 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuewu Lin
EDA: Evolving and Distinct Anchors for Multimodal Motion Prediction
Dec 15, 2023
Motion prediction is a crucial task in autonomous driving, and one of its major challenges lands in the multimodality of future behaviors. Many successful works have utilized mixture models which require identification of positive mixture components, and correspondingly fall into two main lines: prediction-based and anchor-based matching. The prediction clustering phenomenon in prediction-based matching makes it difficult to pick representative trajectories for downstream tasks, while the anchor-based matching suffers from a limited regression capability. In this paper, we introduce a novel paradigm, named Evolving and Distinct Anchors (EDA), to define the positive and negative components for multimodal motion prediction based on mixture models. We enable anchors to evolve and redistribute themselves under specific scenes for an enlarged regression capacity. Furthermore, we select distinct anchors before matching them with the ground truth, which results in impressive scoring performance. Our approach enhances all metrics compared to the baseline MTR, particularly with a notable relative reduction of 13.5% in Miss Rate, resulting in state-of-the-art performance on the Waymo Open Motion Dataset. Code is available at https://github.com/Longzhong-Lin/EDA.
Sparse4D v3: Advancing End-to-End 3D Detection and Tracking
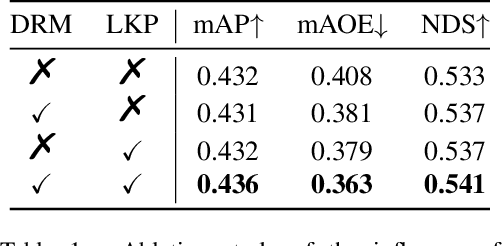
Nov 20, 2023In autonomous driving perception systems, 3D detection and tracking are the two fundamental tasks. This paper delves deeper into this field, building upon the Sparse4D framework. We introduce two auxiliary training tasks (Temporal Instance Denoising and Quality Estimation) and propose decoupled attention to make structural improvements, leading to significant enhancements in detection performance. Additionally, we extend the detector into a tracker using a straightforward approach that assigns instance ID during inference, further highlighting the advantages of query-based algorithms. Extensive experiments conducted on the nuScenes benchmark validate the effectiveness of the proposed improvements. With ResNet50 as the backbone, we witnessed enhancements of 3.0\%, 2.2\%, and 7.6\% in mAP, NDS, and AMOTA, achieving 46.9\%, 56.1\%, and 49.0\%, respectively. Our best model achieved 71.9\% NDS and 67.7\% AMOTA on the nuScenes test set. Code will be released at \url{https://github.com/linxuewu/Sparse4D}.
Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
May 24, 2023

Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.
Sparse4D: Multi-view 3D Object Detection with Sparse Spatial-Temporal Fusion
Nov 19, 2022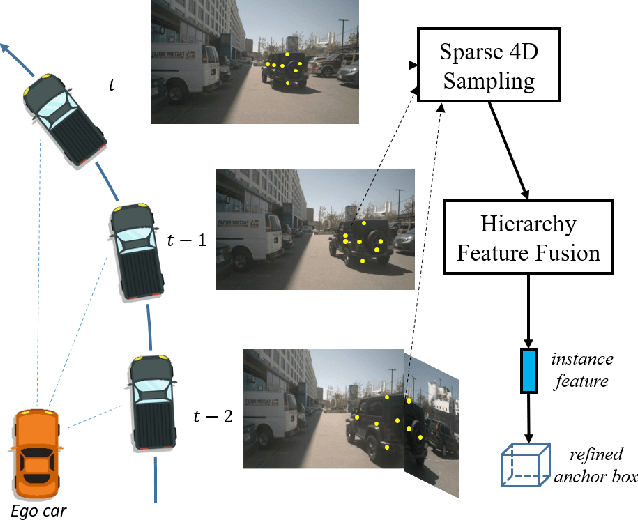
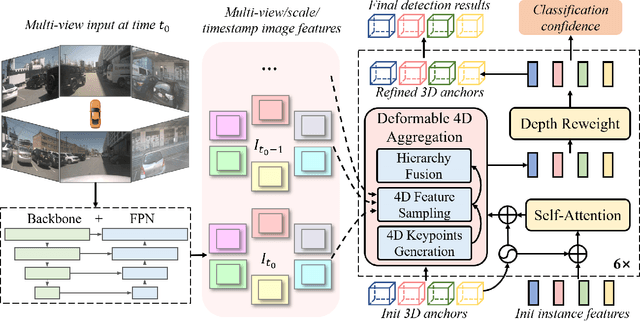

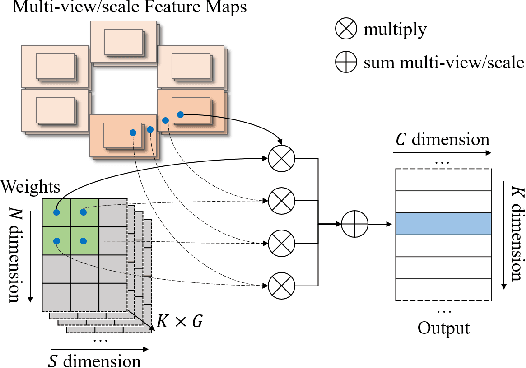
Bird-eye-view (BEV) based methods have made great progress recently in multi-view 3D detection task. Comparing with BEV based methods, sparse based methods lag behind in performance, but still have lots of non-negligible merits. To push sparse 3D detection further, in this work, we introduce a novel method, named Sparse4D, which does the iterative refinement of anchor boxes via sparsely sampling and fusing spatial-temporal features. (1) Sparse 4D Sampling: for each 3D anchor, we assign multiple 4D keypoints, which are then projected to multi-view/scale/timestamp image features to sample corresponding features; (2) Hierarchy Feature Fusion: we hierarchically fuse sampled features of different view/scale, different timestamp and different keypoints to generate high-quality instance feature. In this way, Sparse4D can efficiently and effectively achieve 3D detection without relying on dense view transformation nor global attention, and is more friendly to edge devices deployment. Furthermore, we introduce an instance-level depth reweight module to alleviate the ill-posed issue in 3D-to-2D projection. In experiment, our method outperforms all sparse based methods and most BEV based methods on detection task in the nuScenes dataset.
Global Correlation Network: End-to-End Joint Multi-Object Detection and Tracking
Apr 10, 2021



Multi-object tracking (MOT) has made great progress in recent years, but there are still some problems. Most MOT algorithms follow tracking-by-detection framework, which separates detection and tracking into two independent parts. Early tracking-by-detection algorithms need to do two feature extractions for detection and tracking. Recently, some algorithms make the feature extraction into one network, but the tracking part still relies on data association and needs complex post-processing for life cycle management. Those methods do not combine detection and tracking well. In this paper, we present a novel network to realize joint multi-object detection and tracking in an end-to-end way, called Global Correlation Network (GCNet). Different from most object detection methods, GCNet introduces the global correlation layer for regression of absolute size and coordinates of bounding boxes instead of offsets prediction. The pipeline of detection and tracking by GCNet is conceptually simple, which does not need non-maximum suppression, data association, and other complicated tracking strategies. GCNet was evaluated on a multi-vehicle tracking dataset, UA-DETRAC, and demonstrates promising performance compared to the state-of-the-art detectors and trackers.