 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXunyuan Yin
Performance Evaluation of Semi-supervised Learning Frameworks for Multi-Class Weed Detection
Mar 06, 2024

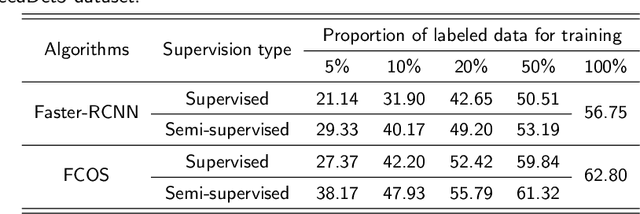

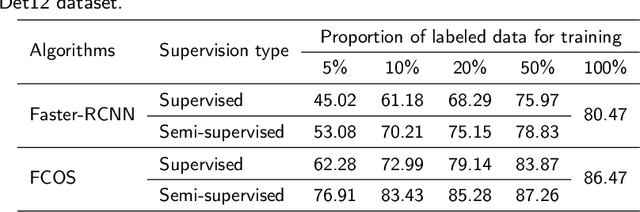
Effective weed control plays a crucial role in optimizing crop yield and enhancing agricultural product quality. However, the reliance on herbicide application not only poses a critical threat to the environment but also promotes the emergence of resistant weeds. Fortunately, recent advances in precision weed management enabled by ML and DL provide a sustainable alternative. Despite great progress, existing algorithms are mainly developed based on supervised learning approaches, which typically demand large-scale datasets with manual-labeled annotations, which is time-consuming and labor-intensive. As such, label-efficient learning methods, especially semi-supervised learning, have gained increased attention in the broader domain of computer vision and have demonstrated promising performance. These methods aim to utilize a small number of labeled data samples along with a great number of unlabeled samples to develop high-performing models comparable to the supervised learning counterpart trained on a large amount of labeled data samples. In this study, we assess the effectiveness of a semi-supervised learning framework for multi-class weed detection, employing two well-known object detection frameworks, namely FCOS and Faster-RCNN. Specifically, we evaluate a generalized student-teacher framework with an improved pseudo-label generation module to produce reliable pseudo-labels for the unlabeled data. To enhance generalization, an ensemble student network is employed to facilitate the training process. Experimental results show that the proposed approach is able to achieve approximately 76\% and 96\% detection accuracy as the supervised methods with only 10\% of labeled data in CottenWeedDet3 and CottonWeedDet12, respectively. We offer access to the source code, contributing a valuable resource for ongoing semi-supervised learning research in weed detection and beyond.
Foundation Models in Smart Agriculture: Basics, Opportunities, and Challenges
Aug 18, 2023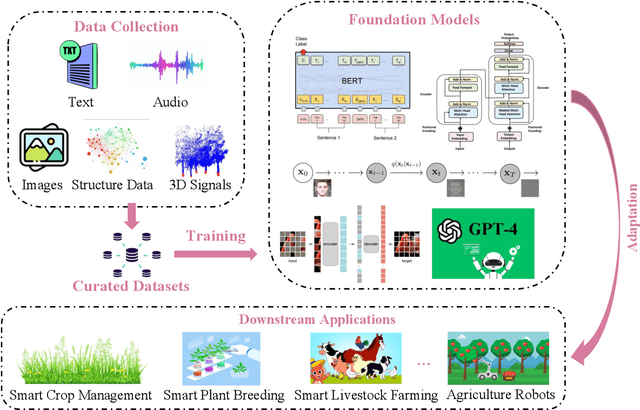


The past decade has witnessed the rapid development of ML and DL methodologies in agricultural systems, showcased by great successes in variety of agricultural applications. However, these conventional ML/DL models have certain limitations: They heavily rely on large, costly-to-acquire labeled datasets for training, require specialized expertise for development and maintenance, and are mostly tailored for specific tasks, thus lacking generalizability. Recently, foundation models have demonstrated remarkable successes in language and vision tasks across various domains. These models are trained on a vast amount of data from multiple domains and modalities. Once trained, they can accomplish versatile tasks with just minor fine-tuning and minimal task-specific labeled data. Despite their proven effectiveness and huge potential, there has been little exploration of applying FMs to agriculture fields. Therefore, this study aims to explore the potential of FMs in the field of smart agriculture. In particular, we present conceptual tools and technical background to facilitate the understanding of the problem space and uncover new research directions in this field. To this end, we first review recent FMs in the general computer science domain and categorize them into four categories: language FMs, vision FMs, multimodal FMs, and reinforcement learning FMs. Subsequently, we outline the process of developing agriculture FMs and discuss their potential applications in smart agriculture. We also discuss the unique challenges associated with developing AFMs, including model training, validation, and deployment. Through this study, we contribute to the advancement of AI in agriculture by introducing AFMs as a promising paradigm that can significantly mitigate the reliance on extensive labeled datasets and enhance the efficiency, effectiveness, and generalization of agricultural AI systems.
Control invariant set enhanced safe reinforcement learning: improved sampling efficiency, guaranteed stability and robustness
May 24, 2023



Reinforcement learning (RL) is an area of significant research interest, and safe RL in particular is attracting attention due to its ability to handle safety-driven constraints that are crucial for real-world applications. This work proposes a novel approach to RL training, called control invariant set (CIS) enhanced RL, which leverages the advantages of utilizing the explicit form of CIS to improve stability guarantees and sampling efficiency. Furthermore, the robustness of the proposed approach is investigated in the presence of uncertainty. The approach consists of two learning stages: offline and online. In the offline stage, CIS is incorporated into the reward design, initial state sampling, and state reset procedures. This incorporation of CIS facilitates improved sampling efficiency during the offline training process. In the online stage, RL is retrained whenever the predicted next step state is outside of the CIS, which serves as a stability criterion, by introducing a Safety Supervisor to examine the safety of the action and make necessary corrections. The stability analysis is conducted for both cases, with and without uncertainty. To evaluate the proposed approach, we apply it to a simulated chemical reactor. The results show a significant improvement in sampling efficiency during offline training and closed-loop stability guarantee in the online implementation, with and without uncertainty.
Control invariant set enhanced reinforcement learning for process control: improved sampling efficiency and guaranteed stability
Apr 11, 2023



Reinforcement learning (RL) is an area of significant research interest, and safe RL in particular is attracting attention due to its ability to handle safety-driven constraints that are crucial for real-world applications of RL algorithms. This work proposes a novel approach to RL training, called control invariant set (CIS) enhanced RL, which leverages the benefits of CIS to improve stability guarantees and sampling efficiency. The approach consists of two learning stages: offline and online. In the offline stage, CIS is incorporated into the reward design, initial state sampling, and state reset procedures. In the online stage, RL is retrained whenever the state is outside of CIS, which serves as a stability criterion. A backup table that utilizes the explicit form of CIS is obtained to ensure the online stability. To evaluate the proposed approach, we apply it to a simulated chemical reactor. The results show a significant improvement in sampling efficiency during offline training and closed-loop stability in the online implementation.