 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXun Wu
Enhancing Uncertain Demand Prediction in Hospitals Using Simple and Advanced Machine Learning
Apr 29, 2024
Early and timely prediction of patient care demand not only affects effective resource allocation but also influences clinical decision-making as well as patient experience. Accurately predicting patient care demand, however, is a ubiquitous challenge for hospitals across the world due, in part, to the demand's time-varying temporal variability, and, in part, to the difficulty in modelling trends in advance. To address this issue, here, we develop two methods, a relatively simple time-vary linear model, and a more advanced neural network model. The former forecasts patient arrivals hourly over a week based on factors such as day of the week and previous 7-day arrival patterns. The latter leverages a long short-term memory (LSTM) model, capturing non-linear relationships between past data and a three-day forecasting window. We evaluate the predictive capabilities of the two proposed approaches compared to two na\"ive approaches - a reduced-rank vector autoregressive (VAR) model and the TBATS model. Using patient care demand data from Rambam Medical Center in Israel, our results show that both proposed models effectively capture hourly variations of patient demand. Additionally, the linear model is more explainable thanks to its simple architecture, whereas, by accurately modelling weekly seasonal trends, the LSTM model delivers lower prediction errors. Taken together, our explorations suggest the utility of machine learning in predicting time-varying patient care demand; additionally, it is possible to predict patient care demand with good accuracy (around 4 patients) three days or a week in advance using machine learning.
Multimodal Large Language Model is a Human-Aligned Annotator for Text-to-Image Generation
Apr 23, 2024Recent studies have demonstrated the exceptional potentials of leveraging human preference datasets to refine text-to-image generative models, enhancing the alignment between generated images and textual prompts. Despite these advances, current human preference datasets are either prohibitively expensive to construct or suffer from a lack of diversity in preference dimensions, resulting in limited applicability for instruction tuning in open-source text-to-image generative models and hinder further exploration. To address these challenges and promote the alignment of generative models through instruction tuning, we leverage multimodal large language models to create VisionPrefer, a high-quality and fine-grained preference dataset that captures multiple preference aspects. We aggregate feedback from AI annotators across four aspects: prompt-following, aesthetic, fidelity, and harmlessness to construct VisionPrefer. To validate the effectiveness of VisionPrefer, we train a reward model VP-Score over VisionPrefer to guide the training of text-to-image generative models and the preference prediction accuracy of VP-Score is comparable to human annotators. Furthermore, we use two reinforcement learning methods to supervised fine-tune generative models to evaluate the performance of VisionPrefer, and extensive experimental results demonstrate that VisionPrefer significantly improves text-image alignment in compositional image generation across diverse aspects, e.g., aesthetic, and generalizes better than previous human-preference metrics across various image distributions. Moreover, VisionPrefer indicates that the integration of AI-generated synthetic data as a supervisory signal is a promising avenue for achieving improved alignment with human preferences in vision generative models.
Multi-Head Mixture-of-Experts
Apr 23, 2024Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in training and inference costs, but exhibits the following two issues: (1) Low expert activation, where only a small subset of experts are activated for optimization. (2) Lacking fine-grained analytical capabilities for multiple semantic concepts within individual tokens. We propose Multi-Head Mixture-of-Experts (MH-MoE), which employs a multi-head mechanism to split each token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form. The multi-head mechanism enables the model to collectively attend to information from various representation spaces within different experts, while significantly enhances expert activation, thus deepens context understanding and alleviate overfitting. Moreover, our MH-MoE is straightforward to implement and decouples from other SMoE optimization methods, making it easy to integrate with other SMoE models for enhanced performance. Extensive experimental results across three tasks: English-focused language modeling, Multi-lingual language modeling and Masked multi-modality modeling tasks, demonstrate the effectiveness of MH-MoE.
Mixture of LoRA Experts
Apr 21, 2024LoRA has gained widespread acceptance in the fine-tuning of large pre-trained models to cater to a diverse array of downstream tasks, showcasing notable effectiveness and efficiency, thereby solidifying its position as one of the most prevalent fine-tuning techniques. Due to the modular nature of LoRA's plug-and-play plugins, researchers have delved into the amalgamation of multiple LoRAs to empower models to excel across various downstream tasks. Nonetheless, extant approaches for LoRA fusion grapple with inherent challenges. Direct arithmetic merging may result in the loss of the original pre-trained model's generative capabilities or the distinct identity of LoRAs, thereby yielding suboptimal outcomes. On the other hand, Reference tuning-based fusion exhibits limitations concerning the requisite flexibility for the effective combination of multiple LoRAs. In response to these challenges, this paper introduces the Mixture of LoRA Experts (MoLE) approach, which harnesses hierarchical control and unfettered branch selection. The MoLE approach not only achieves superior LoRA fusion performance in comparison to direct arithmetic merging but also retains the crucial flexibility for combining LoRAs effectively. Extensive experimental evaluations conducted in both the Natural Language Processing (NLP) and Vision & Language (V&L) domains substantiate the efficacy of MoLE.
Near-Field Beam Training: Joint Angle and Range Estimation with DFT Codebook
Sep 21, 2023



Prior works on near-field beam training have mostly assumed dedicated polar-domain codebook and on-grid range estimation, which, however, may suffer long training overhead and degraded estimation accuracy. To address these issues, we propose in this paper new and efficient beam training schemes with off-grid range estimation by using conventional discrete Fourier transform (DFT) codebook. Specifically, we first analyze the received beam pattern at the user when far-field beamforming vectors are used for beam scanning, and show an interesting result that this beam pattern contains useful user angle and range information. Then, we propose two efficient schemes to jointly estimate the user angle and range with the DFT codebook. The first scheme estimates the user angle based on a defined angular support and resolves the user range by leveraging an approximated angular support width, while the second scheme estimates the user range by minimizing a power ratio mean square error (MSE) to improve the range estimation accuracy. Finally, numerical simulations show that our proposed schemes greatly reduce the near-field beam training overhead and improve the range estimation accuracy as compared to various benchmark schemes.
Learned Smartphone ISP on Mobile GPUs with Deep Learning, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022
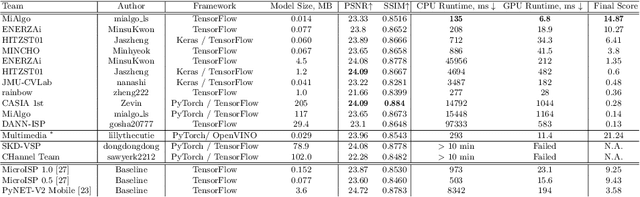
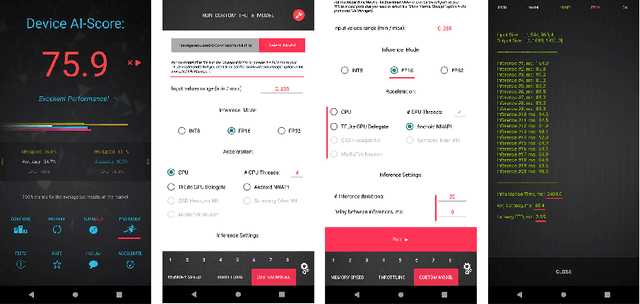
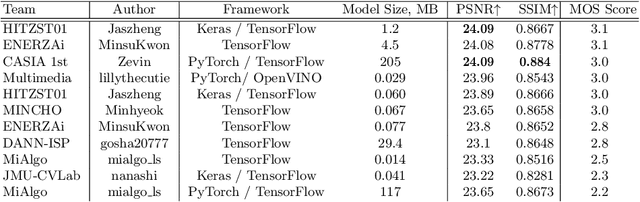
The role of mobile cameras increased dramatically over the past few years, leading to more and more research in automatic image quality enhancement and RAW photo processing. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based image signal processing (ISP) pipeline replacing the standard mobile ISPs that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The runtime of the resulting models was evaluated on the Snapdragon's 8 Gen 1 GPU that provides excellent acceleration results for the majority of common deep learning ops. The proposed solutions are compatible with all recent mobile GPUs, being able to process Full HD photos in less than 20-50 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Fast Near-Field Beam Training for Extremely Large-Scale Array
Sep 29, 2022


In this letter, we study efficient near-field beam training design for the extremely large-scale array (XL-array) communication systems. Compared with the conventional far-field beam training method that searches for the best beam direction only, the near-field beam training is more challenging since it requires a beam search over both the angular and distance domains due to the spherical wavefront propagation model. To reduce the near-field beam-training overhead based on the two-dimensional exhaustive search, we propose in this letter a new two-phase beam training method that decomposes the two-dimensional search into two sequential phases. Specifically, in the first phase, the candidate angles of the user is determined by a new method based on the conventional far-field codebook and angle-domain beam sweeping. Then, a customized polar-domain codebook is employed in the second phase to find the best effective distance of the user given the shortlisted candidate angles. Numerical results show that our proposed two-phase beam training method significantly reduces the training overhead of the exhaustive search and yet achieves comparable beamforming performance for data transmission.
Investigating EEG-Based Functional Connectivity Patterns for Multimodal Emotion Recognition
Apr 04, 2020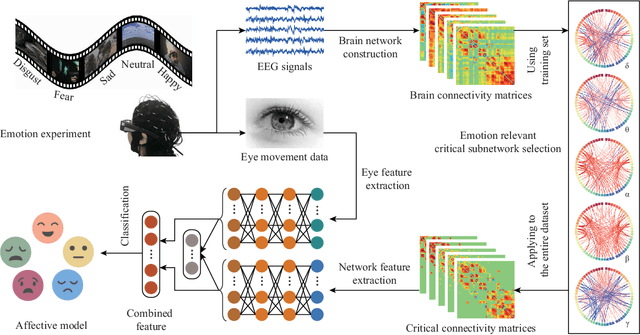
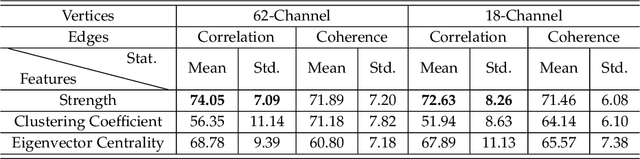
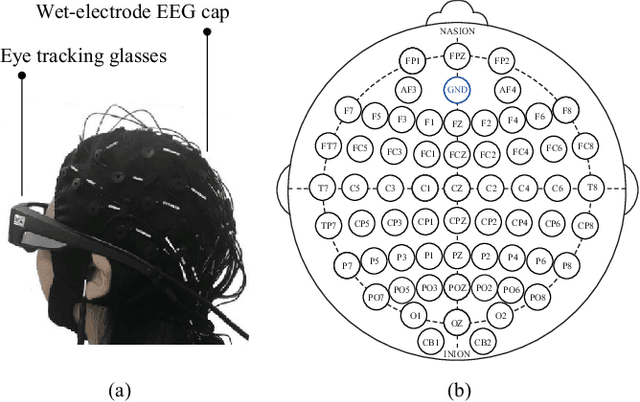
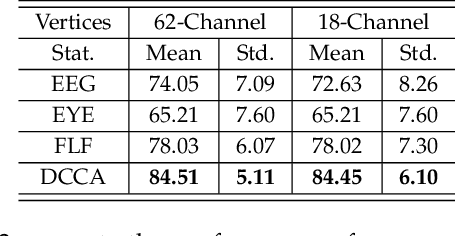
Compared with the rich studies on the motor brain-computer interface (BCI), the recently emerging affective BCI presents distinct challenges since the brain functional connectivity networks involving emotion are not well investigated. Previous studies on emotion recognition based on electroencephalography (EEG) signals mainly rely on single-channel-based feature extraction methods. In this paper, we propose a novel emotion-relevant critical subnetwork selection algorithm and investigate three EEG functional connectivity network features: strength, clustering coefficient, and eigenvector centrality. The discrimination ability of the EEG connectivity features in emotion recognition is evaluated on three public emotion EEG datasets: SEED, SEED-V, and DEAP. The strength feature achieves the best classification performance and outperforms the state-of-the-art differential entropy feature based on single-channel analysis. The experimental results reveal that distinct functional connectivity patterns are exhibited for the five emotions of disgust, fear, sadness, happiness, and neutrality. Furthermore, we construct a multimodal emotion recognition model by combining the functional connectivity features from EEG and the features from eye movements or physiological signals using deep canonical correlation analysis. The classification accuracies of multimodal emotion recognition are 95.08/6.42% on the SEED dataset, 84.51/5.11% on the SEED-V dataset, and 85.34/2.90% and 86.61/3.76% for arousal and valence on the DEAP dataset, respectively. The results demonstrate the complementary representation properties of the EEG connectivity features with eye movement data. In addition, we find that the brain networks constructed with 18 channels achieve comparable performance with that of the 62-channel network in multimodal emotion recognition and enable easier setups for BCI systems in real scenarios.