 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYajie Zhao
Don't Look into the Dark: Latent Codes for Pluralistic Image Inpainting
Mar 27, 2024
We present a method for large-mask pluralistic image inpainting based on the generative framework of discrete latent codes. Our method learns latent priors, discretized as tokens, by only performing computations at the visible locations of the image. This is realized by a restrictive partial encoder that predicts the token label for each visible block, a bidirectional transformer that infers the missing labels by only looking at these tokens, and a dedicated synthesis network that couples the tokens with the partial image priors to generate coherent and pluralistic complete image even under extreme mask settings. Experiments on public benchmarks validate our design choices as the proposed method outperforms strong baselines in both visual quality and diversity metrics.
Leveraging Synthetic Data for Generalizable and Fair Facial Action Unit Detection
Mar 15, 2024

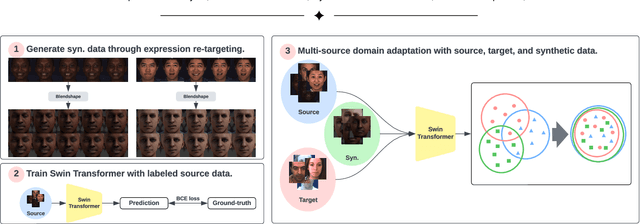
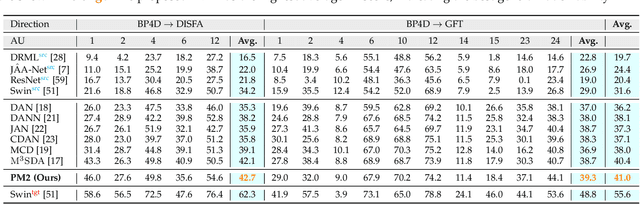
Facial action unit (AU) detection is a fundamental block for objective facial expression analysis. Supervised learning approaches require a large amount of manual labeling which is costly. The limited labeled data are also not diverse in terms of gender which can affect model fairness. In this paper, we propose to use synthetically generated data and multi-source domain adaptation (MSDA) to address the problems of the scarcity of labeled data and the diversity of subjects. Specifically, we propose to generate a diverse dataset through synthetic facial expression re-targeting by transferring the expressions from real faces to synthetic avatars. Then, we use MSDA to transfer the AU detection knowledge from a real dataset and the synthetic dataset to a target dataset. Instead of aligning the overall distributions of different domains, we propose Paired Moment Matching (PM2) to align the features of the paired real and synthetic data with the same facial expression. To further improve gender fairness, PM2 matches the features of the real data with a female and a male synthetic image. Our results indicate that synthetic data and the proposed model improve both AU detection performance and fairness across genders, demonstrating its potential to solve AU detection in-the-wild.
Light Sampling Field and BRDF Representation for Physically-based Neural Rendering
Apr 11, 2023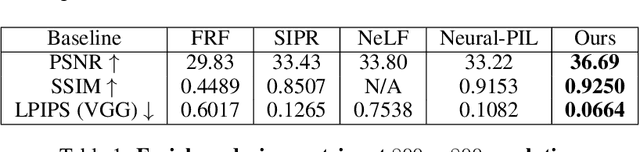

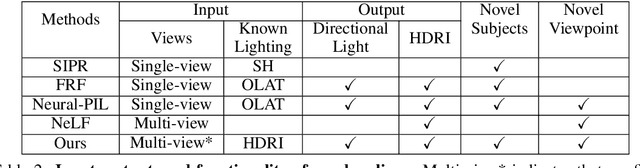
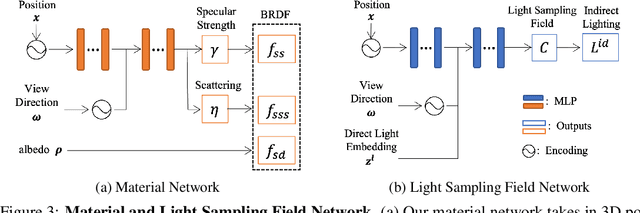
Physically-based rendering (PBR) is key for immersive rendering effects used widely in the industry to showcase detailed realistic scenes from computer graphics assets. A well-known caveat is that producing the same is computationally heavy and relies on complex capture devices. Inspired by the success in quality and efficiency of recent volumetric neural rendering, we want to develop a physically-based neural shader to eliminate device dependency and significantly boost performance. However, no existing lighting and material models in the current neural rendering approaches can accurately represent the comprehensive lighting models and BRDFs properties required by the PBR process. Thus, this paper proposes a novel lighting representation that models direct and indirect light locally through a light sampling strategy in a learned light sampling field. We also propose BRDF models to separately represent surface/subsurface scattering details to enable complex objects such as translucent material (i.e., skin, jade). We then implement our proposed representations with an end-to-end physically-based neural face skin shader, which takes a standard face asset (i.e., geometry, albedo map, and normal map) and an HDRI for illumination as inputs and generates a photo-realistic rendering as output. Extensive experiments showcase the quality and efficiency of our PBR face skin shader, indicating the effectiveness of our proposed lighting and material representations.
Texturize a GAN Using a Single Image
Mar 11, 2023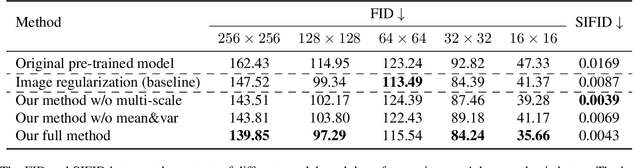
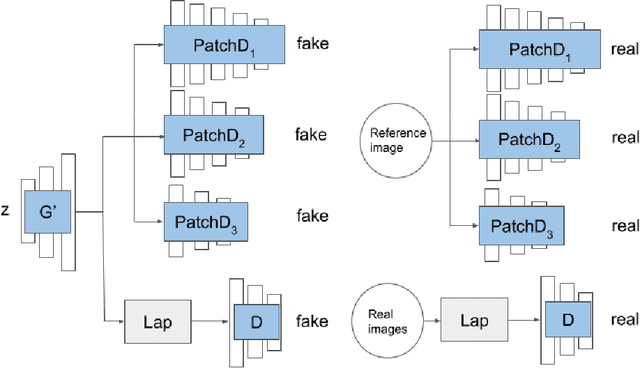


Can we customize a deep generative model which can generate images that can match the texture of some given image? When you see an image of a church, you may wonder if you can get similar pictures for that church. Here we present a method, for adapting GANs with one reference image, and then we can generate images that have similar textures to the given image. Specifically, we modify the weights of the pre-trained GAN model, guided by the reference image given by the user. We use a patch discriminator adversarial loss to encourage the output of the model to match the texture on the given image, also we use a laplacian adversarial loss to ensure diversity and realism, and alleviate the contradiction between the two losses. Experiments show that the proposed method can make the outputs of GANs match the texture of the given image as well as keep diversity and realism.
Exemplar-based Pattern Synthesis with Implicit Periodic Field Network
Apr 15, 2022
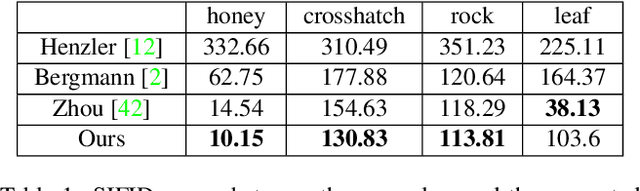
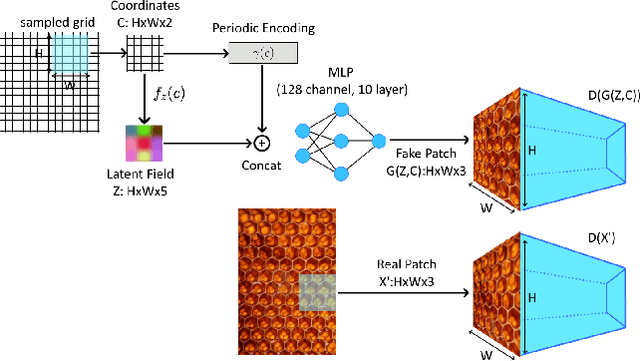
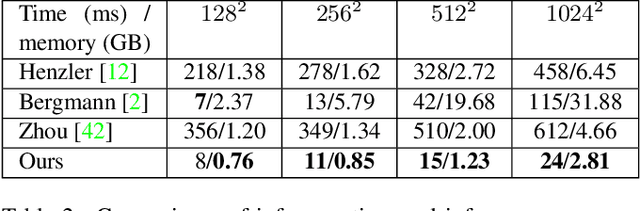
Synthesis of ergodic, stationary visual patterns is widely applicable in texturing, shape modeling, and digital content creation. The wide applicability of this technique thus requires the pattern synthesis approaches to be scalable, diverse, and authentic. In this paper, we propose an exemplar-based visual pattern synthesis framework that aims to model the inner statistics of visual patterns and generate new, versatile patterns that meet the aforementioned requirements. To this end, we propose an implicit network based on generative adversarial network (GAN) and periodic encoding, thus calling our network the Implicit Periodic Field Network (IPFN). The design of IPFN ensures scalability: the implicit formulation directly maps the input coordinates to features, which enables synthesis of arbitrary size and is computationally efficient for 3D shape synthesis. Learning with a periodic encoding scheme encourages diversity: the network is constrained to model the inner statistics of the exemplar based on spatial latent codes in a periodic field. Coupled with continuously designed GAN training procedures, IPFN is shown to synthesize tileable patterns with smooth transitions and local variations. Last but not least, thanks to both the adversarial training technique and the encoded Fourier features, IPFN learns high-frequency functions that produce authentic, high-quality results. To validate our approach, we present novel experimental results on various applications in 2D texture synthesis and 3D shape synthesis.
Exemplar-bsaed Pattern Synthesis with Implicit Periodic Field Network
Apr 04, 2022Synthesis of ergodic, stationary visual patterns is widely applicable in texturing, shape modeling, and digital content creation. The wide applicability of this technique thus requires the pattern synthesis approaches to be scalable, diverse, and authentic. In this paper, we propose an exemplar-based visual pattern synthesis framework that aims to model the inner statistics of visual patterns and generate new, versatile patterns that meet the aforementioned requirements. To this end, we propose an implicit network based on generative adversarial network (GAN) and periodic encoding, thus calling our network the Implicit Periodic Field Network (IPFN). The design of IPFN ensures scalability: the implicit formulation directly maps the input coordinates to features, which enables synthesis of arbitrary size and is computationally efficient for 3D shape synthesis. Learning with a periodic encoding scheme encourages diversity: the network is constrained to model the inner statistics of the exemplar based on spatial latent codes in a periodic field. Coupled with continuously designed GAN training procedures, IPFN is shown to synthesize tileable patterns with smooth transitions and local variations. Last but not least, thanks to both the adversarial training technique and the encoded Fourier features, IPFN learns high-frequency functions that produce authentic, high-quality results. To validate our approach, we present novel experimental results on various applications in 2D texture synthesis and 3D shape synthesis.
DenseGAP: Graph-Structured Dense Correspondence Learning with Anchor Points
Dec 13, 2021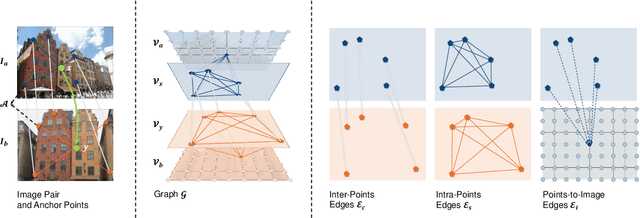
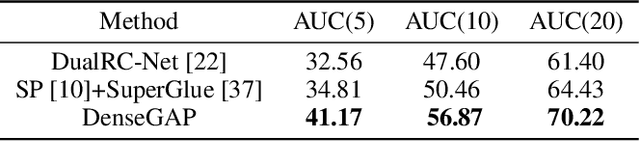

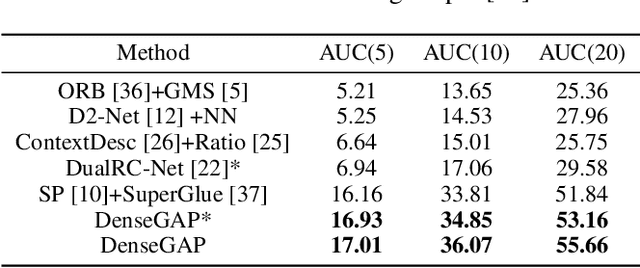
Establishing dense correspondence between two images is a fundamental computer vision problem, which is typically tackled by matching local feature descriptors. However, without global awareness, such local features are often insufficient for disambiguating similar regions. And computing the pairwise feature correlation across images is both computation-expensive and memory-intensive. To make the local features aware of the global context and improve their matching accuracy, we introduce DenseGAP, a new solution for efficient Dense correspondence learning with a Graph-structured neural network conditioned on Anchor Points. Specifically, we first propose a graph structure that utilizes anchor points to provide sparse but reliable prior on inter- and intra-image context and propagates them to all image points via directed edges. We also design a graph-structured network to broadcast multi-level contexts via light-weighted message-passing layers and generate high-resolution feature maps at low memory cost. Finally, based on the predicted feature maps, we introduce a coarse-to-fine framework for accurate correspondence prediction using cycle consistency. Our feature descriptors capture both local and global information, thus enabling a continuous feature field for querying arbitrary points at high resolution. Through comprehensive ablative experiments and evaluations on large-scale indoor and outdoor datasets, we demonstrate that our method advances the state-of-the-art of correspondence learning on most benchmarks.
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
Oct 06, 2021High-fidelity face digitization solutions often combine multi-view stereo (MVS) techniques for 3D reconstruction and a non-rigid registration step to establish dense correspondence across identities and expressions. A common problem is the need for manual clean-up after the MVS step, as 3D scans are typically affected by noise and outliers and contain hairy surface regions that need to be cleaned up by artists. Furthermore, mesh registration tends to fail for extreme facial expressions. Most learning-based methods use an underlying 3D morphable model (3DMM) to ensure robustness, but this limits the output accuracy for extreme facial expressions. In addition, the global bottleneck of regression architectures cannot produce meshes that tightly fit the ground truth surfaces. We propose ToFu, Topologically consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM. Our novel progressive mesh generation network embeds the topological structure of the face in a feature volume, sampled from geometry-aware local features. A coarse-to-fine architecture facilitates dense and accurate facial mesh predictions in a consistent mesh topology. ToFu further captures displacement maps for pore-level geometric details and facilitates high-quality rendering in the form of albedo and specular reflectance maps. These high-quality assets are readily usable by production studios for avatar creation, animation and physically-based skin rendering. We demonstrate state-of-the-art geometric and correspondence accuracy, while only taking 0.385 seconds to compute a mesh with 10K vertices, which is three orders of magnitude faster than traditional techniques. The code and the model are available for research purposes at https://tianyeli.github.io/tofu.
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
Sep 16, 2021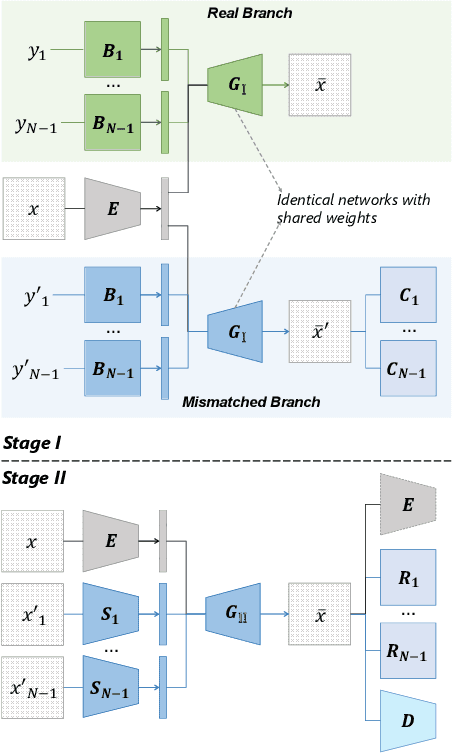
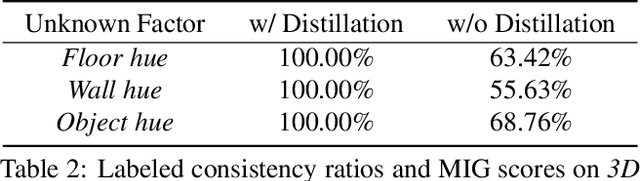
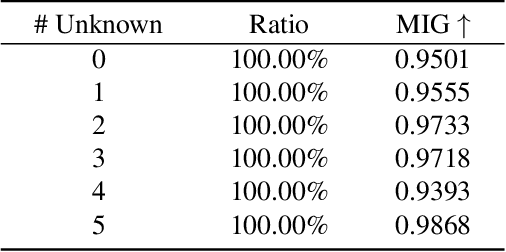

Disentangling data into interpretable and independent factors is critical for controllable generation tasks. With the availability of labeled data, supervision can help enforce the separation of specific factors as expected. However, it is often expensive or even impossible to label every single factor to achieve fully-supervised disentanglement. In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. Under this setting, we propose a flexible weakly-supervised multi-factor disentanglement framework DisUnknown, which Distills Unknown factors for enabling multi-conditional generation regarding both labeled and unknown factors. Specifically, a two-stage training approach is adopted to first disentangle the unknown factor with an effective and robust training method, and then train the final generator with the proper disentanglement of all labeled factors utilizing the unknown distillation. To demonstrate the generalization capacity and scalability of our method, we evaluate it on multiple benchmark datasets qualitatively and quantitatively and further apply it to various real-world applications on complicated datasets.