many confidence calibration and OOD detection methods have been developed. In this paper, we find a general, widely existing but actually-neglected phenomenon that most confidence estimation methods are harmful for detecting misclassification errors. We investigate this problem and reveal that popular calibration and OOD detection methods often lead to worse confidence separation between correctly classified and misclassified examples, making it difficult to decide whether to trust a prediction or not. Finally, we propose to enlarge the confidence gap by finding flat minima, which yields state-of-the-art failure prediction performance under various settings including balanced, long-tailed, and covariate-shift classification scenarios. Our study not only provides a strong baseline for reliable confidence estimation but also acts as a bridge between understanding calibration, OOD detection, and failure prediction. The code is available at \url{https://github.com/Impression2805/FMFP}.
Federated Class-Incremental Learning with Prototype Guided Transformer
Jan 04, 2024Existing federated learning methods have effectively addressed decentralized learning in scenarios involving data privacy and non-IID data. However, in real-world situations, each client dynamically learns new classes, requiring the global model to maintain discriminative capabilities for both new and old classes. To effectively mitigate the effects of catastrophic forgetting and data heterogeneity under low communication costs, we designed a simple and effective method named PLoRA. On the one hand, we adopt prototype learning to learn better feature representations and leverage the heuristic information between prototypes and class features to design a prototype re-weight module to solve the classifier bias caused by data heterogeneity without retraining the classification layer. On the other hand, our approach utilizes a pre-trained model as the backbone and utilizes LoRA to fine-tune with a tiny amount of parameters when learning new classes. Moreover, PLoRA does not rely on similarity-based module selection strategies, thereby further reducing communication overhead. Experimental results on standard datasets indicate that our method outperforms the state-of-the-art approaches significantly. More importantly, our method exhibits strong robustness and superiority in various scenarios and degrees of data heterogeneity. Our code will be publicly available.
Unified Classification and Rejection: A One-versus-All Framework
Nov 22, 2023Classifying patterns of known classes and rejecting ambiguous and novel (also called as out-of-distribution (OOD)) inputs are involved in open world pattern recognition. Deep neural network models usually excel in closed-set classification while performing poorly in rejecting OOD. To tackle this problem, numerous methods have been designed to perform open set recognition (OSR) or OOD rejection/detection tasks. Previous methods mostly take post-training score transformation or hybrid models to ensure low scores on OOD inputs while separating known classes. In this paper, we attempt to build a unified framework for building open set classifiers for both classification and OOD rejection. We formulate the open set recognition of $ K $-known-class as a $ (K + 1) $-class classification problem with model trained on known-class samples only. By decomposing the $ K $-class problem into $ K $ one-versus-all (OVA) binary classification tasks and binding some parameters, we show that combining the scores of OVA classifiers can give $ (K + 1) $-class posterior probabilities, which enables classification and OOD rejection in a unified framework. To maintain the closed-set classification accuracy of the OVA trained classifier, we propose a hybrid training strategy combining OVA loss and multi-class cross-entropy loss. We implement the OVA framework and hybrid training strategy on the recently proposed convolutional prototype network. Experiments on popular OSR and OOD detection datasets demonstrate that the proposed framework, using a single multi-class classifier, yields competitive performance in closed-set classification, OOD detection, and misclassification detection.
Towards Reliable Domain Generalization: A New Dataset and Evaluations
Sep 12, 2023

There are ubiquitous distribution shifts in the real world. However, deep neural networks (DNNs) are easily biased towards the training set, which causes severe performance degradation when they receive out-of-distribution data. Many methods are studied to train models that generalize under various distribution shifts in the literature of domain generalization (DG). However, the recent DomainBed and WILDS benchmarks challenged the effectiveness of these methods. Aiming at the problems in the existing research, we propose a new domain generalization task for handwritten Chinese character recognition (HCCR) to enrich the application scenarios of DG method research. We evaluate eighteen DG methods on the proposed PaHCC (Printed and Handwritten Chinese Characters) dataset and show that the performance of existing methods on this dataset is still unsatisfactory. Besides, under a designed dynamic DG setting, we reveal more properties of DG methods and argue that only the leave-one-domain-out protocol is unreliable. We advocate that researchers in the DG community refer to dynamic performance of methods for more comprehensive and reliable evaluation. Our dataset and evaluations bring new perspectives to the community for more substantial progress. We will make our dataset public with the article published to facilitate the study of domain generalization.
Towards Trustworthy Dataset Distillation
Jul 18, 2023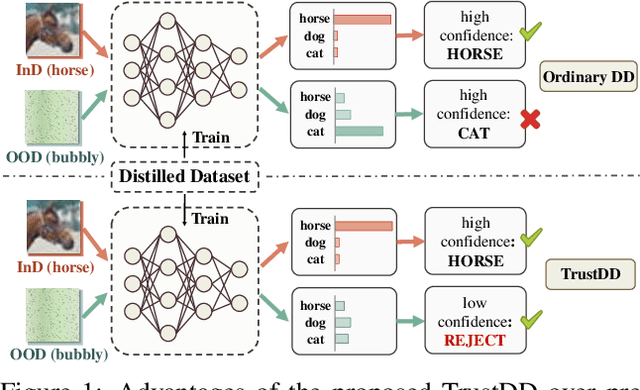
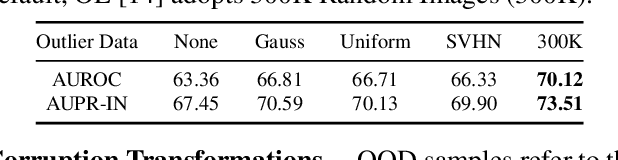
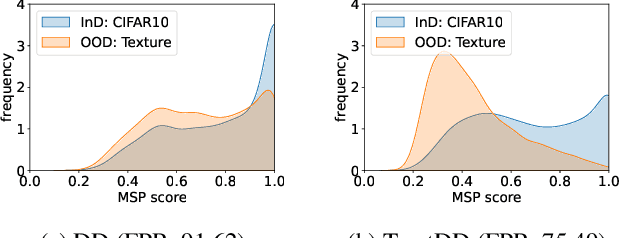

Efficiency and trustworthiness are two eternal pursuits when applying deep learning in real-world applications. With regard to efficiency, dataset distillation (DD) endeavors to reduce training costs by distilling the large dataset into a tiny synthetic dataset. However, existing methods merely concentrate on in-distribution (InD) classification in a closed-world setting, disregarding out-of-distribution (OOD) samples. On the other hand, OOD detection aims to enhance models' trustworthiness, which is always inefficiently achieved in full-data settings. For the first time, we simultaneously consider both issues and propose a novel paradigm called Trustworthy Dataset Distillation (TrustDD). By distilling both InD samples and outliers, the condensed datasets are capable to train models competent in both InD classification and OOD detection. To alleviate the requirement of real outlier data and make OOD detection more practical, we further propose to corrupt InD samples to generate pseudo-outliers and introduce Pseudo-Outlier Exposure (POE). Comprehensive experiments on various settings demonstrate the effectiveness of TrustDD, and the proposed POE surpasses state-of-the-art method Outlier Exposure (OE). Compared with the preceding DD, TrustDD is more trustworthy and applicable to real open-world scenarios. Our code will be publicly available.
OpenMix: Exploring Outlier Samples for Misclassification Detection
Mar 30, 2023

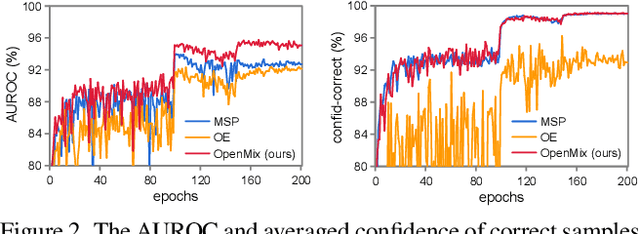
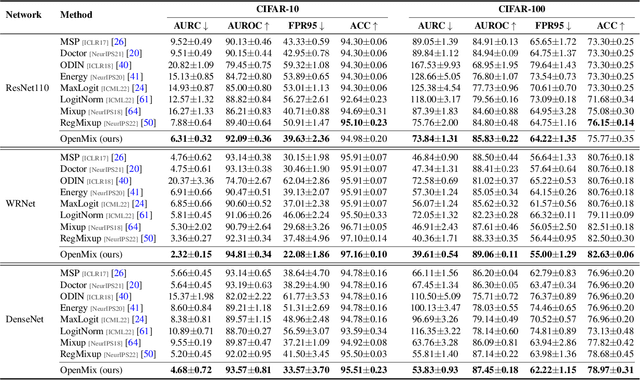
Reliable confidence estimation for deep neural classifiers is a challenging yet fundamental requirement in high-stakes applications. Unfortunately, modern deep neural networks are often overconfident for their erroneous predictions. In this work, we exploit the easily available outlier samples, i.e., unlabeled samples coming from non-target classes, for helping detect misclassification errors. Particularly, we find that the well-known Outlier Exposure, which is powerful in detecting out-of-distribution (OOD) samples from unknown classes, does not provide any gain in identifying misclassification errors. Based on these observations, we propose a novel method called OpenMix, which incorporates open-world knowledge by learning to reject uncertain pseudo-samples generated via outlier transformation. OpenMix significantly improves confidence reliability under various scenarios, establishing a strong and unified framework for detecting both misclassified samples from known classes and OOD samples from unknown classes. The code is publicly available at https://github.com/Impression2805/OpenMix.