 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXutong Liu
Federated Contextual Cascading Bandits with Asynchronous Communication and Heterogeneous Users
Feb 26, 2024
We study the problem of federated contextual combinatorial cascading bandits, where $|\mathcal{U}|$ agents collaborate under the coordination of a central server to provide tailored recommendations to the $|\mathcal{U}|$ corresponding users. Existing works consider either a synchronous framework, necessitating full agent participation and global synchronization, or assume user homogeneity with identical behaviors. We overcome these limitations by considering (1) federated agents operating in an asynchronous communication paradigm, where no mandatory synchronization is required and all agents communicate independently with the server, (2) heterogeneous user behaviors, where users can be stratified into $J \le |\mathcal{U}|$ latent user clusters, each exhibiting distinct preferences. For this setting, we propose a UCB-type algorithm with delicate communication protocols. Through theoretical analysis, we give sub-linear regret bounds on par with those achieved in the synchronous framework, while incurring only logarithmic communication costs. Empirical evaluation on synthetic and real-world datasets validates our algorithm's superior performance in terms of regrets and communication costs.
Online Clustering of Bandits with Misspecified User Models
Oct 10, 2023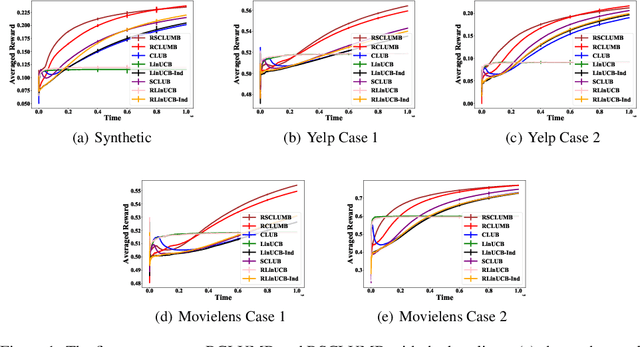
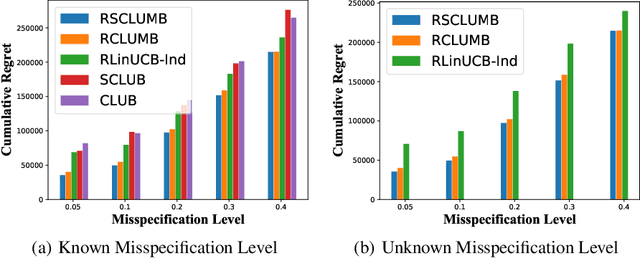
The contextual linear bandit is an important online learning problem where given arm features, a learning agent selects an arm at each round to maximize the cumulative rewards in the long run. A line of works, called the clustering of bandits (CB), utilize the collaborative effect over user preferences and have shown significant improvements over classic linear bandit algorithms. However, existing CB algorithms require well-specified linear user models and can fail when this critical assumption does not hold. Whether robust CB algorithms can be designed for more practical scenarios with misspecified user models remains an open problem. In this paper, we are the first to present the important problem of clustering of bandits with misspecified user models (CBMUM), where the expected rewards in user models can be perturbed away from perfect linear models. We devise two robust CB algorithms, RCLUMB and RSCLUMB (representing the learned clustering structure with dynamic graph and sets, respectively), that can accommodate the inaccurate user preference estimations and erroneous clustering caused by model misspecifications. We prove regret upper bounds of $O(\epsilon_*T\sqrt{md\log T} + d\sqrt{mT}\log T)$ for our algorithms under milder assumptions than previous CB works (notably, we move past a restrictive technical assumption on the distribution of the arms), which match the lower bound asymptotically in $T$ up to logarithmic factors, and also match the state-of-the-art results in several degenerate cases. The techniques in proving the regret caused by misclustering users are quite general and may be of independent interest. Experiments on both synthetic and real-world data show our outperformance over previous algorithms.
Contextual Combinatorial Bandits with Probabilistically Triggered Arms
Mar 30, 2023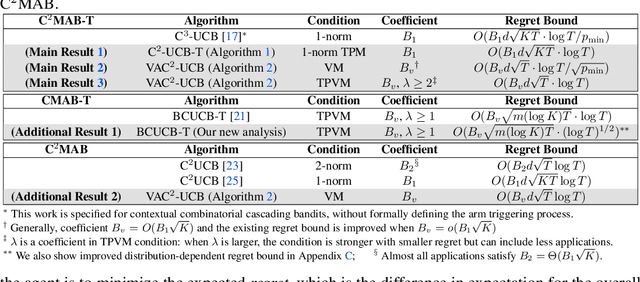
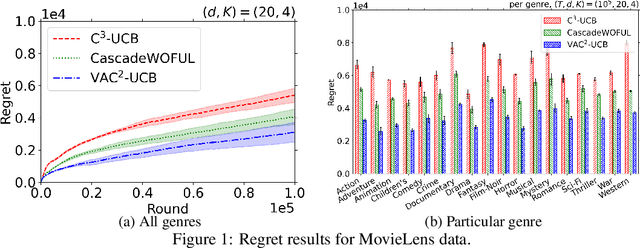

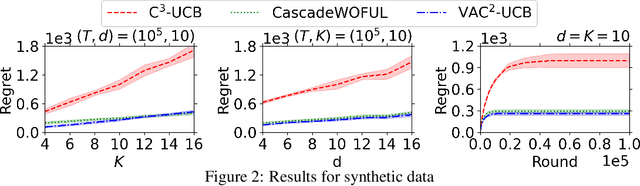
We study contextual combinatorial bandits with probabilistically triggered arms (C$^2$MAB-T) under a variety of smoothness conditions that capture a wide range of applications, such as contextual cascading bandits and contextual influence maximization bandits. Under the triggering probability modulated (TPM) condition, we devise the C$^2$-UCB-T algorithm and propose a novel analysis that achieves an $\tilde{O}(d\sqrt{KT})$ regret bound, removing a potentially exponentially large factor $O(1/p_{\min})$, where $d$ is the dimension of contexts, $p_{\min}$ is the minimum positive probability that any arm can be triggered, and batch-size $K$ is the maximum number of arms that can be triggered per round. Under the variance modulated (VM) or triggering probability and variance modulated (TPVM) conditions, we propose a new variance-adaptive algorithm VAC$^2$-UCB and derive a regret bound $\tilde{O}(d\sqrt{T})$, which is independent of the batch-size $K$. As a valuable by-product, we find our analysis technique and variance-adaptive algorithm can be applied to the CMAB-T and C$^2$MAB~setting, improving existing results there as well. We also include experiments that demonstrate the improved performance of our algorithms compared with benchmark algorithms on synthetic and real-world datasets.
Efficient Explorative Key-term Selection Strategies for Conversational Contextual Bandits
Mar 01, 2023


Conversational contextual bandits elicit user preferences by occasionally querying for explicit feedback on key-terms to accelerate learning. However, there are aspects of existing approaches which limit their performance. First, information gained from key-term-level conversations and arm-level recommendations is not appropriately incorporated to speed up learning. Second, it is important to ask explorative key-terms to quickly elicit the user's potential interests in various domains to accelerate the convergence of user preference estimation, which has never been considered in existing works. To tackle these issues, we first propose ``ConLinUCB", a general framework for conversational bandits with better information incorporation, combining arm-level and key-term-level feedback to estimate user preference in one step at each time. Based on this framework, we further design two bandit algorithms with explorative key-term selection strategies, ConLinUCB-BS and ConLinUCB-MCR. We prove tighter regret upper bounds of our proposed algorithms. Particularly, ConLinUCB-BS achieves a regret bound of $O(\sqrt{dT\log T})$, better than the previous result $O(d\sqrt{T}\log T)$. Extensive experiments on synthetic and real-world data show significant advantages of our algorithms in learning accuracy (up to 54\% improvement) and computational efficiency (up to 72\% improvement), compared to the classic ConUCB algorithm, showing the potential benefit to recommender systems.
On-Demand Communication for Asynchronous Multi-Agent Bandits
Feb 15, 2023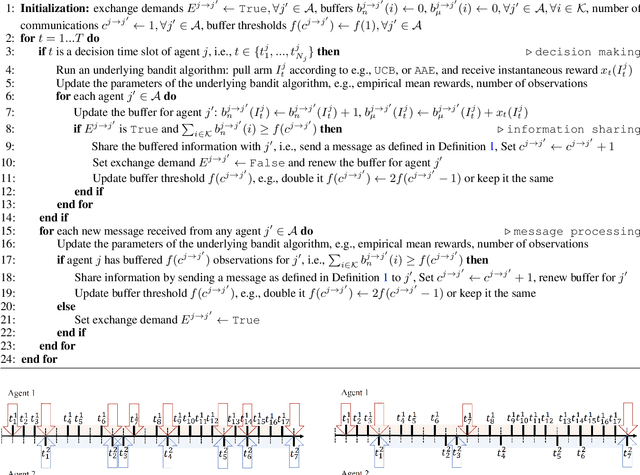


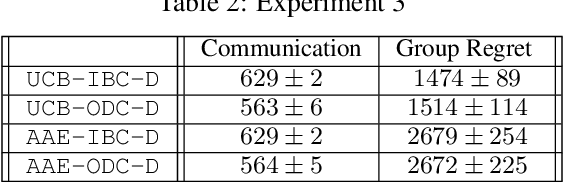
This paper studies a cooperative multi-agent multi-armed stochastic bandit problem where agents operate asynchronously -- agent pull times and rates are unknown, irregular, and heterogeneous -- and face the same instance of a K-armed bandit problem. Agents can share reward information to speed up the learning process at additional communication costs. We propose ODC, an on-demand communication protocol that tailors the communication of each pair of agents based on their empirical pull times. ODC is efficient when the pull times of agents are highly heterogeneous, and its communication complexity depends on the empirical pull times of agents. ODC is a generic protocol that can be integrated into most cooperative bandit algorithms without degrading their performance. We then incorporate ODC into the natural extensions of UCB and AAE algorithms and propose two communication-efficient cooperative algorithms. Our analysis shows that both algorithms are near-optimal in regret.
Federated Online Clustering of Bandits
Aug 31, 2022



Contextual multi-armed bandit (MAB) is an important sequential decision-making problem in recommendation systems. A line of works, called the clustering of bandits (CLUB), utilize the collaborative effect over users and dramatically improve the recommendation quality. Owing to the increasing application scale and public concerns about privacy, there is a growing demand to keep user data decentralized and push bandit learning to the local server side. Existing CLUB algorithms, however, are designed under the centralized setting where data are available at a central server. We focus on studying the federated online clustering of bandit (FCLUB) problem, which aims to minimize the total regret while satisfying privacy and communication considerations. We design a new phase-based scheme for cluster detection and a novel asynchronous communication protocol for cooperative bandit learning for this problem. To protect users' privacy, previous differential privacy (DP) definitions are not very suitable, and we propose a new DP notion that acts on the user cluster level. We provide rigorous proofs to show that our algorithm simultaneously achieves (clustered) DP, sublinear communication complexity and sublinear regret. Finally, experimental evaluations show our superior performance compared with benchmark algorithms.
Batch-Size Independent Regret Bounds for Combinatorial Semi-Bandits with Probabilistically Triggered Arms or Independent Arms
Aug 31, 2022



In this paper, we study the combinatorial semi-bandits (CMAB) and focus on reducing the dependency of the batch-size $K$ in the regret bound, where $K$ is the total number of arms that can be pulled or triggered in each round. First, for the setting of CMAB with probabilistically triggered arms (CMAB-T), we discover a novel (directional) triggering probability and variance modulated (TPVM) condition that can replace the previously-used smoothness condition for various applications, such as cascading bandits, online network exploration and online influence maximization. Under this new condition, we propose a BCUCB-T algorithm with variance-aware confidence intervals and conduct regret analysis which reduces the $O(K)$ factor to $O(\log K)$ or $O(\log^2 K)$ in the regret bound, significantly improving the regret bounds for the above applications. Second, for the setting of non-triggering CMAB with independent arms, we propose a SESCB algorithm which leverages on the non-triggering version of the TPVM condition and completely removes the dependency on $K$ in the leading regret. As a valuable by-product, the regret analysis used in this paper can improve several existing results by a factor of $O(\log K)$. Finally, experimental evaluations show our superior performance compared with benchmark algorithms in different applications.
Multi-layered Network Exploration via Random Walks: From Offline Optimization to Online Learning
Jun 09, 2021



Multi-layered network exploration (MuLaNE) problem is an important problem abstracted from many applications. In MuLaNE, there are multiple network layers where each node has an importance weight and each layer is explored by a random walk. The MuLaNE task is to allocate total random walk budget $B$ into each network layer so that the total weights of the unique nodes visited by random walks are maximized. We systematically study this problem from offline optimization to online learning. For the offline optimization setting where the network structure and node weights are known, we provide greedy based constant-ratio approximation algorithms for overlapping networks, and greedy or dynamic-programming based optimal solutions for non-overlapping networks. For the online learning setting, neither the network structure nor the node weights are known initially. We adapt the combinatorial multi-armed bandit framework and design algorithms to learn random walk related parameters and node weights while optimizing the budget allocation in multiple rounds, and prove that they achieve logarithmic regret bounds. Finally, we conduct experiments on a real-world social network dataset to validate our theoretical results.
Online Competitive Influence Maximization
Jun 24, 2020



Online influence maximization has attracted much attention as a way to maximize influence spread through a social network while learning the values of unknown network parameters. Most previous works focus on single-item diffusion. In this paper, we introduce a new Online Competitive Influence Maximization (OCIM) problem, where two competing items (e.g., products, news stories) propagate in the same network and influence probabilities on edges are unknown. We adapt the combinatorial multi-armed bandit (CMAB) framework for the OCIM problem, but unlike the non-competitive setting, the important monotonicity property (influence spread increases when influence probabilities on edges increase) no longer holds due to the competitive nature of propagation, which brings a significant new challenge to the problem. We prove that the Triggering Probability Modulated (TPM) condition for CMAB still holds, and then utilize the property of competitive diffusion to introduce a new offline oracle, and discuss how to implement this new oracle in various cases. We propose an OCIM-OIFU algorithm with such an oracle that achieves logarithmic regret. We also design an OCIM-ETC algorithm that has worse regret bound but requires less feedback and easier offline computation. Our experimental evaluations demonstrate the effectiveness of our algorithms.
Graphlet Count Estimation via Convolutional Neural Networks
Oct 07, 2018
Graphlets are defined as k-node connected induced subgraph patterns. For an undirected graph, 3-node graphlets include close triangle and open triangle. When k = 4, there are six types of graphlets, e.g., tailed-triangle and clique are two possible 4-node graphlets. The number of each graphlet, called graphlet count, is a signature which characterizes the local network structure of a given graph. Graphlet count plays a prominent role in network analysis of many fields, most notably bioinformatics and social science. However, computing exact graphlet count is inherently difficult and computational expensive because the number of graphlets grows exponentially large as the graph size and/or graphlet size k grow. To deal with this difficulty, many sampling methods were proposed to estimate graphlet count with bounded error. Nevertheless, these methods require large number of samples to be statistically reliable, which is still computationally demanding. Moreover, they have to repeat laborious counting procedure even if a new graph is similar or exactly the same as previous studied graphs. Intuitively, learning from historic graphs can make estimation more accurate and avoid many repetitive counting to reduce computational cost. Based on this idea, we propose a convolutional neural network (CNN) framework and two preprocessing techniques to estimate graphlet count. Extensive experiments on two types of random graphs and real world biochemistry graphs show that our framework can offer substantial speedup on estimating graphlet count of new graphs with high accuracy.