 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Chen
Microwave photonic short-time Fourier transform based on stabilized period-one nonlinear laser dynamics and stimulated Brillouin scattering
Apr 17, 2024
A microwave photonic short-time Fourier transform (STFT) system based on stabilized period-one (P1) nonlinear laser dynamics and stimulated Brillouin scattering (SBS) is proposed. By using an optoelectronic feedback loop, the frequency-sweep optical signal generated by the P1 nonlinear laser dynamics is stabilized, which is further used in conjunction with an optical bandpass filter implemented by stimulated Brillouin scattering (SBS) to achieve the frequency-to-time mapping of microwave signals and the final STFT. By comparing the experimental results with and without optoelectronic feedback, it is found that the time-frequency diagram of the signal under test (SUT) obtained by STFT is clearer and more regular, and the frequency of the SUT measured in each frequency-sweep period is more accurate. The mean absolute error is reduced by 50% under the optimal filter bandwidth.
Fine-Grained Side Information Guided Dual-Prompts for Zero-Shot Skeleton Action Recognition
Apr 15, 2024Skeleton-based zero-shot action recognition aims to recognize unknown human actions based on the learned priors of the known skeleton-based actions and a semantic descriptor space shared by both known and unknown categories. However, previous works focus on establishing the bridges between the known skeleton representation space and semantic descriptions space at the coarse-grained level for recognizing unknown action categories, ignoring the fine-grained alignment of these two spaces, resulting in suboptimal performance in distinguishing high-similarity action categories. To address these challenges, we propose a novel method via Side information and dual-prompts learning for skeleton-based zero-shot action recognition (STAR) at the fine-grained level. Specifically, 1) we decompose the skeleton into several parts based on its topology structure and introduce the side information concerning multi-part descriptions of human body movements for alignment between the skeleton and the semantic space at the fine-grained level; 2) we design the visual-attribute and semantic-part prompts to improve the intra-class compactness within the skeleton space and inter-class separability within the semantic space, respectively, to distinguish the high-similarity actions. Extensive experiments show that our method achieves state-of-the-art performance in ZSL and GZSL settings on NTU RGB+D, NTU RGB+D 120, and PKU-MMD datasets.
Seamlessly merging radar ranging/imaging, wireless communications, and spectrum sensing, for 6G empowered by microwave photonics
Apr 08, 2024Integration of radar, wireless communications, and spectrum sensing is being investigated for 6G with an increased spectral efficiency. Microwave photonics (MWP), a technique that combines microwave engineering and photonic technology to take advantage of the wide bandwidth offered by photonics for microwave signal generation and processing is considered an effective solution for the implementation of the integration. In this paper, an MWP-assisted joint radar, wireless communications, and spectrum sensing (JRCSS) system that enables precise perception of the surrounding physical and electromagnetic environments while maintaining high-speed data communication is proposed and demonstrated. Communication signals and frequency-sweep signals are merged in the optical domain to achieve high-speed radar ranging and imaging, high-data-rate wireless communications, and wideband spectrum sensing. In an experimental demonstration, a JRCSS system supporting radar ranging with a measurement error within $\pm$ 4 cm, two-dimensional imaging with a resolution of 25 $\times$ 24.7 mm, wireless communications with a data rate of 2 Gbaud, and spectrum sensing with a frequency measurement error within $\pm$ 10 MHz in a 6-GHz bandwidth, is demonstrated.
A multi-stage semi-supervised learning for ankle fracture classification on CT images
Mar 29, 2024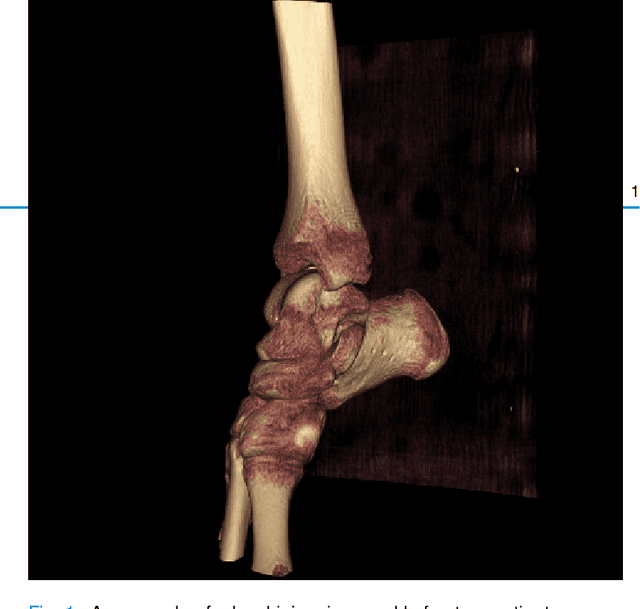
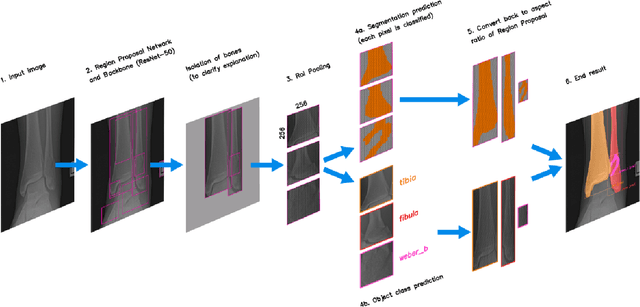
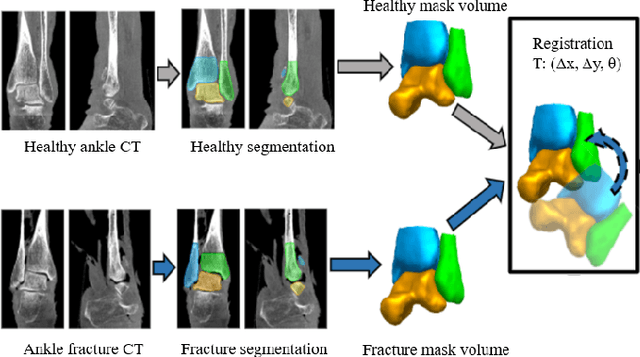
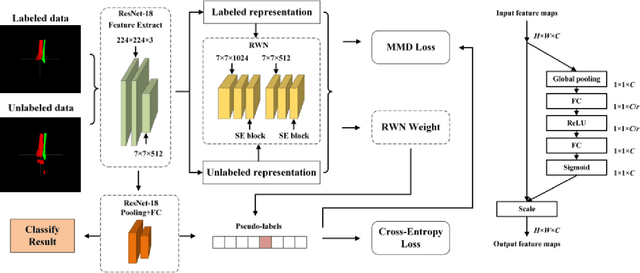
Because of the complicated mechanism of ankle injury, it is very difficult to diagnose ankle fracture in clinic. In order to simplify the process of fracture diagnosis, an automatic diagnosis model of ankle fracture was proposed. Firstly, a tibia-fibula segmentation network is proposed for the joint tibiofibular region of the ankle joint, and the corresponding segmentation dataset is established on the basis of fracture data. Secondly, the image registration method is used to register the bone segmentation mask with the normal bone mask. Finally, a semi-supervised classifier is constructed to make full use of a large number of unlabeled data to classify ankle fractures. Experiments show that the proposed method can segment fractures with fracture lines accurately and has better performance than the general method. At the same time, this method is superior to classification network in several indexes.
VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation
Mar 25, 2024Recent innovations on text-to-3D generation have featured Score Distillation Sampling (SDS), which enables the zero-shot learning of implicit 3D models (NeRF) by directly distilling prior knowledge from 2D diffusion models. However, current SDS-based models still struggle with intricate text prompts and commonly result in distorted 3D models with unrealistic textures or cross-view inconsistency issues. In this work, we introduce a novel Visual Prompt-guided text-to-3D diffusion model (VP3D) that explicitly unleashes the visual appearance knowledge in 2D visual prompt to boost text-to-3D generation. Instead of solely supervising SDS with text prompt, VP3D first capitalizes on 2D diffusion model to generate a high-quality image from input text, which subsequently acts as visual prompt to strengthen SDS optimization with explicit visual appearance. Meanwhile, we couple the SDS optimization with additional differentiable reward function that encourages rendering images of 3D models to better visually align with 2D visual prompt and semantically match with text prompt. Through extensive experiments, we show that the 2D Visual Prompt in our VP3D significantly eases the learning of visual appearance of 3D models and thus leads to higher visual fidelity with more detailed textures. It is also appealing in view that when replacing the self-generating visual prompt with a given reference image, VP3D is able to trigger a new task of stylized text-to-3D generation. Our project page is available at https://vp3d-cvpr24.github.io.
RSTAR: Rotational Streak Artifact Reduction in 4D CBCT using Separable and Circular Convolutions
Mar 25, 2024Four-dimensional cone-beam computed tomography (4D CBCT) provides respiration-resolved images and can be used for image-guided radiation therapy. However, the ability to reveal respiratory motion comes at the cost of image artifacts. As raw projection data are sorted into multiple respiratory phases, there is a limited number of cone-beam projections available for image reconstruction. Consequently, the 4D CBCT images are covered by severe streak artifacts. Although several deep learning-based methods have been proposed to address this issue, most algorithms employ ordinary network models, neglecting the intrinsic structural prior within 4D CBCT images. In this paper, we first explore the origin and appearance of streak artifacts in 4D CBCT images.Specifically, we find that streak artifacts exhibit a periodic rotational motion along with the patient's respiration. This unique motion pattern inspires us to distinguish the artifacts from the desired anatomical structures in the spatiotemporal domain. Thereafter, we propose a spatiotemporal neural network named RSTAR-Net with separable and circular convolutions for Rotational Streak Artifact Reduction. The specially designed model effectively encodes dynamic image features, facilitating the recovery of 4D CBCT images. Moreover, RSTAR-Net is also lightweight and computationally efficient. Extensive experiments substantiate the effectiveness of our proposed method, and RSTAR-Net shows superior performance to comparison methods.
SynerMix: Synergistic Mixup Solution for Enhanced Intra-Class Cohesion and Inter-Class Separability in Image Classification
Mar 24, 2024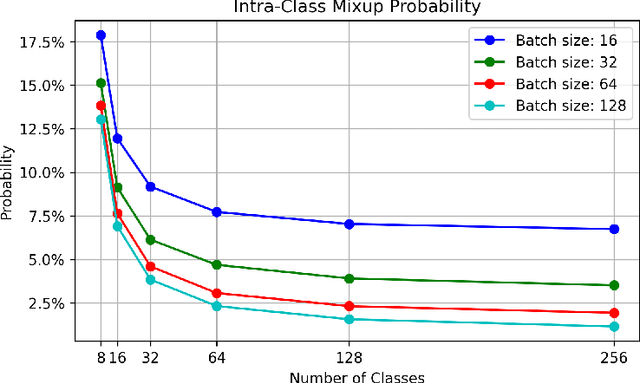

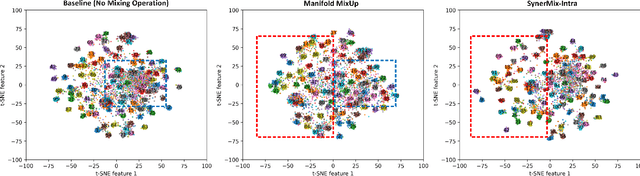
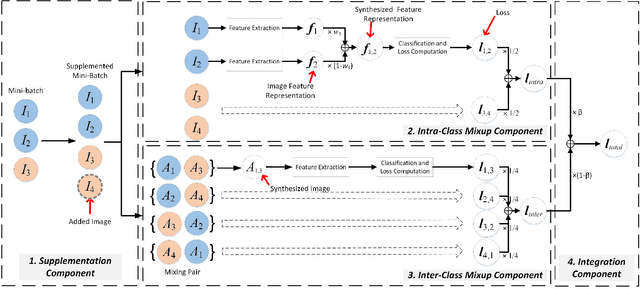
To address the issues of MixUp and its variants (e.g., Manifold MixUp) in image classification tasks-namely, their neglect of mixing within the same class (intra-class mixup) and their inadequacy in enhancing intra-class cohesion through their mixing operations-we propose a novel mixup method named SynerMix-Intra and, building upon this, introduce a synergistic mixup solution named SynerMix. SynerMix-Intra specifically targets intra-class mixup to bolster intra-class cohesion, a feature not addressed by current mixup methods. For each mini-batch, it leverages feature representations of unaugmented original images from each class to generate a synthesized feature representation through random linear interpolation. All synthesized representations are then fed into the classification and loss layers to calculate an average classification loss that significantly enhances intra-class cohesion. Furthermore, SynerMix combines SynerMix-Intra with an existing mixup approach (e.g., MixUp, Manifold MixUp), which primarily focuses on inter-class mixup and has the benefit of enhancing inter-class separability. In doing so, it integrates both inter- and intra-class mixup in a balanced way while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six datasets show that SynerMix achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or SynerMix-Intra alone, averaging a 1.16% gain. It also surpasses the top-performer of either Manifold MixUp or SynerMix-Intra by 0.12% to 5.16%, with an average gain of 1.11%. Given that SynerMix is model-agnostic, it holds significant potential for application in other domains where mixup methods have shown promise, such as speech and text classification. Our code is publicly available at: https://github.com/wxitxy/synermix.git.
Improving Image Classification Accuracy through Complementary Intra-Class and Inter-Class Mixup
Mar 21, 2024MixUp and its variants, such as Manifold MixUp, have two key limitations in image classification tasks. First, they often neglect mixing within the same class (intra-class mixup), leading to an underutilization of the relationships among samples within the same class. Second, although these methods effectively enhance inter-class separability by mixing between different classes (inter-class mixup), they fall short in improving intra-class cohesion through their mixing operations, limiting their classification performance. To tackle these issues, we propose a novel mixup method and a comprehensive integrated solution.Our mixup approach specifically targets intra-class mixup, an aspect commonly overlooked, to strengthen intra-class cohesion-a feature not provided by current mixup techniques.For each mini-batch, our method utilizes feature representations of unaugmented original images from each class within the mini-batch to generate a single synthesized feature representation through random linear interpolation. All synthesized representations for this mini-batch are then fed into the classification and loss layers to calculate an average classification loss that can markedly enhance intra-class cohesion. Moreover, our integrated solution seamlessly combines our intra-class mixup method with an existing mixup approach such as MixUp or Manifold MixUp. This comprehensive solution incorporates inter- and intra-class mixup in a balanced manner while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six public datasets demonstrate that our integrated solution achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or our intra-class mixup method, averaging a 1.16% gain. It also outperforms the better performer of either Manifold MixUp or our intra-class mixup method by 0.12% to 5.16%, with an average gain of 1.11%.
SEMRes-DDPM: Residual Network Based Diffusion Modelling Applied to Imbalanced Data
Mar 12, 2024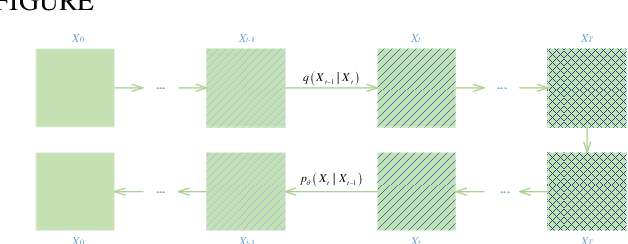
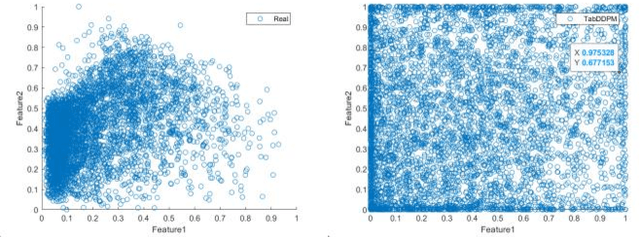
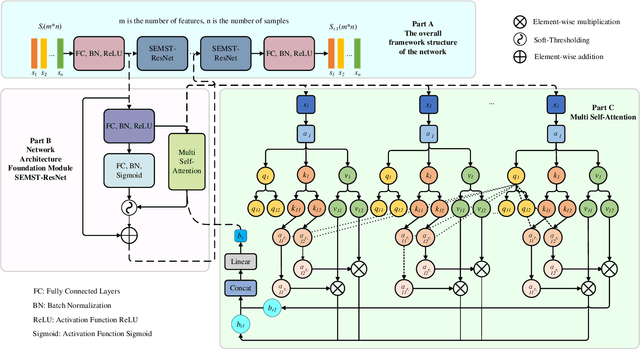
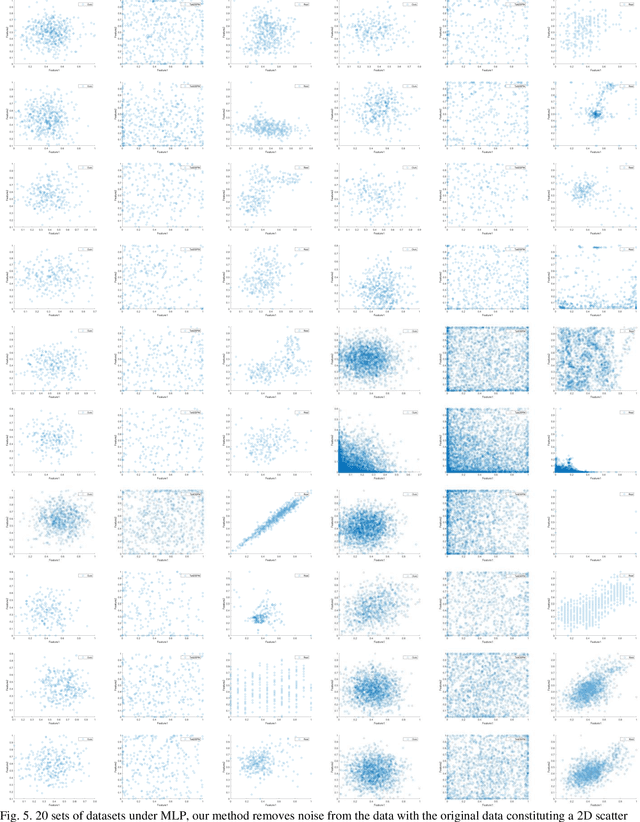
In the field of data mining and machine learning, commonly used classification models cannot effectively learn in unbalanced data. In order to balance the data distribution before model training, oversampling methods are often used to generate data for a small number of classes to solve the problem of classifying unbalanced data. Most of the classical oversampling methods are based on the SMOTE technique, which only focuses on the local information of the data, and therefore the generated data may have the problem of not being realistic enough. In the current oversampling methods based on generative networks, the methods based on GANs can capture the true distribution of data, but there is the problem of pattern collapse and training instability in training; in the oversampling methods based on denoising diffusion probability models, the neural network of the inverse diffusion process using the U-Net is not applicable to tabular data, and although the MLP can be used to replace the U-Net, the problem exists due to the simplicity of the structure and the poor effect of removing noise. problem of poor noise removal. In order to overcome the above problems, we propose a novel oversampling method SEMRes-DDPM.In the SEMRes-DDPM backward diffusion process, a new neural network structure SEMST-ResNet is used, which is suitable for tabular data and has good noise removal effect, and it can generate tabular data with higher quality. Experiments show that the SEMResNet network removes noise better than MLP; SEMRes-DDPM generates data distributions that are closer to the real data distributions than TabDDPM with CWGAN-GP; on 20 real unbalanced tabular datasets with 9 classification models, SEMRes-DDPM improves the quality of the generated tabular data in terms of three evaluation metrics (F1, G-mean, AUC) with better classification performance than other SOTA oversampling methods.
FFAD: A Novel Metric for Assessing Generated Time Series Data Utilizing Fourier Transform and Auto-encoder
Mar 11, 2024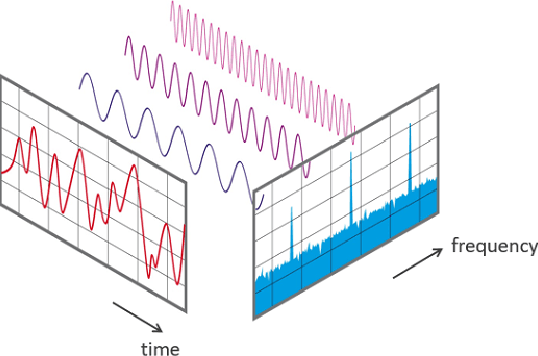
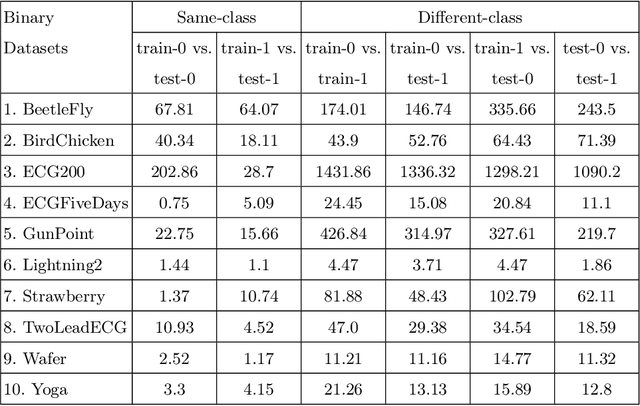
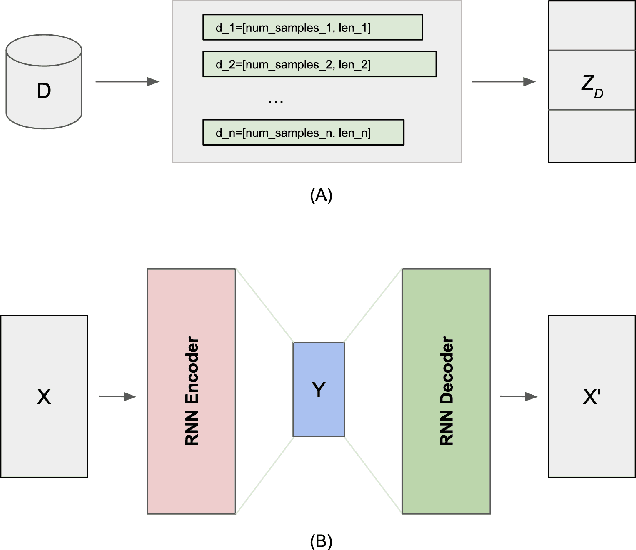
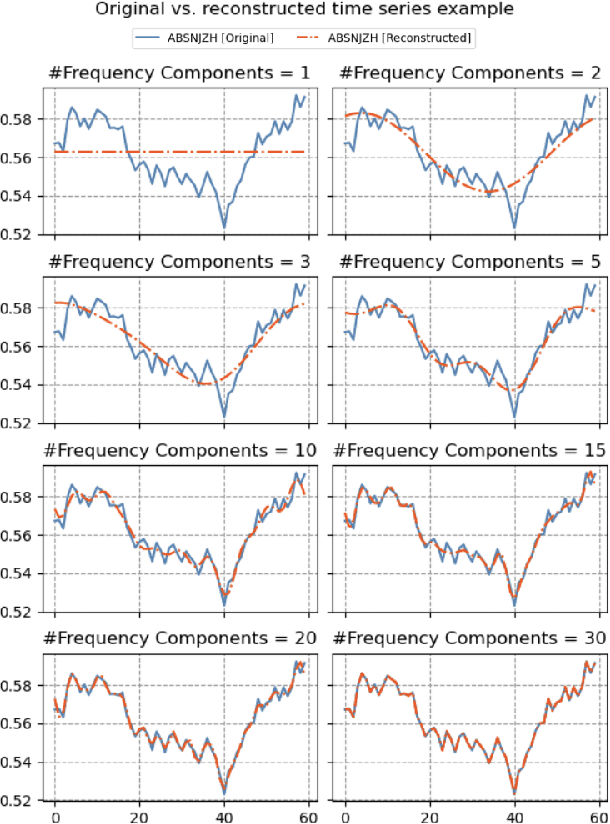
The success of deep learning-based generative models in producing realistic images, videos, and audios has led to a crucial consideration: how to effectively assess the quality of synthetic samples. While the Fr\'{e}chet Inception Distance (FID) serves as the standard metric for evaluating generative models in image synthesis, a comparable metric for time series data is notably absent. This gap in assessment capabilities stems from the absence of a widely accepted feature vector extractor pre-trained on benchmark time series datasets. In addressing these challenges related to assessing the quality of time series, particularly in the context of Fr\'echet Distance, this work proposes a novel solution leveraging the Fourier transform and Auto-encoder, termed the Fr\'{e}chet Fourier-transform Auto-encoder Distance (FFAD). Through our experimental results, we showcase the potential of FFAD for effectively distinguishing samples from different classes. This novel metric emerges as a fundamental tool for the evaluation of generative time series data, contributing to the ongoing efforts of enhancing assessment methodologies in the realm of deep learning-based generative models.